我们可以根据算法执行学习的方式将它们分为以下不同类别:
- 有监督学习
- 无监督学习
- 半监督学习
- 强化学习
01 有监督学习
有监督学习是目前商业过程中最常见的机器学习形式。这些算法试图找到映射输入和输出的函数的一个很好的近似。
为此,顾名思义,我们需要自己为算法提供输入值和输出值,并且尝试找到一个能够使预测值和实际输出值之间误差最小的函数。
学习阶段称为训练(training)。模型经过训练后,可以针对未见过的数据预测输出。此阶段通常被视为评分或预测,如图1-1所示。
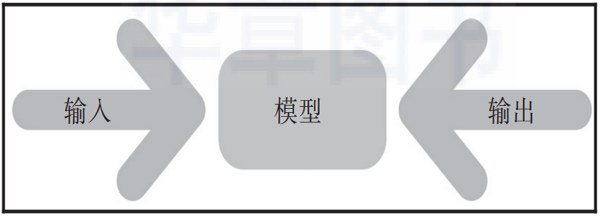
▲图 1-1
02 无监督学习
无监督学习适用于未标记的数据,因此我们不需要实际的输出值,仅需要输入。它尝试在数据中查找模式并根据这些共同属性做出反应,将输入划分为多个不同聚类(如图1-2所示)。
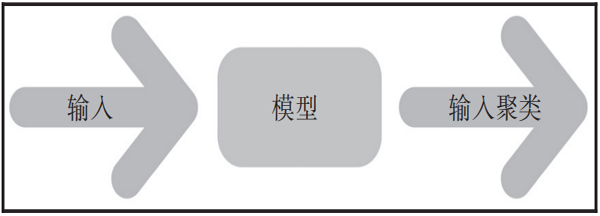
▲图 1-2
通常,无监督学习通常与有监督学习结合使用,以减少输入空间并将数据中的信号集中在较少数量的变量上,但无监督学习还有其他目标。从这个角度来看,当标记数据很昂贵或不太可靠时,无监督学习比有监督学习更适用。
常见的无监督学习技术有聚类(clustering)和主成分分析(Principal Component Analysis,PCA)、独立成分分析(Independent Component Analysis,ICA),以及一些神经网络,例如生成对抗网络(Generative Adversarial Network,GAN)和自编码器(Autoencoder,AE)。
03 半监督学习
半监督学习是介于有监督学习和无监督学习之间的一种技术。它可以说不属于机器学习中一个单独的类别,而只是有监督学习的一种泛化,但在这将其单独列出是有用的。
其目的是通过将一些有标记的数据扩展到类似的未标记数据,从而降低收集标记数据的成本。我们把一些生成模型分类为半监督学习。
半监督学习可以分为直推学习和归纳学习。直推学习适用于推断未标记数据的标签,归纳学习适用于推断从输入到输出的正确映射。
我们可以看到此过程与我们在学校学习的大多数过程相似。老师向学生展示一些例子,并让学生回家完成作业。为了完成这些作业,他们需要进行泛化。
04 强化学习
强化学习(RL)是我们目前所见的最独特的类别。这个概念非常有趣:该算法试图找出一个策略来最大化奖励总和。
该策略由使用它在环境中执行动作的智能体来学习。然后,环境返回反馈,智能体使用该反馈来改进其策略。反馈是对所执行动作的奖励,可以是正数、空值或负数,如图1-3所示。
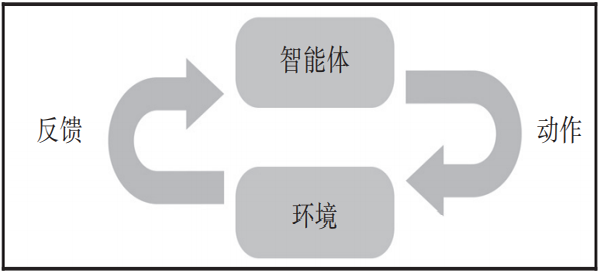
▲图 1-3