什么是解析
解析是将 输入 根据要求 运算 出 结果。 比如将四则表达式"1 + 2"运算出3。
解析是 很常见的需求,特别是软件的配置,但很多程序员不会自己去手写,可能也不知道怎么写 。 大概是因为现在已经有了一些通用的标准格式,比如ini, json, yaml等,这些常见的格式都有标准库可供使用。 然而 不管是否需要自己定制,还是用现有的格式,手写解析文本是一项非常提升编程能力的事情。 这也是本文的目的,通过四则运算的例子,分享如何实现解析器,还有编程经验和思考。
例子四则运算
麻雀虽小,五脏俱全,这估计是最迷你的解析例子了。我们要做的事情就是将字符串"100 - 20 * 30 + 40 * 50",解析运算出结果:240。这里只支持整数和加减乘除。 有兴趣的同学,可以不看本文的实现 ,先自己手写试一下 。
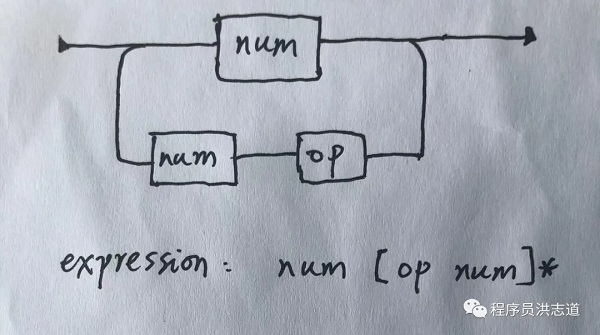
(四则运算语法表示)
解析通用模式
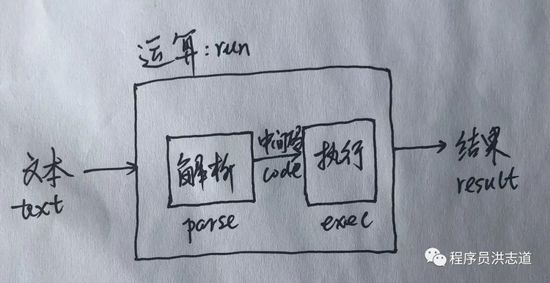
不管是实现语言,解析配置,解析特定文本需求,解析模式大致一样,都是如图所示。只是有些语义更复杂,有些需要考虑性能,在解析和执行中间会增加更多的处理,像语法树,甚至C语言.o文件。
通用术语:
text:文本字符串作为输入源,文件的话会被读成(流式)字符串。
run:运行。运行输入,计算出结果。
parse:解析。
token:词法单元,比如 "123", " 40", " +", " -" 。
expression:表达式,比如" 3", "1 + 2" 。
unary:一元操作数,比如3, 20, 100。
code:中间码,由parse产生。
exec:运行中间码产生结果。
这些术语也会在代码实现中出现。
运算就是我们要做的事情,要实现解析和执行两个功能。以解析四则为例:
- calc_run(text):
- code = cacl_parse(text)
- cacl_exec(code)
(calc是calculator的缩写)
计算机世界里的四则运算
代码是人类逻辑的一种表示方式。"1 + 2"是人眼可读懂的,但对计算机,我们得设计一个它能执行的。
1. 借助栈(数组),解析后的中间码这样表示: 。
code = [1, 2, +]
2. 执行,遍历code作相应的处理。
lo op:c = code[i++];
if (c is num) {
s.push(c)
} else {
op1 = s.pop()
op2 = s.pop()
r = op1 + op2
s.push(r)
}
(s是临时的栈用于存放运算值)思路就是压值进去,碰到操作符取出来运算,并且将结果压进去, 所以最后 的结果 会是s[0]。
如何实现新功能
假设这是一个需求,怎么在不用996的情况下,完成并且是高质量的代码。这是编程能力的综合体现,所以本质上还是要不断提升编程能力。需要指出的是简化是一种特别的能力,我们要在编码中经常使用。
1. 构思整体设计,能清晰的陈述实现逻辑。
2. 编写测试用例。
我们给这个功能取个名称:calculator,运算器的意思,并且用它的缩写作为前缀cacl。
编程经验:无比重要的命名
善用缩写作为前缀, 对项目和模块加个有意义的前缀能让读代码的人清楚它的上下文。 这在团队协作里更有价值。
a. 项目:比如nginx的源码里都有ngx_,nginx unit里的nxt_,njs里的njs_等。这些都可以让人清楚的知道这个项目的名称。
b. 模块:比如nginx里的http模块ngx_http_,日志模块ngx_http_log_,unit里文件服务的nxt_http_static_等。注意模块是可以包含子模块的。
所以我们将用cacl_作为四则运算解析的前缀,会有cacl_run, cacl_parse, cacl_exec这样的函数。
编程经验: 追求清晰和简洁
代码即逻辑,其它都是表达逻辑的方式。像文件,模块,函数和变量等。
不管需要什么样的命名,变量,功能函数,文件名等,清晰和简洁是我认为最重要的。在做到清晰的前提下保持简洁,即一目了然。
比如命名:
nxt_http_request.c ,表示http 的请求处理模块 ,足够清晰和 简洁。
nxt_h1proto.c,表示http的1.1协议的处理。
nxt_epoll_engine.c,表示epoll模块,对比下nxt_event_epoll_engine.c。因为epoll已经是个专业术语,用于处理网络事件的,这时event就变的多余了,在能表达清晰的前提下,继续追求简洁。
比如逻辑:
good
- /*
- * 读数据
- * 如果成功,追加数据
- * 返回数据
- */
- data = read();
- if (data) {
- data = data + "...";
- }
- return data;
ok
- /*
- * 读数据
- * 如果失败,返回空
- * 追加数据
- * 返回数据
- */
- data = read();
- if (data == null) {
- return null;
- }
- data = data + "...";
- return data;
这是个很小的例子,只是为了说明在做到清晰的前提,做到越简洁越好。
比如设计:
因为天赋可能是天花板。目前只懂的是保持简单和通用是好的设计。
前段时间提要实现一个功能,是Unit有关response filter的,但没有被允许,这种设计目前组里只有nginx作者Igor的设计让人最放心。其它人都能做,包括我,但是设计出来的东西要做到简单和通用,还是差点功力。
