快手研究团队 MMU(Multimedia understanding)联合清华大学研究人员提出了一种基于音频信号的语种识别新方法。该方法自研一种动态多尺度卷积的新型网络结构,通过动态卷积核、局部多尺度学习和全局多尺度池化技术来捕获全局和局部上下文的语种 / 方言信息。目前该论文已经被国际顶级语音会议 Interspeech2021 所接收。

论文链接:https://www.researchgate.net/publication/353652910_Dynamic_Multi-scale_Convolution_for_Dialect_Identification
语种识别是指从一段说话语音中识别出语种(或方言)的类别,如日语、韩语、普通话、粤语等。语种识别技术的应用非常广泛,不仅可以作为多语言语音识别(ASR)和多语言翻译系统的前端预处理模块,也可以用于定向广告和生物特征验证。近年来,随着深度学习技术的兴起,语种识别在工业界和学术界都得到广泛的关注。几年前,x-vector 是语种(或方言)识别的主流方法。随着深度学习技术的快速发展,基于 DNN 的语种识别网络结构进行了快速的迭代,从最初的 TDNN 到 D-TDNN,再到 Ecapa-TDNN 以及 ResNet 网络结构,语种(或方言)识别性能获得显著提升。
为了有效捕获音频中的上下文语种信息,进一步提升语种识别性能,快手研究团队 MMU(Multimedia understanding)联合清华大学研究人员提出了一种基于音频信号的语种识别新方法。该方法自研一种动态多尺度卷积的新型网络结构,通过动态卷积核、局部多尺度学习和全局多尺度池化技术来捕获全局和局部上下文的语种 / 方言信息。具体来说,引入动态卷积核的方法,模型能够自适应地捕获短期和长期上下文之间的特征;局部多尺度学习在细粒度级别表示多尺度特征,能够增加卷积运算的感受野范围,同时使模型参数量大幅下降;全局多尺度池化用于聚合来自模型不同瓶颈层的语种 / 方表征。文章的贡献包括如下 3 点:
1. 第一次将动态卷积核引入语种 / 方言识别领域。
2. 局部多尺度学习,在更细粒度层面上对多尺度特征进行表征学习。
3. 全局多尺度池化,能够聚合模型多个层次的特征。
针对 2020 年东方语种识别 (OLR2020) 挑战赛的 AP20-OLR 语种识别任务,所提语种识别新方法取得了平均代价损失 (Cavg) 为 0.067,等误差率 (EER) 为 6.52% 的成绩。