本文转自雷锋网,如需转载请至雷锋网官网申请授权。
1、背景&摘要
在人群密度估计任务中,标注工作十分困难且费时,导致当前的公开学术集规模都较小且数据的分布差异较大(图1:密度差异,场景差异,视角差异等等)。因此,为了学习到泛化能力较强、通用性较高的人群密度估计模型,同时联合多种数据域知识来监督模型的训练成为了一种可能的方案。然而,直接利用联合数据训练模型会导致模型的选择性学习行为,即模型只对联合数据中的“主导”数据部分进行了有效的学习,而忽略了其余部分数据带来的域知识,从而导致模型表现出在不同域上性能变化的不一致性(表1:部分域性能提升,部分域性能降低)。
鉴于此,本文提出了域专属知识传播网络(DKPNet)来引导无偏知识的学习。其中,作者提出了变分关注技术(Variational Attention,VA),该技术可以显式地对不同数据域构建相应的关注分布,从而有效的提取和学习域专属的信息。此外,作者进一步提出了本征变分关注技术(Intrinsic Variational Attention, InVA)来解决覆盖域和子域的问题。作者对DKPNet在常用的人群密度估计数据集ShanghaiTechA/B, UCF-QNRF以及NWPU上进行有效的评估。

图1:不同数据域的分布差异
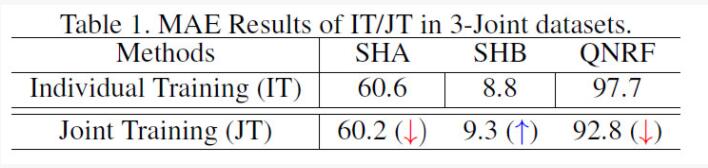
表1:直接联合训练带来的性能变化的不一致性
2、方法介绍
为了解决不同数据域分布差异带来的难题,我们需要克服深度模型的选择性学习行为,即只学习数据域中占“主导”地位的信息和知识。此外,考虑到CNN中通道信息通常是表达模式概念以及抽象表征的,而空间信息通常描述的是位置信息,因此为了建模域专属的信息,作者选取在通道信息上进行域专属知识的建模。如图所示:
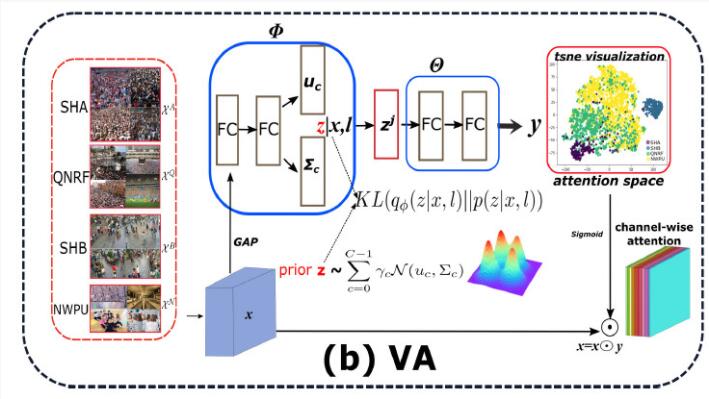
图2:变分关注模型VA
首先假设我们能通过通道信息来进行域的划分,即需要引入channel-attention机制来区分和引导不同域的学习,然而普通的channel-attention并不能显式地区分域专属的知识,因此需要人为地施加约束来提供引导。鉴于此,本文参考VAE的思想,首先引入潜变量z来建模不同数据域,根据变分思想,为了控制输出的关注分布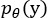 ,作者最大化条件概率的对数似然;
,作者最大化条件概率的对数似然;
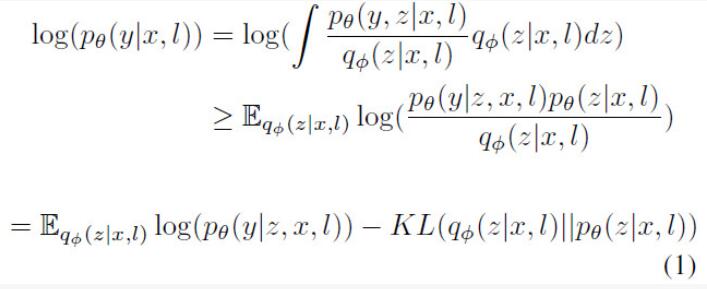
其中第一项用于提高预测的准确性,在人群密度估计中,将其写作:
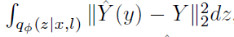
第二项描述的是变分分布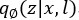 和先验分布
和先验分布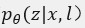 的KL散度。此外由于不同域的分布不同,本文采用混合高斯分布作为先验:
