












一 形形色色的监控系统
监控一直是IT系统中的核心组成部分,负责问题的发现以及辅助性的定位。无论是传统运维、SRE、DevOps、开发者都需要关注监控系统并参与到监控系统的建设和优化。从最开始大型机的作业系统、Linux基础指标,监控系统就已经开始出现并逐渐演进,现阶段能够搜索到的监控系统不下于上百种,按照不同类别也有非常多的划分方式,例如:
监控对象:通用型(通用的监控方式,适应于大部分的监控对象),专一型(为某一功能定制,例如Java的JMX系统、CPU的高温保护、硬盘的断电保护、UPS切换系统、交换机监控系统、专线监控等);
数据获取方式:Push(CollectD、Zabbix、InfluxDB);Pull(Prometheus、SNMP、JMX);
部署方式:耦合式(和被监控系统在一起部署);单机(单机单实例部署);分布式(可以横向扩展);SaaS化(很多商业的公司提供SaaS的方式,无需部署);
数据获取方式:接口型(只能通过某些API拿去);DSL(可以有一些计算,例如PromQL、GraphQL);SQL(标准SQL、类SQL);
商业属性:开源免费(例如Prometheus、InfluxDB单机版);开源商业型(例如InfluxDB集群版、Elastic Search X-Pack);闭源商业型(例如DataDog、Splunk、AWS Cloud Watch);
二 Pull or Push
对于建设一套公司内部使用的监控系统平台,相对来说可选的方案还是非常多的,无论是用开源方案自建还是使用商业的SaaS化产品,都有比较多的可选项。但无论是开源方案还是商业的SaaS产品,真正实施起来都需要考虑如何将数据给到监控平台,或者说监控平台如何获取到这些数据。这里就涉及到数据获取方式的选型:Pull(拉)还是Push(推)模式?
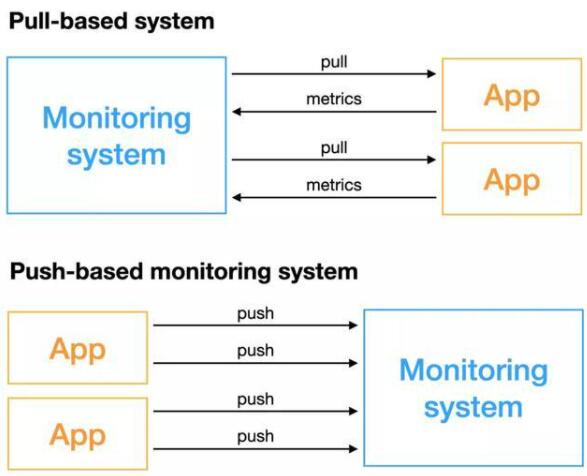
基于Pull类型的监控系统顾名思义是由监控系统主动去获取指标,需要被监控的对象能够具备被远端访问的能力;基于Push类型的监控系统不主动获取数据,而是由监控对象主动推送指标。两种方式在非常多的地方都有区别,对于监控系统的建设和选型来说,一定要事先了解这两种方式各自的优劣,选择合适的方案来实施,否则如果盲目实施,后续对监控系统的稳定性和部署运维代价来说将是灾难性的。
三 Pull vs Push概览
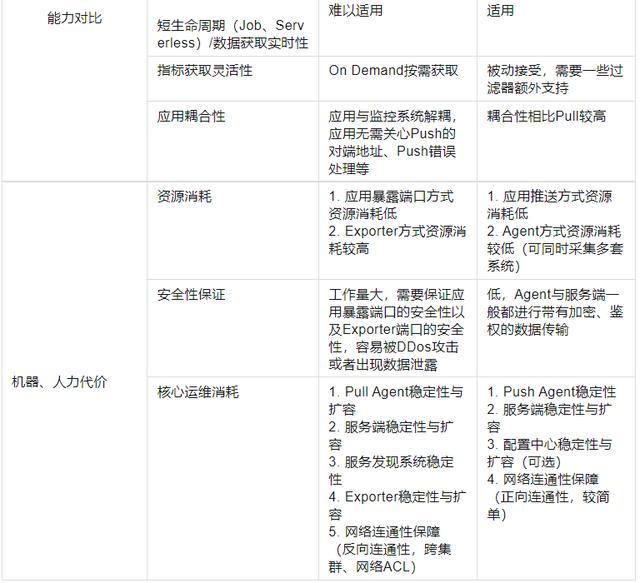
下面将从几个方面来展开介绍,为了节约读者时间,这里先用一个表格来做概要性的论述,细节在后面会展开:
四 原理与架构对比
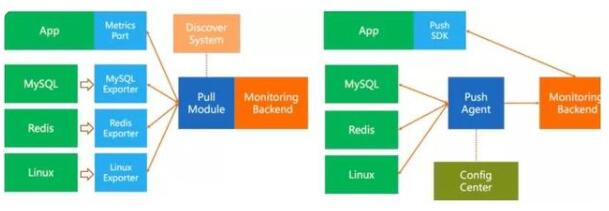
如上图所示,Pull模型数据获取的核心是Pull模块,一般和监控的后端一起部署,例如Prometheus,核心组成包括:
服务发现系统,包括主机的服务发现(一般依赖于公司内部自己的CMDB系统)、应用服务发现(例如Consul)、PaaS服务发现(例如Kubernetes);Pull模块需要具备对这些服务发现系统的对接能力