相比 OLR2020 挑战赛中的最优(SOTA,state-of-the-art)识别系统,所提语种识别新方法获得了 9% 的 Cavg 和 45% 的 EER 相对提升,而且模型参数减少了 91%,性能显著优于 SOTA 系统。目前该论文已经被国际顶级语音会议 Interspeech2021 所接收。
方法介绍
快手 MMU 和清华自研的动态多尺度卷积的新型网络结构框图如图 1 所示,为了简化,批归一化层 BatchNormalization (BN) 和 ReLU 激活函数已省略。从图中可以看出,动态多尺度卷积的新型网络结构采用 D-TDNN 网络作为基本骨架,将第一个 D-TDNN 层修改为动态多尺度卷积块,它在粒度级别上表示局部多尺度特征,并增加了卷积运算的感受野范围。此外,全局多尺度池化方法聚合了不同的瓶颈层特征,以便从多个方面收集信息。
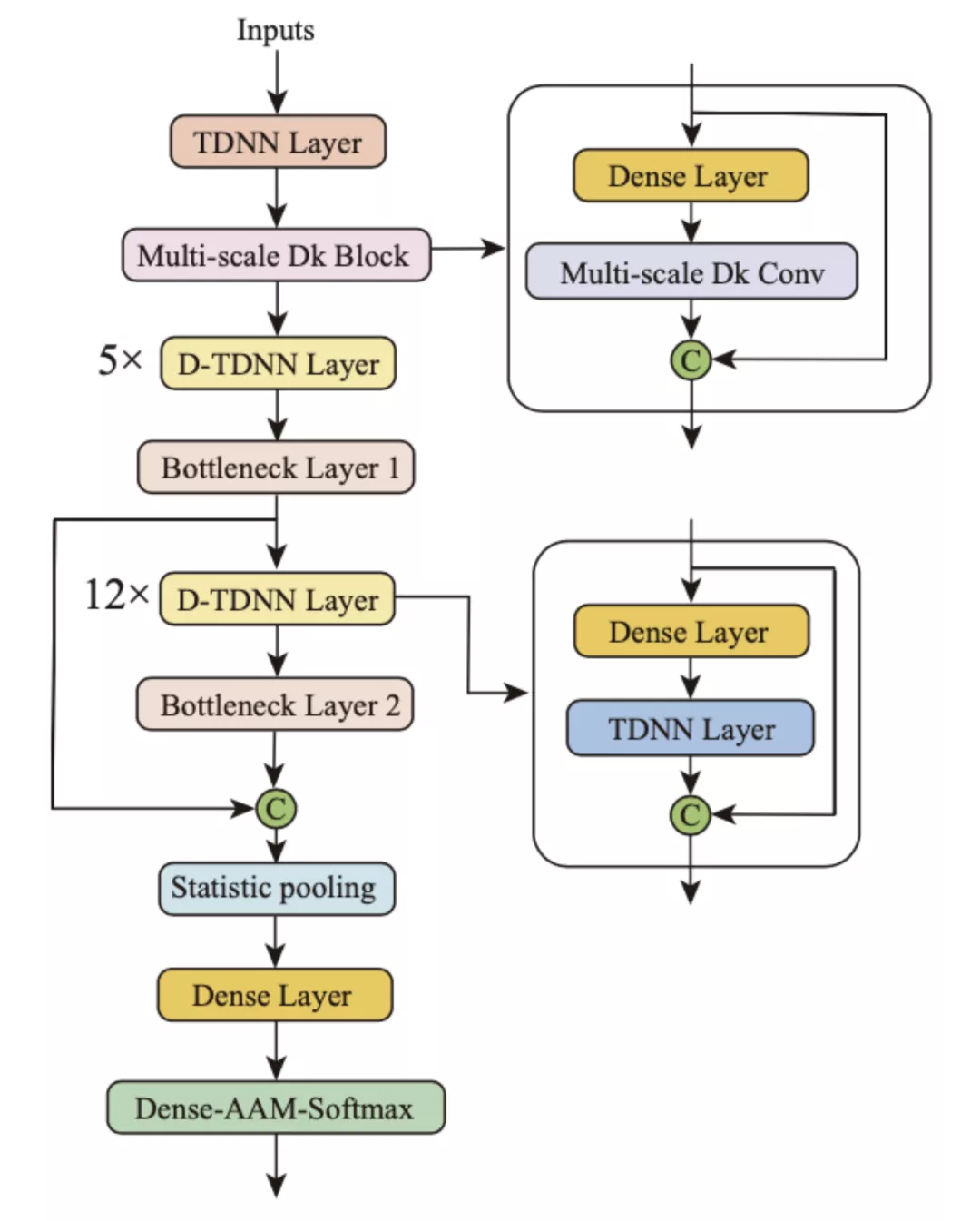
图 1: 动态多尺度卷积结构。在图中,"Multi-scale Dk Block" 指的是全局和局部多尺度动态卷积核模块,"Multi-scale Dk Conv" 指的是局部多尺度动态卷积核操作。绿色的 "C" 定义了 "拼接" 操作。
1. 动态卷积核