以前也经历过这个阶段:学会复杂的功能,并觉得是干货。建议多思考,多原创,多看优秀的作品,及早突破一些认识的局限。
实现解析逻辑
解析的结果是产生中间码,引入parser对象方便解析。
- function calc_parse(text) {
- var parser = {
- text: text,
- pos: 0,
- token: {},
- code: []
- };
- next_token(parser);
- if (calc_parse_expr(parser, 2)) {
- return null;
- }
- if (parser.token.val != TOK_END) {
- return null;
- }
- parser.code.push(OP_END);
- return parser.code;
- }
对那些分散的信息,要考虑用聚集的方式比如对象,放在一起处理。这也是高内聚的一种体现。
前面提到简化是一种能力。
简化1: 能从text里找出(所有的)token。实现下next_token()。
- var TOK_END = 0,
- TOK_NUM = 1;
- function next_token(parser) {
- var s = parser.text;
- while (s[parser.pos] == ' ') {
- parser.pos++;
- }
- if (parser.pos == s.length) {
- parser.token.val = TOK_END;
- return;
- }
- var c = s[parser.pos];
- switch (c) {
- case '1': case '2': case '3': case '4':
- case '5': case '6': case '7': case '8':
- case '9': case '0':
- parse_number(parser);
- break;
- default:
- parser.token.val = c;
- parser.pos++;
- break;
- }
- }
- function parse_number(parser) {
- var s = parser.text;
- var num = 0;
- while (parser.pos < s.length) {
- var c = s[parser.pos];
- if (c >= '0' && c <= '9') {
- num = num * 10 + (c - '0');
- parser.pos++;
- continue;
- }
- break;
- }
- parser.token.val = TOK_NUM;
- parser.token.num = num;
- }
每次调用next_token(),就能拿到当前的token,并且解析移动到下一个token的开始位置。
简化2:可以将运算符*和+当作同一级,但是这里篇幅有限,不贴中间实现过程
简化3: 分析逻辑,直到能清晰的表达,这也说明你足够理解它的本质了。
以"1 + 2 * 3 - 4"为例:
我们将整个字符串称为expression,里面的各块也是expression。表达式的表示是 expression: expression [op expression]。
因此 "1 + 2 * 3 - 4"是表达式,"2 * 3"也是表达式, "1"和"4"也是表达式。
注意*的优先级比+高,因为可以这样分析:
2 * 3是一个整体,操作数(2) 操作符(*) 操作数(3)
1 + 2 * 3也是一个整体,操作数(1) 操作符(+) 操作数(2 * 3)
依此类推。代码如下:
- var OP_END = 0,
- OP_NUM = 1,
- OP_ADD = 2,
- OP_SUB = 3,
- OP_MUL = 4,
- OP_DIV = 5;
- function calc_parse_expr(parser, level) {
- if (level == 0) {
- return calc_parse_unary(parser);
- }
- if (calc_parse_expr(parser, level - 1)) {
- return -1;
- }
- for (;;) {
- var op = parser.token.val;
- switch (level) {
- case 1:
- switch (op) {
- case '*':
- var opcode = OP_MUL;
- break;
- case '/':
- var opcode = OP_DIV;
- break;
- default:
- return 0;
- }
- break;
- case 2:
- switch (op) {
- case '+':
- var opcode = OP_ADD;
- break;
- case '-':
- var opcode = OP_SUB;
- break;
- default:
- return 0;
- }
- break;
- }
- next_token(parser);
- if (calc_parse_expr(parser, level - 1)) {
- return -1;
- }
- parser.code.push(opcode);
- }
- return 0;
- }
