8月21日,白玉兰开源联合示说网主办的“开源大数据技术线上meetup”特邀约大数据领域的前沿技术专家,就大数据存储的关键技术、挑战和当前应用展开交流讨论,阵容强大、内容全面。第四范式体系架构科学家,高性能计算Team leader卢冕,一直专注于研发在异构架构下的系统优化实践和探索,我们根据卢冕讲师的现场分享《现代存储架构下的系统优化实践》,整理成以下内容。
一、前言
随着存储技术的发展,现代存储架构呈现出了前所未有的分级复杂性和功能上的革命(比如内存数据持久化),因此也对上层软件如何优化提出了新的挑战。
本次分享基于我们的实践经验,从现代存储架构的概念、特征工程数据库在PMem上的优化、基于分级存储架构的Kafka优化、MemArk技术社区这四个方面出发,演示如何在现代存储架构下,通过创新性的技术,比如持久化内存数据结构、分级存储、冷热数据分离等技术进行系统优化,以利用现代存储架构的特性。
一、现代存储架构
首先着眼于关键存储技术:硬件技术、软件技术,在此可划分成外存和内存。
1外存
例如SSD、硬盘,即数据可以在该设备上持久化。1956年已出现机械硬盘,NAND Flash在1989年开始首个专利申请。如今,Flash已经发展迅猛、应用广泛,例如B+tree数据库系统在1973年已繁荣发展。
2内存
直接将数据存储并且读写较快,但是掉电会造成数据丢失。内存的典型技术,例如SRAM、DRAM,其中SRAM用于CPU的cache,DDR、GDDR普遍应用于计算机。由于追求高性能、高吞吐,特异化的内存技术应运而生,例如,HBM2、GDDR6,上述都是高带宽、高吞吐的内存形态,在家用机器上运用较少,较多运用在数据中心和大密度计算。
在2015年,数据可持久化和高性能易失性内存出现在交汇融合,非易失性内存技术由此进入大众视野。该技术是存储架构的革命性变化。
3非易失性内存技术
2015年,英特尔和镁光在工业界共同提出了3D XPoint,目的是为了把非易失性内存技术落实到工业界,而不是仅限于学术界的模拟研究和讨论。
2018年,英特尔把非易失性内存技术实现了商业化,推出了傲腾持久内存,这意味着非易失性内存真正实现了落地,能围绕商业化产品去做工业级应用,而不是止步于纸上谈兵。
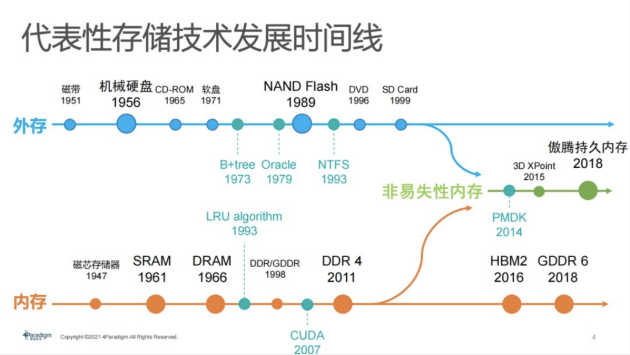
4现代存储架构金字塔
Computer Science课本中也会碰到过存储架构金字塔,其组织架构较简单。在课本上,底层是硬盘,中间是DRAM或者叫内存,上面是cache。实际上,今天工业界存储架构金字塔已经演化得非常复杂,它不再是课本上简单的两三级结构,已演化到六七级,此处还不包括异构算力所带来的存储架构。
如图:金字塔下面蓝色部分具有持久性,上面红色部分是存储介质。最特殊的是,中间部分非易失性内存或者持久内存商品,这一部分在金字塔用两种不同颜色已标注。内存数据的持久化特性具有革命性,是现今存储架构的显著特点。
