什么是redis?
Redis 是互联网技术领域使用最为广泛的存储中间件,它是「Remote Dictionary Service」的首字母缩写,也就是「远程字典服务」。Redis 以其超高的性能、完美的文档、简洁易懂的源码和丰富的客户端库支持在开源中间件领域广受好评。国内外很多大型互联网公司都在使用 Redis,比如 Twitter、YouPorn、暴雪娱乐、Github、StackOverflow、腾讯、阿里、京东、华为、新浪微博等等,很多中小型公司也都有应用。也可以说,对 Redis 的了解和应用实践已成为当下中高级后端开发者绕不开的必备技能。
Redis 可以做什么
- 记录帖子的点赞数、评论数和点击数 (hash)。
- 记录用户的帖子 ID 列表 (排序),便于快速显示用户的帖子列表 (zset)。
- 记录帖子的标题、摘要、作者和封面信息,用于列表页展示 (hash)。
- 记录帖子的点赞用户 ID 列表,评论 ID 列表,用于显示和去重计数 (zset)。
- 缓存近期热帖内容 (帖子内容空间占用比较大),减少数据库压力 (hash)。
- 记录帖子的相关文章 ID,根据内容推荐相关帖子 (list)。
- 如果帖子 ID 是整数自增的,可以使用 Redis 来分配帖子 ID(计数器)。
- 收藏集和帖子之间的关系 (zset)。
- 记录热榜帖子 ID 列表,总热榜和分类热榜 (zset)。
- 缓存用户行为历史,进行恶意行为过滤 (zset,hash)。
- .........等等
redis 基础数据结构及相关应用介绍
关于基础数据结构也可以看我之前的文章《换一种存储方式,居然能节约这么多内存?》。
string
实现方式:
动态字符串;内部结构类似java 的ArrayList;采用与预分配冗余空间的方式来减少内存的频繁分配。 当字符长度<1M,扩容时加倍现有空间 当字符串>1M,扩容每次加1M,字符串最大长度为512M 字符串由多个字节组成,每个字节又由8个bit组成,一个字符串看做bit 组合,这便是bitmap(位图)数据结构。
命令
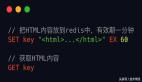
- set key;get key
list
实现方式:
链表实现类似java 里面的LinkList。
在数据量少的情况下,使用的是快速列表,数据较少的情况下是用一块连续的内存,ziplist 数据结构。
数据多的时候使用linkedlist,链表结合ziplist,这样的优点:既满足了快速的插入删除的性能,又不会出现太大的空间冗余。
经典应用:
异步队列 需要注意的是 lindex 是慢操作时间复杂度O(n),慎用。
队列空了可能造成 cpu空转,qps也可能被拉高。可以采用阻塞读:blpop/brpop
命令
- rpush rpop
hash
类似java 里面的HashMap,数组+链表的二维结构。在数据量少的时候是ziplist。
和HashMap对比:redis key只能是字符串,而且rehash 方式不同。
set
类似java HashSet。
应用场景:
保存中奖用户的id,有去重功能
命令
- sadd
- smembers key 获取所有的key
- sismember key setv 相当于contains(s)
- scard key 返回key 的数量
- spop keys:Redis Spop 命令用于移除集合中的指定 key 的一个或多个随机元素。
zset
类似java SortedSet 和HashMap 结合体;concurrentskipmap
内部实现 “跳跃链表”的数据结构。数据少的时候使用ziplist。数据多的时候用skiplist.
注意:关于过期时间,以对象为单位,如果设置了过期时间,然后调用set 修改了对象,过期时间会消失。
经典应用
- 粉丝列表:value ID, score 关注时间
- 分布式锁:
redis2.8 加入了set指令的扩展参数,使得 setnx 和 expire 指令可以一起执行 。
jredis 命令:
- StringUtils.equals("OK", redis.set("seemoonup", "false", "NX", "EX", 5))
这个命令的完整意思就是 如果“seemoonup“这个key不存在设置为”false“并且设置过期时间5秒,该实现缺点:没有ack(消息确认机制) 保证。
位图
最小单位bit(比特)只能是0,1
bitfield
有三个子指令,分别是 get/set/incrby,它们都可以对指定位片段进行读写,但是最多只能处理 64 个连续的位,如果 超过 64 位,就得使用多个子指令,bitfield 可以一次执行多个子指令
bitmap
- setbit
- bitcount
redis 高级一些的应用
HyperLogLog
这是一种高级数据结构,提供不准确的去重计数方案,误差率在0.81%。
应用场景
高访问量页面的UV, 不适合单用户的存储。
实现方式:
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。为什么是12k?