动态卷积核(Dk Conv)是一种基于 Softmax 注意力的动态通道选择机制,具体结构如图 2 所示。
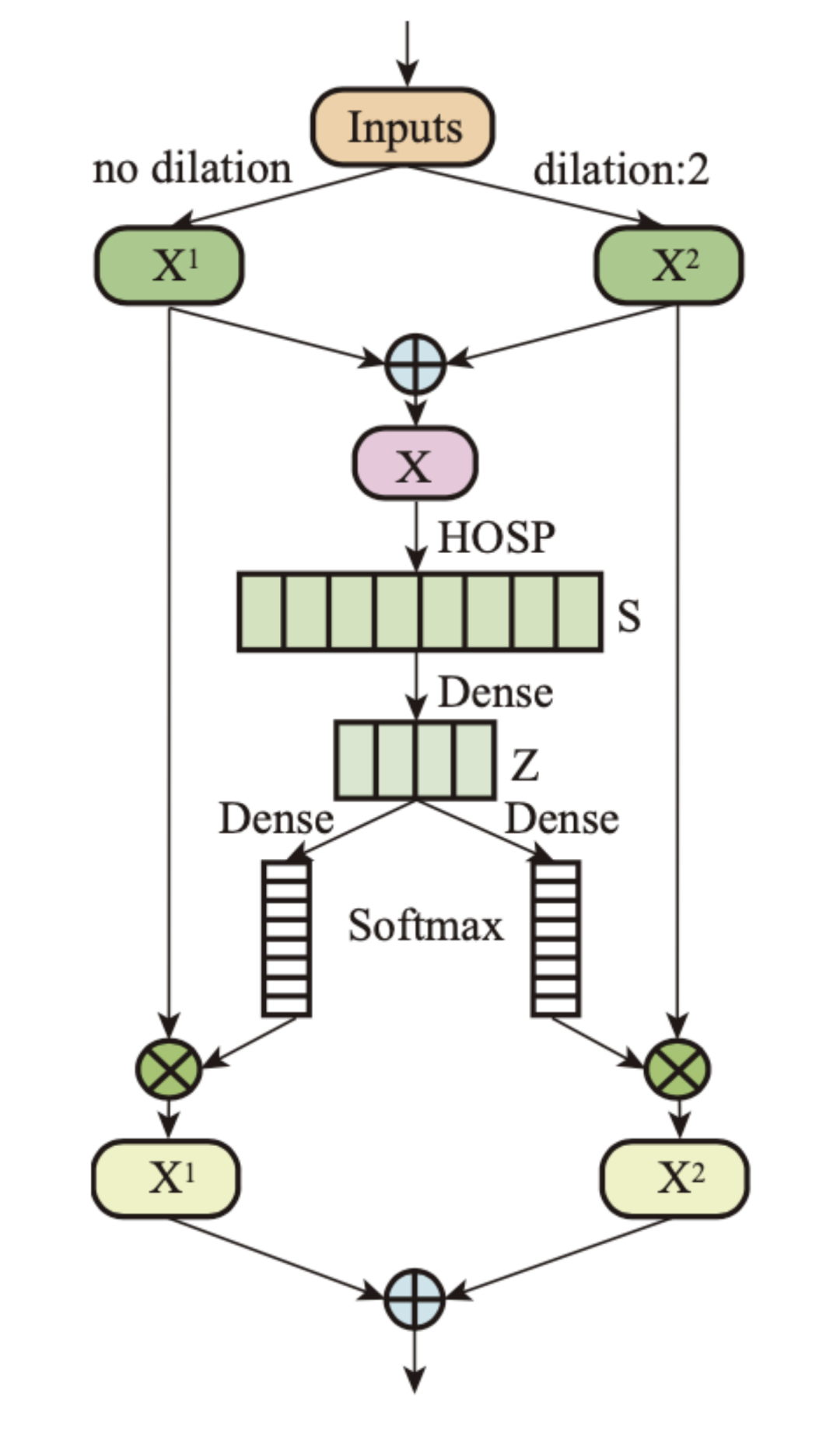
图 2:动态卷积核 (Dk Conv) 模块。
从图中看出,网络结构具体描述为:高阶统计池化层(HOSP)- 线性层 - 线性层 - Softmax,其中 HOSP 目的是从空间维度收集通道信息,其它神经网络模块是为了评估不同分支的重要性。卷积的多分支扩展能够使模型自适应地捕获短期和长期上下文之间不同的方言表征。
2. 局部多尺度学习
受 Res2Net 中层内残差连接的启发,该团队采用局部多尺度学习来提高卷积操作的表征能力。局部多尺度学习是指在卷积中实现更细粒度的多个可用感受野。如图 3 所示,作者将特征平均分成 s 个特征子集,用 Xi 表示,其中 i∈[1,2,...,s]。
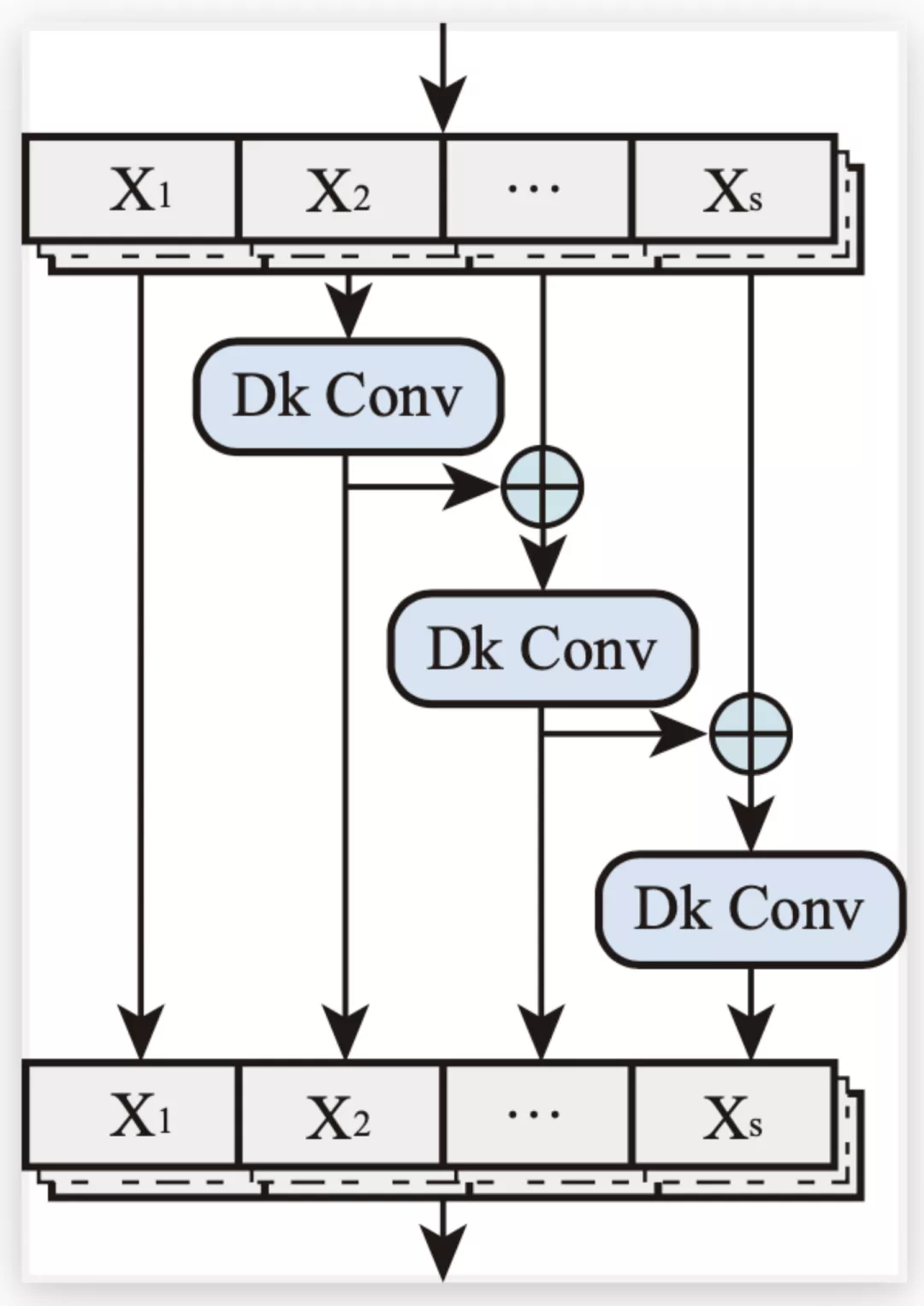
图 3: 局部多尺度学习。在图中,"Dk Conv" 表示动态卷积核操作,⊕表示逐元素相加
一组过滤器首先从相应的特征子集中提取特征。然后将前一组的输出特征与另一组输入特征一起发送到下一组过滤器:
