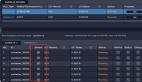
任务提交脚本
脚本模板
当我们提交一个Spark作业到YARN上,通常情况下会使用如下的脚本模板:
- spark-submit
- --class class-name
- --master yarn
- --deploy-mode cluster
- --driver-memory 4g
- --num-executors 2
- --executor-memory 2g
- --executor-cores 2
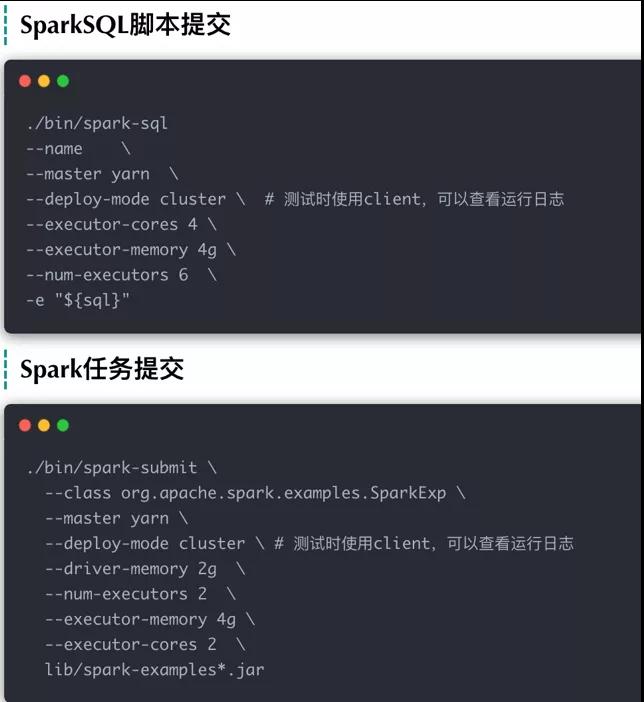
参数解读
具体参数的含义如下图所示:

- executor-cores
每个executor的最大核数
- num-executors=每个node的executor数 * work节点的数
每个node的executor数 = 总核数 / 每个executor的最大cup核数,具体是通过参数
yarn.nodemanager.resource.cpu-vcores进行配置,比如该值配置为:33,参数executor-cores的值为:5,那么每个node的executor数 = (33 - 1[操作系统预留])/ 5 = 6,假设集群节点为10,那么num-executors = 6 * 10 =60
- executor-memory
该参数的值依赖于:yarn-nodemanager.reaource.memory-mb,该参数限定了每个节点的container的最大内存值。
该参数的值=yarn-nodemanager.reaource.memory-mb / 每个节点的executor数量 ,如果yarn的参数配置为160,那么
yarn-nodemanager.reaource.memory-mb / 每个节点的executor数量 = 160 / 6 ≈ 26GB
Spark程序提交运行过程
