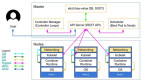
Kubernetes已经成为行业标准,并且也成为了运维标配,现在出去面试,如果哪个公司没有注明需要Kubernetes技能(国企除外),那么这个公司你就不要考虑了(钱给的实在多除外^_^)。
Kubernetes虽然成为了标准,但是不同的运维在实施的时候,或者说不同的公司在使用的时候是千奇百怪的,我们也会经常在一些Kubernetes社区群里看到一些千奇百怪的问题,这些问题除了提升自身硬实力之外,也要树立一些做事的规范。这里从下面四个方面说一些个人的看法和见解,这些都是我自己在实际工作中运用的,说的不对的地方请指正。
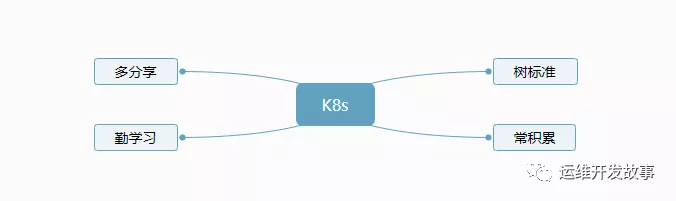
树标准
俗话说,无规则不成方圆。Kubernetes已经成为了标准,但是对于实施来说却没有标准,这就导致了一万人有一万个Kubernetes集群,玩法多变,也会导致问题多变。那这里的树标准主要是指什么呢?

基础设施标准
随着云的能力不断提升,很多互联网公司已经不太去关心底层设施了,比如服务器的型号、维保,交换机的配置、机柜的信息等。那我们在选择基础设施的时候主要关注哪些呢?
我这里以阿里云为例,简要列出以下几点。
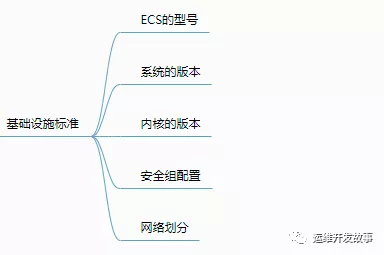
(1)ECS型号 在很多时候并不太关心型号问题,大多数情况下这是资金驱动,公司舍得花钱就买好点的,不舍得就将就用。我这里之所以列出来是为了避免因为不同的型号导致一些莫名奇妙的问题,比如说有的机器是独享型,有的机器是共享型,共享型机器难免会被别的服务器影响导致一些不可描述的事情,这时候作为使用方来说很难去定位到具体的原因,大部分情况都会把这类问题推给云厂商。
但是运维的难处就在于“只要出问题,那就是你的问题”。虽然可以把锅丢给云厂商,但是实际问题依旧存在,所以我们在做ECS选型的时候除了考虑价格,也要规避一些可能出现的问题,最好做到实例统一。
(2)系统版本 对于Kubernetes来说,不太去关注底层使用什么操作系统,但是作为运维来说最好统一,这样最大的好处就是便于维护。维护难度降低了,在一定的程度上降低了风险。
当然选择系统版本也要选择熟悉的系统,比如你熟悉CentOS,那就选择CentOS好了,不要去用什么Debian、Ubuntu等,虽然它们之前的变化不是很大。
(3)内核版本 内核和系统其实应该放在一起说,这里之所以单拧出来,主要还是Kubernetes、Docker对内核的要求还是比较高,在很多情况下我们都需要升级内核以满足需求。
在选择内核升级的时候一定要选择稳定版,而且所有服务器都统一升级,这样可以确定基础设施是一致的。
(4)安全组配置 在公有云上都有安全组这一说,主要是控制网络的进出。如果一套环境还是统一比较好,不仅方便管理控制,也大大降低了复杂度,不论是自己维护的复杂度,也包括交接出去的复杂度。
(5)网络划分 在公有云上不需要去管理实际的路由器、交换机,但是需要我们划分网络。我习惯根据业务划分,比如有A\B\C三个业务部门,给A划分192.168.1.0/24,给B划分192.168.2.0/24,给C划分192.168.3.0/24的网段,为什么要这么划分呢?我是基于出口好配置来考虑的,在云上出口基本是使用Nat网关的,如果是同一个IP段,Nat网关就只能创建一个,如果多个网段就可以创建多个NAT网关,这样可以在大流量的情况下进行一定的分流。
做这些的目的其实是让运维的线路图更清晰明了,运维的工作本身就比较杂,我们只有努力化繁为简,才能更好的保障稳定性,也才有更多的时间去攻坚其他东西。
应用标准
在很多公司,运维都是一个不受重视的群体,换句话说就是没有话语权,那怎么才能逐渐提升话语权呢?第一是主动,在应用的整个生命周期主动去参与,了解应用的动态,掌握应用的机制。第二是制定标准,在应用的生命周期中,去发现问题并针对问题给出解决方法,然后指定一系列标准,久而久之,大家都会按照这些去执行了。
话说回来,运维并不参与具体的代码开发,大部分运维也看不到开发代码,那如何去定义标准呢?