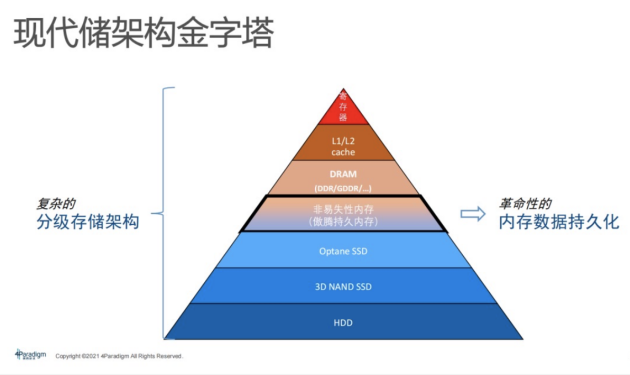
5非易失性内存
下图就是英特尔推出的傲腾持久内存(PMem)第一代和第二代。该内存条和普通的内存条没太大区别,可直接插在server上的内存插槽里,但只能匹配英特尔CPU。
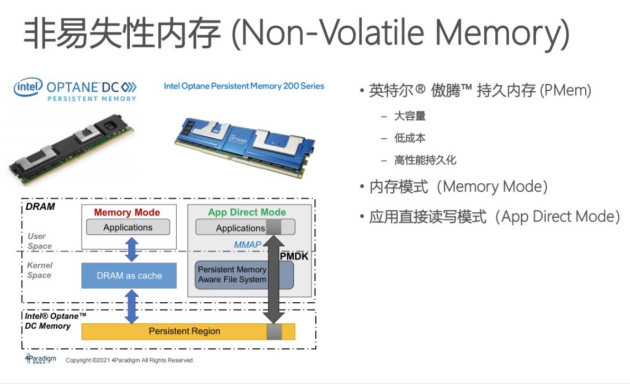
傲腾持久内存的显著特点:
·大容量:单根容量可达到512 GB,在server上很容易把它配到T级别的容量,即1.5T或3T容量的PMem服务器配置。
·低成本:单位价格即每GB成本比普通DRAM低。如果从 server角度去思考问题,例如,如果用DRAM去跑3T的应用,可能至少要七八台机器;如果用PMem机器去跑,它只需要一台机器。从机器数量和运营成本节省角度而言,低成本特征显著。
·高性能持久化:内存数据持久化。把传统软件中的内存数据做持久化,具有快速恢复的意义。此外,也可作为存储,其性能相比较于HDD、SSD,性能优势明显。
持久内存的工作模式:Memory Mode,即内存模式,持久内存直接插到server上,对应用程序是黑盒化的。整个server容量会变成持久内存的容量,DRAM会变成持久内存的一层cache。内存容量就是整个PMem的容量,应用程序不需要修改代码便可直接使用,直接享受大容量低成本的好处。但是这种模式可能会造成几个问题,存储架构的层级对程序员透明,程序员无法精确操控存储架构层级,从而无法去做细粒度优化,例如cache层级优化。为了克服以上问题,推了APP Direct Mode。在APP Direct Mode,可以看到从PMem到DRAM内存整个存储层级完全暴露在程序员视角下,程序员可以根据它的应用去做定制化优化,也能享受到持久化所带来的好处。
综上所述,现代存储架构的特点:分级存储架构复杂且丰富。现今存储层级已达5-7层,这会让大众在容量、性能和成本之间权衡利弊,即在容量、性能、成本之间取舍。挑战在此也迎面而来,即做优化。引入分级存储、分级持久化等分级缓存算法来更好地做系统优化。
在此强调的是:内存数据持久化,这是革命性功能。如果把PMem当做内存使用,一旦机器掉电或者程序崩溃,只要做好了持久化工作,在下次重新上电时,数据还是会持久化在内存中。优势就是内存数据的快速恢复。现实生活中,像线上服务,如果节点离线,数据要从外存或者从网络中重新拉回来做内存数据的构建,这非常影响线上服务质量。因为线上服务不允许长时间离线,若用持久内存,它就会持久化。在掉线以后,该线上节点恢复。基于此,对现在传统软件最大挑战是需要做持久化编程模型。
总而言之,分级存储架构和内存数据持久化,需要做一些传统软件的系统优化。
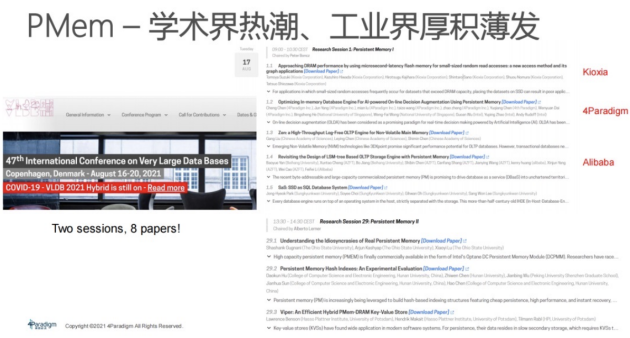