其中 F 表示 Dk Conv 的操作。在 Multi-scale Dk Block 中,Dk Conv 过滤器的数量是 D-TDNN 层通道数的 1/s 倍。所有的 F 操作完结后,可以得到 Outi 的串联作为当前模块的输出:
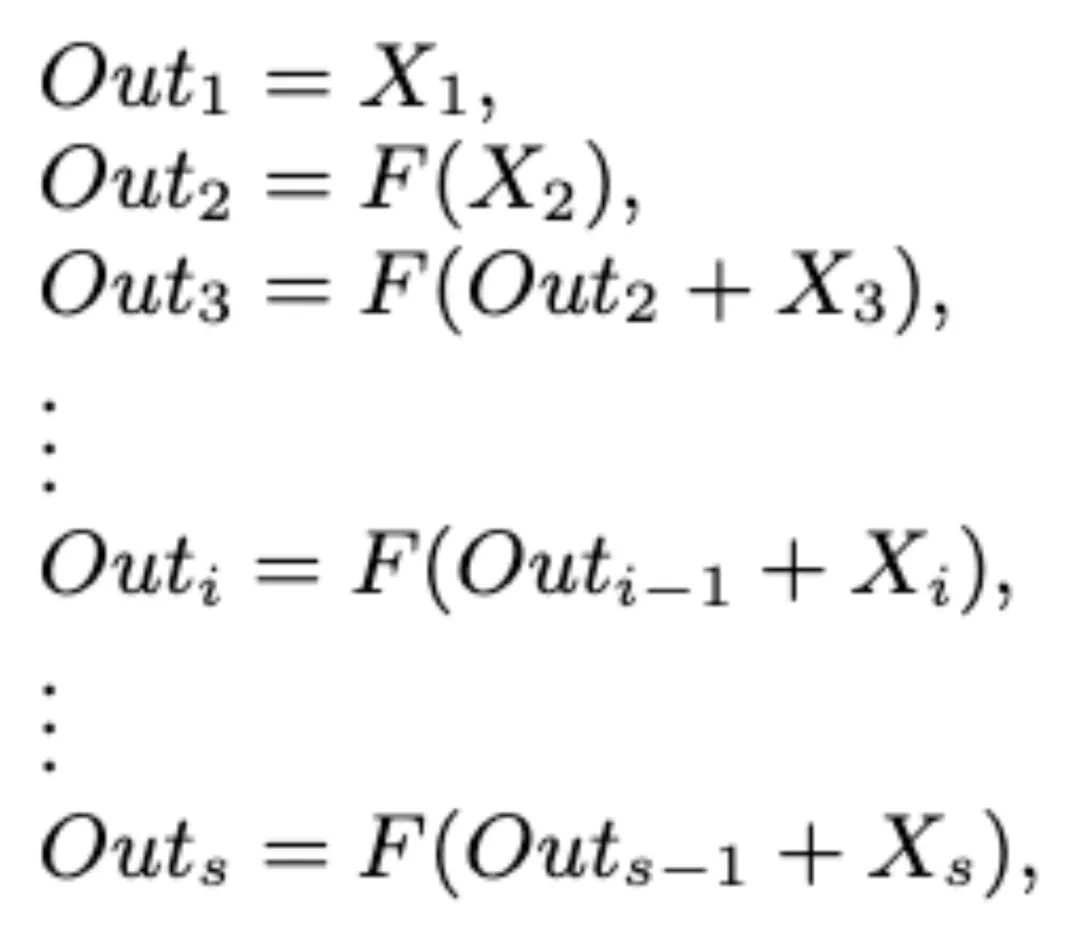
最后,在处理完这些特征集合后,将所有组的特征按照通道数连接起来并发送到下一个操作以融合信息。通过引入超参数 s,局部多尺度学习(在粒度级别表示多尺度特征)被证明可以有效地增加卷积运算的感受野范围。此外,随着每一个尺度卷积滤波器数量的减少,模型参数量也得到了显著下降。
3. 全局多尺度池化
前人的工作得出结论:不同层的特征聚合可以提高声纹识别任务中说话人表征的区分性。瓶颈特征是一种高层次的信息聚合。因此在通道维度上聚合不同的瓶颈特征并将它们送入统计池层,以增强语种 / 方言分类能力是十分必要的。全局多尺度池化方法的结构如图 4 所示。
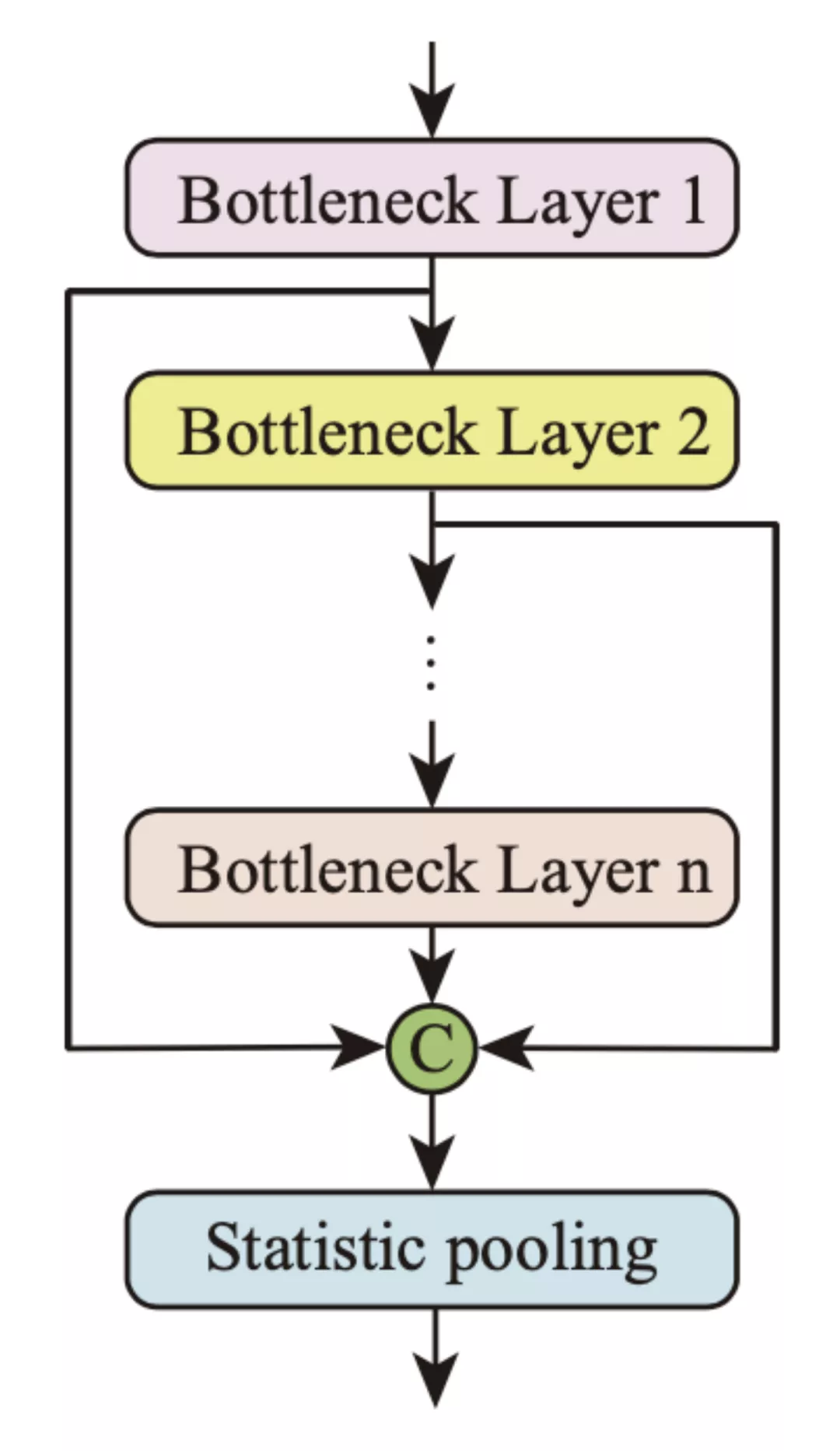
图 4: 全局多尺度池化
该团队重新定义了帧级特征 h_t,在通道维度上聚合了不同层的瓶颈特征 h_bi (i = 1, · · · , n),其中 n 是瓶颈层的数量。
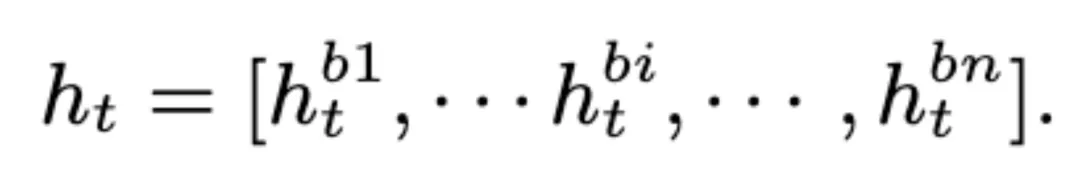