Pull核心模块,除了服务发现部分外,一般使用通用协议去远端拉取数据,一般支持配置拉取间隔、超时间隔、指标过滤/Rename/简单的Process能力
应用侧SDK,支持监听某个固定端口来提供被Pull的能力
由于各类中间件/其他系统不兼容Pull协议,因此需要开发对应的Exporter的Agent,支持拉取这些系统的指标并提供标准的Pull接口
Push模型相对比较简单:
Push Agent,支持拉取各类被监控对象的指标数据,并推送到服务端,可以和被监控系统耦合部署,也可以单独部署
ConfigCenter(可选),用来提供中心化的动态配置能力,例如监控目标、采集间隔、指标过滤、指标处理、远端目标等
应用侧SDK,支持发送数据到监控后端,或者发送到本地Agent(通常是本地Agent也实现一套后端的接口)
小结:纯粹从部署复杂性上而言,在中间件/其他系统的监控上,Pull模型的部署方式太过复杂,维护代价较高,使用Push模式较为便捷;应用提供Metrics端口或主动Push部署代价相差不大。
五 Pull的分布式解决方案
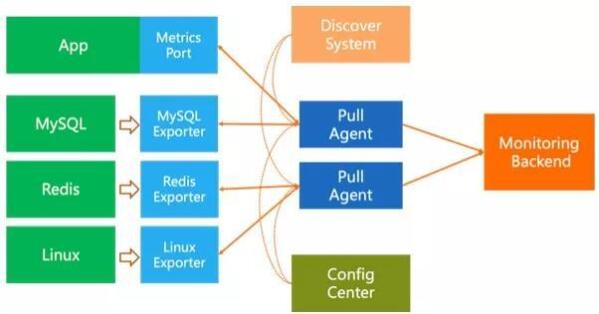
在扩展性上,Push方式的数据采集天然就是分布式的,在监控后端能力可以跟上的时候,可以无限的横向扩展。相比之下Pull方式扩展较为麻烦,需要:
Pull模块与监控后端解耦,Pull作为Agent单独部署
Pull Agent需要做分布式的协同,一般最简单是做Sharding,例如从服务发现系统处获取被监控的机器列表,对这些机器进行Hash后取模Sharding来决定由哪个Agent来负责Pull。
新增一个配置中心(可选)用来管理各个PullAgent
相信反应快的同学已经看出来,这种分布式的方式还是有一些问题:
单点瓶颈还是存在,所有的Agent都需要去请求服务发现模块
Agent扩容后,监控目标会变化,容易产生数据重复或缺失
六 监控能力对比
1 监控目标存活性
存活性是监控所需要做的第一件也是最基础的工作,Pull模式监控目标存活性相对来说非常简单,直接在Pull的中心端就知道能否请求到目标端的指标,如果失败也能知道一些简单的错误,比如网络超时、对端拒绝连接等。
Push方式相对来说就比较麻烦,应用没有上报可能是应用挂了,也可能是网络问题,也可能是迁移到了其他的节点上了,因为Pull模块可以和服务发现实时联动,但Push没有,所以只有服务端再和服务发现交互才能知道具体失败的原因。
2 数据齐全度计算
数据齐全度这个概念在大型的监控系统中还是非常重要的,比如监控一千个副本的交易应用的QPS,这个指标需要结合一千个数据进行叠加,如果没有数据齐全度的概念,若配置QPS相比降低2%告警,由于网络波动,超过20个副本上报的数据延迟几秒,那就会触发误报。因此在配置告警的时候还需要结合数据齐全度数据进行综合考虑。
数据齐全度的计算也一样是依赖于服务发现模块,Pull方式是按照一轮一轮的方式进行拉取,所以一轮拉取完毕后数据就是齐全的,即使部分拉取失败也知道数据不全的百分比是多少;
而Push方式由每个Agent、应用主动Push,每个客户端的Push间隔、网络延迟都不一样,需要服务端去根据历史情况计算数据齐全度,相对代价比较大。