PMem在学术界非常火热,今年在丹麦举行的国际顶级数据库学术会议VLDB就有两个专门收录PMem相关论文的research sessions,共有8篇paper,出现了井喷。这些paper有工业界的影子,例如第一篇论文是做SSD的厂商。从工业界的角度来看,加之英特尔的推介,包括像第四范式、阿里巴巴也在做积极探索。在工业界,在接下来的1-2年内,PMem会普遍进入数据中心采购名单,会迎来非常大规模应用热潮。
6第四范式在现代存储架构上一些技术实践
对内:面向AI流程的优化。这里有两种用法:Memory Mode(为了低成本扩容)和HyperPS(针对推理的参数服务器)。
对外:除了对内部产品优化,也开始对外开源,目的是把核心技术往外推,让更多企业开发者能够意识到异构多级存储、现代存储架构上带来的优化工作,也可以推进持久内存的普及。
对内+对外:(已开源工作)。VLDB 2021:主要是针对特征工程数据库,做基于PMem的优化,核心持久化跳表即将合入PMDK核心库,这在国内是领先的。基于Pafka的Kafka优化:10x性能提升,且无需修改代码。还有一些打算开源、正在开发中的工作,例如OpenEmbedding,就是针对训练的参数服务器,它是和TensorFlow整合,方便快捷,包括向量、Elasticsearch、PMemStore、OpenMLDB,OpenMLDB就是已经开源的特征工程数据库。这两者整合起来,会在明年进行开源。另一方面,第四范式和英特尔也在打造代化存储架构的技术社区MemArk。

7面向AI全流程的异构存储优化
从第四范式的产品角度看,主要包含了离线训练和在线推理。在离线训练中,对内存消耗量会特别高,所以会做低成本扩容工作,使用PMem做内存扩容。在线推理中,因为它对性能要求高,有持久化需求,所以会用AD Mode在参数服务器、特征功能数据库、消息队列方面去做优化。
PMem具体如何使用?其实是取决于实际情况去做优化。
二、特征工程数据库在PMem上的优化
下图讲了特征工程数据库用在哪里。
从第四范式的角度,它大部分用于决策场景。例如,反欺诈、反洗钱以及推荐系统。
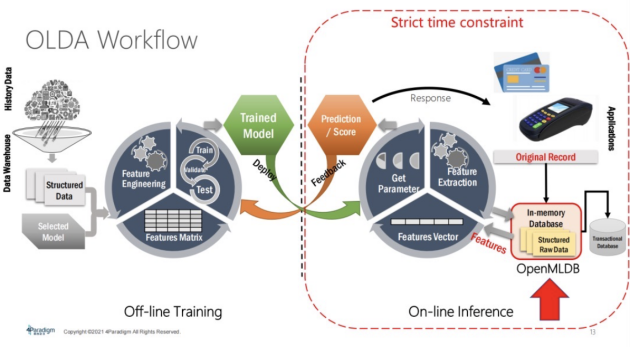
如下图,左边是Off-line Training,右边是On-line Inference。那么Off-line Training的特征在哪里?其实就在这OpenMLDB, 当在线请求产生一条数据记录时,它就会去做一个实时的特征抽取,产生额外的有用的特征,然后这个特征抽取会为 On-line Inference系统去做模型推理,所以它是在线场景下关键组件。因为它是在线系统,所以它有强的时间限制,延时不能太高。在此,我们更关注于OpenMLDB怎么去做性能优化以及做持久内存优化。