全局多尺度池化层在帧级特征 h_t(t = 1,... ,T) 上以标准差向量 σ 的形式计算均值向量 μ 以及二阶统计量。
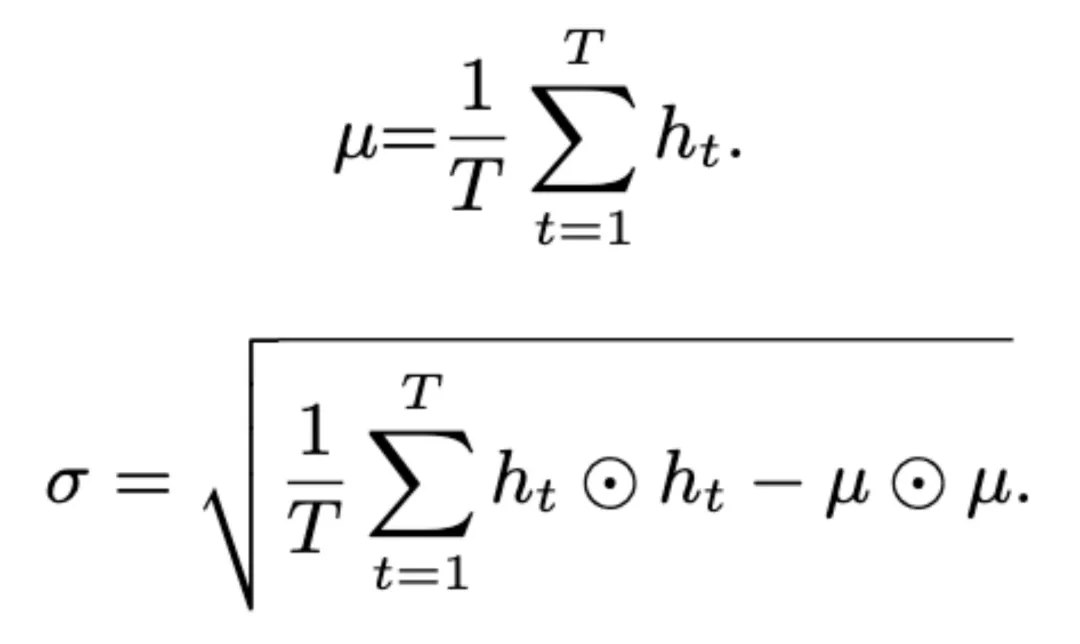
该团队在实验中使用两个瓶颈层用于全局多尺度池化。实验表明,使用全局多尺度池化方法可以产生更加具有区分力的语种 / 方言表征。
实验结果
为了证明所提模型在语种 / 方言识别任务上的有效性,该团队研究人员在东方语种 OLR2020 挑战赛识别任务 2 的方言识别任务上面进行了测试实验,采用了两个评价指标:平均损失性能 Cavg 和等错误率 EER 进行性能评估,并且和主流的语种 / 方言识别技术进行了性能和参数量的对比。
1. 东方语种识别大赛数据介绍
在 2020 年东方语言识别 (OLR) 挑战赛中,该团队使用 AP17-OL3、AP17-OLR-test、AP18-OLR-test、AP19-OLR-dev、AP19-OLR-test 和 AP20-OLR-dialect 作为语种 / 方言任务的训练集。所有训练数据包括 16 种语言,包括日语、韩语、闽南话、上海话、四川话等语种 / 方言。组合数据集的详细信息如表 1 所示。