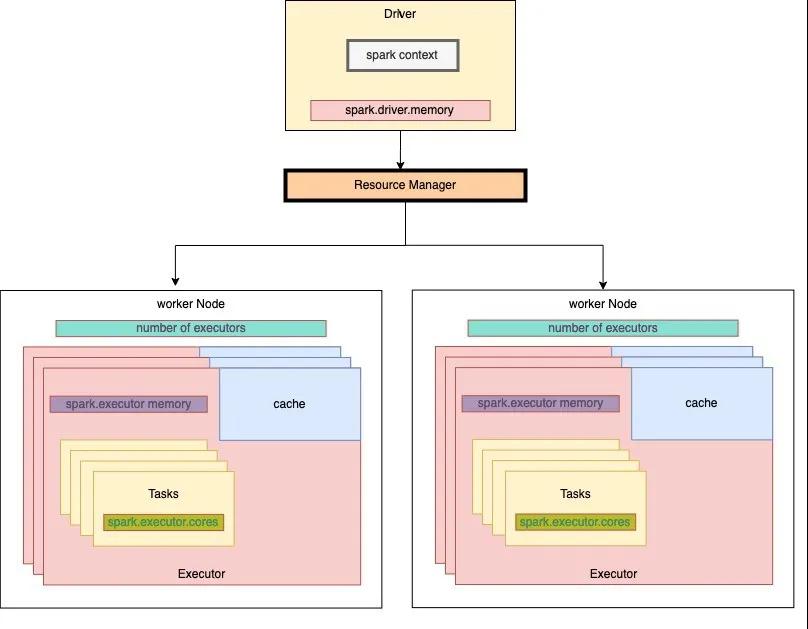
- 提交作业
- 资源管理器分配资源启动app master
- App master与Driver会同步被创建
- Spark driver与resource manager通信获取每个节点的可用资源
- resource manager 分配资源
- spark driver启动work节点上的executor
- executor向driver发送心跳信息
- driver发送结果到客户端
内存管理图解
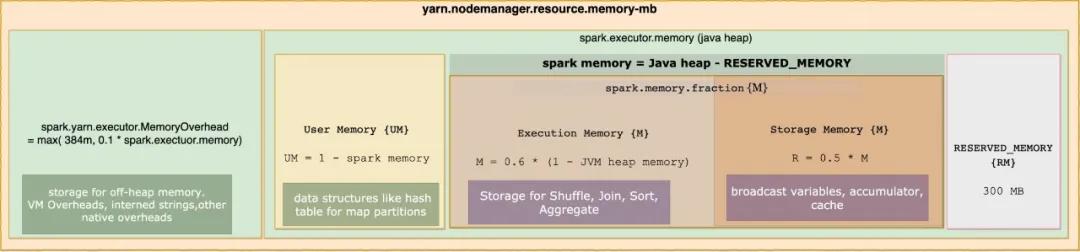
Spark2.X的内存管理模型如下图所示:
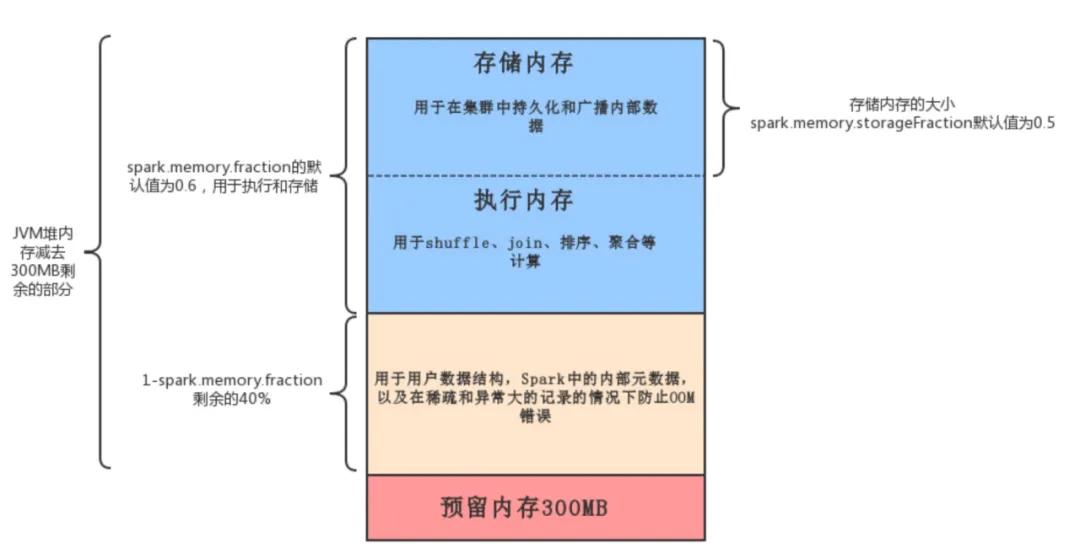
Spark中的内存使用大致包括两种类型:执行和存储。
执行内存是指用于用于shuffle、join、排序、聚合等计算的内存
存储内存是指用于在集群中持久化和广播内部数据的内存。
在Spark中,执行内存和存储内存共享一个统一的区域。当没有使用执行内存时,存储内存可以获取所有可用内存,反之亦然。如有必要,执行内存可以占用存储存储,但仅限于总存储内存使用量低于某个阈值。
该设计确保了几种理想的特性。首先,不使用缓存的应用程序可以使用整个空间执行,从而避免不必要的磁盘溢出。其次,使用缓存的应用程序可以保留最小存储空间。最后,这种方法为各种工作负载提供了合理的开箱即用性能,而无需用户内部划分内存的专业知识。
虽然有两种相关配置,但一般情况下不需要调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction默认大小为(JVM堆内存 - 300MB)的一小部分(默认值为0.6)。剩下的空间(40%)保留用于用户数据结构,Spark中的内部元数据,以及在稀疏和异常大的记录的情况下防止OOM错误。spark.memory.storageFraction默认大小为(JVM堆内存 - 300MB)0.60.5。