- function calc_parse_unary(parser) {
- switch (parser.token.val) {
- case TOK_NUM:
- parser.code.push(OP_NUM);
- parser.code.push(parser.token.num);
- break;
- default:
- return -1;
- }
- next_token(parser);
- return 0;
- }
注意:我们是边解析边产生中间码的。
实现之执行
执行就相对简单很多了,只要思路清晰。
- function calc_exec(code) {
- var i = 0;
- var stack = [];
- for (;;) {
- opcode = code[i++];
- switch (opcode) {
- case OP_END:
- return stack[0];
- case OP_NUM:
- var num = code[i++];
- stack.push(num);
- break;
- case OP_ADD:
- var op2 = stack.pop();
- var op1 = stack.pop();
- var r = op1 + op2;
- stack.push(r);
- break;
- case OP_SUB:
- var op2 = stack.pop();
- var op1 = stack.pop();
- var r = op1 - op2;
- stack.push(r);
- break;
- case OP_MUL:
- var op2 = stack.pop();
- var op1 = stack.pop();
- var r = op1 * op2;
- stack.push(r);
- break;
- case OP_DIV:
- var op2 = stack.pop();
- var op1 = stack.pop();
- var r = op1 / op2;
- stack.push(r);
- break;
- }
- }
- }
测试用例很重要
- function calc_run(text) {
- var code = calc_parse(text);
- if (code == null) {
- return null;
- }
- return calc_exec(code);
- }
- function unit_test(tests) {
- for (var i = 0; i < tests.length; i++) {
- var test = tests[i];
- var ret = calc_run(test.text);
- if (ret != test.expect) {
- console.log("\"" + test.text + "\" failed,",
- "expect \"" + test.expect + "\",",
- "got \"" + ret + "\"");
- }
- }
- }
- var tests = [
- {
- text: "123",
- expect: 123
- },
- {
- text: "1 + 2 + 3",
- expect: 6
- },
- {
- text: "10 - 1 - 11",
- expect: -2
- },
- {
- text: "1 + 2 * 3 - 4",
- expect: 3
- },
- {
- text: "1 + 2 * 3 - 4 / 2",
- expect: 5
- },
- {
- text: "",
- expect: null
- },
- {
- text: "a",
- expect: null
- },
- {
- text: "10 a ",
- expect: null
- },
- {
- text: "10 + ",
- expect: null
- },
- {
- text: " + 2",
- expect: null
- },
- ];
- unit_test(tests);
编程经验:一致性
每个代码里有意义的函数和变量都像人物一样。之前怎么命名,之后也一样,同样的意思不要有多余的表示。而且保持它们的出场顺序不变。
- var TOK_END = 0,
- TOK_NUM = 1;
- var OP_END = 0,
- OP_NUM = 1,
- OP_ADD = 2,
- OP_SUB = 3,
- OP_MUL = 4,
- OP_DIV = 5;
- function calc_run(text) {
- }
- function calc_parse(text) {
- }
- function calc_parse_expr(parser, level) {
- }
- function calc_parse_unary(parser) {
- }
- function next_token(parser) {
- }
- function parse_number(parser) {
- }
- function calc_exec(code) {
- }
- function unit_test(tests) {
- }
- var tests = [
- ];
- unit_test(tests);
https://github.com/hongzhidao/the-craft-of-programming
在开源浪潮下,写好的代码尤其重要!