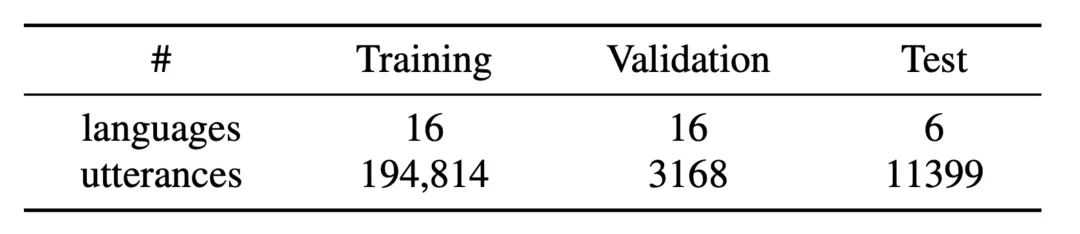
表 1: 训练集和评估集的数据。
2. 横向对比
从表 2 中,我们可以观察到,在相同的语种 / 方言识别任务中,动态多尺度卷积方法的性能明显优于东方语种识别 2020 任务 2 中 top2 的模型。与 OLR Challenge 2020 排行榜 No.1 (SOTA,state-of-the-art)识别系统相比,我们的模型仅使用 290 万个参数即可分别实现 9.2% 的 Cavg 和 45% 的 EER 相对改进。

表 2: 与 top2 系统的比较。在这张表中,Royal Flush 和 Phonexia 分别是 2020 年 OLR 挑战赛排行榜的第 2 名和第 1 名。该系统相比 top1 分别实现了 9% 的 Cavg 和 45% 的 EER 相对改进。
3. 纵向对比
表 3 显示在东方语种识别中语种 / 方言识别任务上的消融研究的性能。测评分析了福建话、四川话和上海话的 Softmax-output 分数。该方案所有提出的模型在 EER 方面都要优于 OLR2020 挑战赛中 最先进系统。值得注意的是,该团队所提出的动态多尺度卷积方法在包括 Cavg 在内的所有指标中都取得了最佳性能,这表明该方法对于语种 / 方言识别任务是非常有效的。