实现是16384个桶,也就是2的14次方,每个桶的maxbtis需要6个字节存储,也就是 2的14次方*6/8=12k
布隆过滤器(bloom filter)
优点:
在去重的同时,还能节省90%的空间。
注意:
有误判率,判断没有,肯定没有;有,很可能有。只会误判那些没有见过的,误判率可以通过参数来调整。
原理:
位图+hash表,一个大型数组(位图)+几个无偏的haash函数,位图越稀疏,正确率越高。
redis4.0 以后才有;我们平时用到的 HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库的 IO请求数量。当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询
hbase、cassandra levelDB RocksDB 都有布隆过滤器结构
Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现 。
简单限流
使用zset 实现。
运用原理:
zset;key=用户+行为,vaule=时间戳,score=时间戳
使用 pipline :一次发多条命令,
Zremrangebyscore 命令用于移除有序集中,指定分数(score)区间内的所有成员
zremrangebyscore(key,0,时间窗口*1000)
缺点:
量大不适合,会占用大量存储空间,比如限定60s 内操作不能超过100万次。
漏斗限流
redis 4.0 提供了一个限流模块,Redis-Cell,该模块使用了漏斗算法
该模块是用Rust 语言写的
Redis 是用C 写的
该模块只有1条指令
- cl.throttle
重试时间都帮你算好
例如:key 每60s 只能回复30次
- cl.throttle key 15 30 60 1
附近的人GeoHash
这是Redis 在3.2版本以后增加了Geo模块。
原理:
在redis 里面,经纬度使用52位整数进行编码,放zset 里面;zset value 是key,score 是GeoHash 的52位整数值,
命令
- geoadd company 116.481 39.996 xiaomi
算两点之间的距离
- geodis company juejin xiaomi km
获取元素位置
- geopos conpany xiaomi
获取元素hash 值
- geohash company xiaomi
附近的公司
- georadiusbymember company xiaomi 20 km count 3
范围20km 以内最多3个元素 按距离正排,不会排除自身
- georadius company 116.514 39.9 20 km withdis count 3 asc
注意:
集群环境中单个key对应的数据不要超过1M,否则导致集群迁移出现卡顿现象。建议Geo的数据库使用单独Redis 实例部署,如果数据量过亿,甚至更大,需要进行拆分,可以按国家、省市区拆分,降低单个zset 集合的大小。
redis大海捞针-key的遍历
keys
没有 offset limit 参数
keys 算法是遍历,时间复杂度为O(n) 如果实例中有千万级以上的key,keys 指令会造成卡顿。
redis 是单线程数据
redis 2.8 版本中加入了scan
scan 优点
复杂度虽然也是O(n) 但它是通过游标分步进行的,不会阻塞 线程。
提供limit 参数,控制每次返回结果的最大条数
和keys 一样,也有模式匹配功能
服务器不需要为游标保存状态
注意
返回的结果可能会有重复,需要客户端去重
遍历过程中如果数据有修改,可能返回不正确的数据
单次结果返回为空并不意味着遍历结束,要看返回的游标值是否为0
limit 不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于)
- scan 0 match key99* count 10
字典的结构
Redis 中所有的key 都存在一个很大的字典中
数据结构 类似java HashMap
数据结构
一维数组+二维链表
第一维 数组大小总是2的N次方,扩容一次,大小空间加倍,2的N+1 次方
scan 指令返回的就是 第一维数组的位置索引,这个就是槽(slot)
scan 返回之所以是空的,因为有些槽是空的
scan 遍历
高位进位加减法 来遍历
考虑到字典扩缩容时 避免槽位的重复和遗漏
从左边开始加 和普通加法相反
采用【高位进位加减法】 rehash 后的槽位 在遍历顺序上是相邻的
渐进式的 rehash
扩容
同时保存新旧数组
定时任务后续对hash 的指令操作 将旧数组挂接的元素迁移到新数组上
scan 也是同时扫面新旧槽位,将结果融合后返回客户端
大key 扫描
大key 的缺点
扩容和回收 占用内存大 造成卡顿
scan 来判读key 的大小 太麻烦
redis-cli 指令中提供了扫描功能
- redis-cli -h 127.0.0.1 -p 7001 --bigkeys
防止大幅度抬升 redis 的ops 导致报警,可以加一个修改参数
- redis-cli -h 127.0.0.1 -p 7001 --bigkeys -i 0.1