3 短生命周期/Serverless应用监控
在实际场景中,短生命周期/Serverless的应用也有很多,尤其是对成本友好的情况下,我们会大量使用Job、弹性实例、无服务应用等,例如渲染型的任务到达后启动一个弹性的计算实例,执行完毕后立马销毁释放;机器学习的训练Job、事件驱动的无服务工作流、定期执行的Job(例如资源清理、容量检查、安全扫描)等。这些应用通常生命周期极短(可能在秒级或毫秒级),Pull的定期模型极难去监控,一般都需要使用Push的方式,由应用主动推送监控数据。
为了应对这种短生命周期的应用,纯Pull的系统都会提供一个中间层(例如Prometheus的Push Gateway):接受应用主动Push,再提供Pull的端口给监控系统。但这就需要额外多个中间层的管理和运维成本,而且由于是Pull模拟Push,上报的延迟会升高而且还需要即使清理这些立即消失的指标。
4 灵活性与耦合度
从灵活性上来讲,Pull模式稍微有一些优势,可以在Pull模块配置到底想要哪些指标,对指标做一些简单的计算/二次加工;但这个优势也是相对的,Push SDK/Agent也可以去配置这些参数,借助于配置中心的存在,配置管理起来也是很简单的。
从耦合度上讲,Pull模型和后端的耦合度要低很多,只需要提供一个后端可以理解的接口即可,具体连接哪个后端,后端需要哪些指标等不用关心,相对分工比较明确,应用开发者只需要暴露应用自己的指标即可,由SRE(监控系统管理者)来获取这些指标;Push模型相对来说耦合度要高一些,应用需要配置后端的地址以及鉴权信息等,但如果借助于本地的Push Agent,应用只需要Push本地地址,相对来说代价也并不大。
七 运维与成本对比
1 资源成本
从整体成本上讲,两种方式总体的差别不大,但从归属方角度来看:
Pull模式核心消耗在监控系统侧,应用侧的代价较低
Push模式核心消耗在推送和Push Agent端,监控系统侧的消耗相比Pull要小很多
2 运维成本
从运维角度上讲,相对而言Pull模式的代价要稍高,Pull模式需要运维的组件包括:各类Exporter、服务发现、PullAgent、监控后端;而Push模式只需要运维:Push Agent、监控后端、配置中心(可选,部署方式一般是和监控后端一起)。
这里需要注意的一点是,Pull模式由于是服务端向客户端主动发起请求,网络上需要考虑跨集群连通性、应用侧的网络防护ACL等,相比Push的网络连通性比较简单,只需要服务端提供一个可供各节点访问的域名/VIP即可。
八 Pull or Push如何选型
目前开源方案,Pull模式的代表Prometheus的家族方案(之所以称之为家族,主要是默认单点的Prometheus扩展性受限,社区有非常多Prometheus的分布式方案,比如Thanos、VictoriaMetrics、Cortex等),Push模式的代表InfluxDB的TICK(Telegraf, InfluxDB, Chronograf, Kapacitor)方案。这两种方案都有各自的优缺点,在云原生的大背景下,随着Prometheus在CNCF、Kubernetes带领下的大火,很多开源软件都开始提供Prometheus模式的Pull端口;但同时还有很多系统本身设计之初就难以提供Pull端口,这些系统的监控相比而言使用Push Agent方式更为合理。