表 3: 东方语种 2020 比赛赛道二语种 / 方言识别任务上的消融实验
实验结果表明,与使用 Softmax 损失函数的模型相比,使用 AAM-Softmax 的模型可以获得更优异的性能。与基线系统 D-TDNN 的方法相比,动态卷积核的操作是非常有助于进行语种 / 方言识别的。局部多尺度动态卷积核将多尺度学习与动态卷积核相结合,通过引入多尺度学习,进一步提高了性能,相对减少了 36% 的参数,而模型参数量仅有 250 万。此外卷积内的局部多尺度学习方法可以有效地通过超参数 s 减少模型参数量。全局和局部多尺度动态卷积核方法采用了全局多尺度池化方法,是局部多尺度动态卷积核的变体。将全局和局部多尺度动态卷积核的结果与局部多尺度动态卷积核结果进行比较,可以看出全局多尺度池化对于提高语种 / 方言识别的性能是大有帮助的。
目前,语种 / 方言识别已应用于快手视频审核、同城直播、推荐、素材挖掘等多个业务场景,为各个业务带来显著收益。
- 在同城直播业务,利用方言直播识别技术为同城直播打上方言标签,助力同城主播的消费指标提升。
- 在推荐业务场景,为视频打上语种(或方言)标签,助力推荐将作品进行区域分发,提升视频的消费效果。