的KL散度。此外由于不同域的分布不同,本文采用混合高斯分布作为先验:
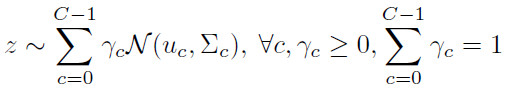
由此,KL散度变为:
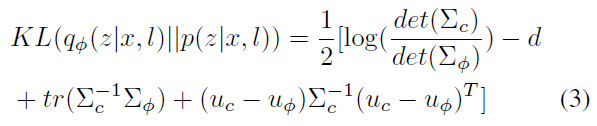
为了学习到自适应的域参数,将均值和协方差参数设置为可学习的。并对其施加如下约束来防止平凡解:
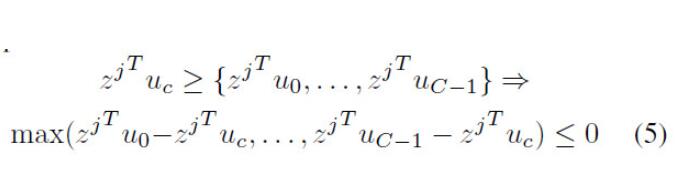
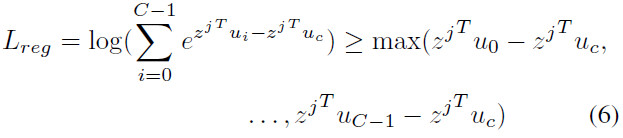
最终VA如图2所示,综合loss如下:
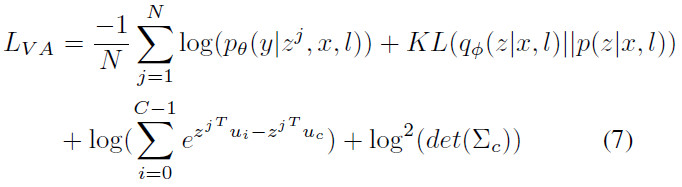
然而,上述的推理是基于一个假设,即不同数据集当作一个单独的数据域,这个假设在实际中并不能被很好地支持,例如NWPU数据中存在较多的子域,且不同数据集之间还可能存在重合的分布。鉴于此,作者基于VA又提出了InVA来解决覆盖域和子域的问题。
InVA区别于VA的地方主要是两个地方,第一个是首先会采用聚类的方式对attention分布进行粗略的划分,从而缓解覆盖域的问题;第二个是会采用子高斯混合先验对潜变量进行约束,从而缓解子域的问题。
最终使用VA和InVA对CNN的通道信息进行调整,得到了DKPNet,如图3所示:
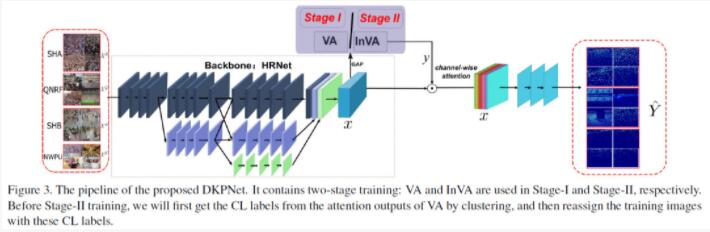
图3:DKPNet
3、实验结果
作者在4个常用的人群密度估计的数据集(ShanghaiTech A/B, QNRF, NWPU)上进行了多重验证,实验结果如表2所示。可以看到作者分别进行了3-Joint(SHA/SHB/QNRF联合使用)和4-Joint(SHA/SHB/QNRF/NWPU)实验,表示采用不同的个数的数据集进行的联合训练。当进行简单的联合训练之后,可以看到模型的性能并不能一致地在所有数据集上都得到提升,验证了模型的选择性学习的行为。当采用DKPNet之后,由于域专属的信息能够被显式地建模和学习,因此带来了显著的性能提升,并且在不同数据集上表现出了一致性。同时作者也给出了大量的消融实验(图4:attention分布对比;表3:的影响;表4:覆盖域和子域数量的影响等),证明了VA和InVA的有效性。

表2:实验结果
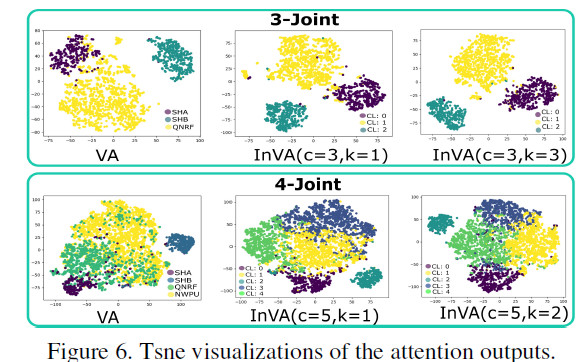
图4:attention分布示意图
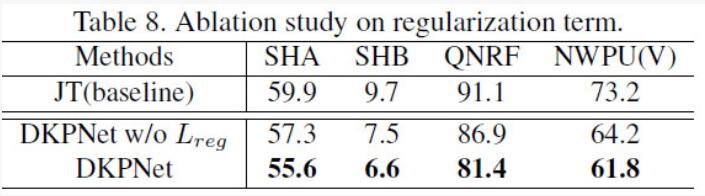
表3:约束的作用
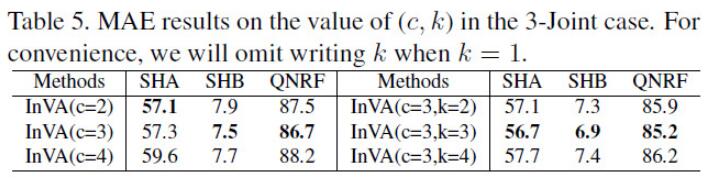
表4:覆盖域和子域数量的影响
4、结语
本文针对人群密度中多域联合训练的问题,提出了基于变分关注VA的域专属信息学习网络DKPNet,有效地缓解了多域联合训练中的有偏学习现象,通过引入潜变量对不同域进行建模,从而能够为模型的学习提供很好域引导。此外,为了更好地解决覆盖域和子域的问题,本文提出了InVA进一步提升域引导的质量。最终,作者通过大量的实验验证了该方法的有效性。