而应用本身到底该使用Pull还是Push一直没有一个很好的定论,具体的选型还需要根据公司内部的实际场景,例如如果公司集群的网络很复杂,使用Push方式较为简单;有很多短生命周期的应用,需要使用Push方式;移动端应用只能用Push方式;系统本身就用Consul做服务发现,只需要暴露Pull端口就可以很容易实施。
所以综合考虑情况下对于公司内部的监控系统来说,应该同时具备Pull和Push的能力才是最优解:
主机、进程、中间件监控使用Push Agent;
Kubernetes等直接暴露Pull端口的使用Pull模式;
应用根据实际场景选择Pull or Push;
九 SLS在Pull和Push上的策略
SLS目前支持日志(Log)、时序监控(Metric)、分布式链路追踪(Trace)的统一存储和分析。对于时序监控方案是兼容Prometheus的格式标准,提供的也是标准的PromQL语法。面对数十万SLS的用户,应用场景可能会千差万别,不可能用单一的Pull或Push来对应所有客户需求。因此SLS在Pull和Push的选型上SLS并没有走单一路线,而是兼容Pull和Push模型。此外对于开源社区和Agent,SLS的策略是完全兼容开源生态,而非自己去造一个闭合生态:
Pull模型:完全兼容Prometheus的Pull Scrap能力。可以使用Prometheus的Remote Write,让Prometheus来做Pull的Agent;和Prometheus Scrap一样能力的VMAgent也可以这样使用;SLS自己的Agent Logtail也可以实现Prometheus的Scrap能力
Push模型:目前业界的监控PushAgent生态最完善的当属Telegraf,SLS的Logtail内置了Telegraf,可以支持所有的Telegraf的上百种监控插件
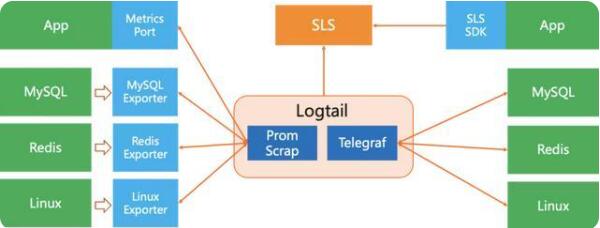
相比VMAgent、Prometheus这类Pull Agent以及原生Telegraf,SLS额外提供了最迫切的Agent配置中心和Agent监控能力,可以在服务端去管理每个Agent的采集配置以及监控这些Agent的运行状态,尽可能降低运维管理代价。
因此实际使用SLS进行监控方案的搭建会非常简单:
在SLS的控制台(Web页面)去创建一个存储监控数据的MetricStore;
部署Logtail的Agent(一行命令);
在控制台上配置监控数据的采集配置(Pull、Push都可以);
十 总结
本文主要介绍了监控系统中最纠结的Pull or Push选择问题,笔者结合数年的实际经验以及遇到的各类客户场景对Pull和Push的各类方向进行了比对,仅供大家在监控系统建设过程中参考,也欢迎大家留言和讨论。



