我从运维常会问或者常会用的几个方面来进行简要说明。

(1)打包方式 为什么要说打包方式呢?因为在给应用做CI的时候都会涉及到应用打包,如果应用打包方式统一我们是不是只需要做一个CI模板,或者说可以更好的减少参数配置。比如后端使用的开发语言都是java应用,有的时候习惯使用maven,有的人习惯使用gradle,哪种比较好呢?其实都差不多,但是如果规定只使用一种,是不是更简单一点。
比如我这里就规定了只要java应用,全都采用gradle进行管理,那我在做CI的时候基本都不需要询问开发人员如何打包了。
(2)应用目录 应用目录涉及如下几个。

为什么把这几个目录单独列出来呢?实际上是这几个目录在整个应用生命周期中都扮演着非常重要的角色,把这几个目录统一的,不论是制作镜像还是收集日志,甚至是排查问题都能够直接明了,不用为了找目录而浪费时间。
比如目录按以下方式:
- 部署目录 /app
- 缓存目录 /app/cache
- 日志目录 /app/logs
- 临时目录 /app/tmp
- 1.
- 2.
- 3.
- 4.
(3)应用日志 做运维这么多年,深深的领悟了一个道理:日志不规范,运维两行泪。所以应用日志定义好统一的格式以及输出方式,最好能够输出到控制台,这样在做日志收集的时候方便快捷。
(4)运行参数 应用的运行时参数配置,比如运行端口、Java的JVM参数配置,以及新生代、老生代、永生代的堆内存大小配置等。
比如应用统一使用端口8080,JVM参数参考如下配置:
-server
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
-Xms1G -Xmx1G
-XX:MetaspaceSize=128m JAVA_MAXMETA_SIZE="512m"
-XX:LargePageSizeInBytes=128m
-XX:+ParallelRefProcEnabled
-XX:+PrintAdaptiveSizePolicy
-XX:+UseFastAccessorMethods
-XX:+TieredCompilation
-XX:+ExplicitGCInvokesConcurrent
-XX:AutoBoxCacheMax=20000
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:+PerfDisableSharedMem
-verbosegc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/app/logs/gc.log"
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/app/logs/oom-`date +%Y%m%d%H%M%S`.hprof"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
当然,这只是一个样例,不是标准,具体的优化或者配置是根据具体情况进行微调的。
制品标准
Kubernetes中的应用制品都是容器镜像,所以这里说的就是容器的制作一些建议。
(1)选择标准并且统一的母镜像,这样更便于升级、更新、漏洞修复。
(2)镜像的层级越少越好
(3)应用使用非root用户运行,不要开启特权模式
(4)不要安装过多的命令软件,在很多情况下,并不需要。
CI/CD标准
不同的公司有不同的CI/CD,有基于开源软件的,有自研的,这里阐述的主要是针对开源软件,在国内这种才是主流。
开源软件的选择也非常多,有GitlabCI,有jenkins,还有更云原生的比如Token、Argo Workflow等,那究竟选什么呢?我发现在很多群里经常有人在问“你们公司都用什么做CI/CD的,什么工具比较牛逼”。我个人觉得,在选择什么工具的时候主要考虑以下几点:
- 公司在过去的时间内使用的是什么工具,这些工具目前的优缺点是什么,如果要换工具,如何能保证优点继续保持,缺点能够得到改进,如果只是想单纯的换个工具玩玩,真不建议去做切换,费力不讨好。
- 公司整个的组织形式、人员情况。因为这套工具不只是运维使用,开发、测试都要使用,虽然运维能够占据一定的主导地位,也要考虑整个团队的接受能力。
- 选择自己熟悉并且擅长的东西。这些工具说到底还是需要运维来进行维护管理,选择自己熟悉的,避免出问题只有百度的尴尬局面。
但我们决定好使用的工具之后,就是真正实施的阶段了。这里以Jenkins进行简单的阐述,相对来说,我对jenkins熟悉点,所以在公司里我会首选这个。
- 充分使用Jenkins shareLibrary,将一些重复的代码进行抽离形成单独的方法,方便扩展。
- 前后端同一门开发语言的项目,Jenkinsfile最好能统一,这样便于管理维护。
- Jenkinsfile中涉及的固定参数和可变参数需要固定好变量名,命令要规范易懂。
- 如果是多环境发布,需要做好分类管理,并且做好权限控制。
- 应用的发布不论是使用Helm Chart还是普通的deployment文件,为了便于管理最好使用同一种,减少混合使用的情况。
标准很重要,标准却没有标准。这句话是不是很矛盾?在很多情况下,并没有严格意义上的标准,所谓的标准是因人而异、因地而异的,上面列出的也仅是我在工作中常用的,只能称为是我的标准。
常积累
为什么要常积累?主要是因为现在技术发展的太快了,在这么高速迭代的时代,很多东西不可能一下就学完、学会,那就需要我们经常积累知识,将这些知识进行统一管理,在需要问题或者想学习的时候便于查找。
我每天早上会看一个小时左右的文章,如果看到比较不错的文章就会把它们收藏归类,并且会时不时去看一下。如果是自己新学的知识或者某种技能,就会把这些东西整理到语雀上,按着一定的目录结构进行归档分类,在我需要的时候就能轻松的查询。
多分享
积累是向内输出,分享是向外输出。向内输出相对容易,因为这些东西都是别人整理好的,我们只是把需要的东西纳为己用。向外输出就相对难一点,因为这不仅仅是写文章那么简单。
如果是在社群分享,那就要把文章写的易懂,为什么这么说呢?因为大部分人没有太多的时间去研究很深的东西,都是走马观花的看看,如果需要喜欢的就驻留一下,不喜欢的就直接划过,如果写的太深,许多人都不愿意看的。
如果是在团队内分享,不仅要写的易懂,还要讲的易懂。我之前的领导给我说过一句话:你要把别人都当成什么都不懂的小白。在分享的时候不要扯太多高大上的名词,这些名词除了吹牛逼,没有太大的实际效果。
不论是哪种方式、哪种形式,都要养成多分享的习惯,当我们到达一定的阶段过后,都逃不过这个过程,不论是管理还是技术专家。
勤学习
这个和"常积累"相辅相成。
学习是一件终身的事情,不论是何年龄,在何公司,处于何地位,都应该持续学习,当然在不同的阶段学习的东西不一样而已。
我每个月会看1~2本书,有纯技术类的,也有育儿类的,还有成长类的,不论是哪种书籍,到现在已经保持3年多了,看到不错的书籍还会多看1-2遍。
这个社会被分成了不同的阶层,但是大部分都是底层的人,这类人都需要慢慢的向上爬,如何才能保持这种向上成长的趋势呢?除了运气之外,自身的实力才最主要,不然运气来了你也抓不住。所以我们需要不断的扩展我们的知识、技能,学习就是其中最主要的一环。
写在最后
上面分享了一点个人的看法,在工作中一定要标准先行,然后围绕标准做扩展,并且要时常保持一种向上成长的姿态,多学习,多积累,多分享。把这些培养成习惯,让习惯成为自然,生活不是得过且过,是要不断的向上。
本文转载自微信公众号「运维开发故事」

【编辑推荐】