接下来着重介绍什么是特征(features)。特征在决策类场景中非常重要,一般从在线请求中产生的数据并不能直接去用来做推理,而是需要进一步做特征抽取。例如,我们需要拿到当前交易产生之前10秒、1分钟、5分钟内产生的交易做多的商店信息,这些都是通过实时的特征抽取拿到的而不能提前计算出来。所以这些基于时间窗口的实时特征抽取,就是在线特征工程。
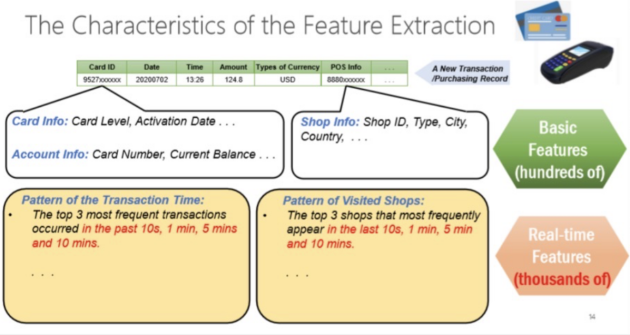
Future Extraction会有挑战:
第一,它大部分的特征不能被提前算好,例如一个交易,要算当前这个点往前推的时间窗口里面的信息,可能一分钟或者一小时或者几天的时间信息。这跟当前发生的时间状态是有关系的,所以不能去做提前处理。
第二,特征抽取会基于很多个时间窗口,计算量会比较高。
第三,此时会有很多特征产生,为了做在线推理,传统商业数据库并不能满足需求,一个是随着时间窗口的增长,Latency会增长得非常快,那么它性能很快就会超过几十个milliseconds,这可能会影响到线上服务质量,这种情况下它就不符合线上服务需求。
综上所述,我们需要去开发一个专门面向人工智能决策场景的特征工程数据库。

在这个大背景下,对于第四范式而言,OpenMLDB的设计包含两方面:第一,它提供FEQL引擎,FEQL引擎提供了FEQL语法,FEQL语法类似于SQL-like language。但是它可以更好地支持,比如基于时间窗口的特征抽取。第二,从存储引擎角度来讲,使用了双层跳表结构,去支持专门为时间窗口查询来做一些优化。
FEQL语法与SQL基本相似。除了有如Time_Window比较特殊的、专门给时间窗口查询做的语法,也会针对此类语法做优化。
底层的存储引擎结构是双层的 Skiplist。
基于这些优化,OpenMLDB它本身相比较于其他的database,就具有非常大的性能优势。同样与前面的DB-X、DB-Y相比,性能优势非常大,它性能上的 Latency,延迟能符合线上服务的需求。
基于OpenMLDB,我们DRAM版本的OpenMLDB也看到两大痛点:
第一,是因为OpenMLDB是为了线上推理用的,线上推理为了达到高性能的一般数据和索引都会放在内存当中,为了能够及时响应,这对内存需求会特别高。运用一个实际的银行反欺诈业务场景,这里只有三个月的数据量,该数据可能需要占用10TB,如果用普通DRAM去搭建,成本很高。而且部分客户反映,他们并不是为了性能而去扩展设备数量、机器资源,而只是为了能兜住内存容量,他们需要配备可能十几台机器,才能去兜住OpenMLDB。
第二,OpenMLDB都有把 data通过snapshot或者binlog这种方式,也就是Sync到磁盘、外部存储,去做数据备份。那么当这个操作发生时,它就会对延迟性能带来很大影响。因为大部分操作都会在内存中,但是当 Sync操作发生时,就会涉及到磁盘,由此产生长尾的延迟效应。
OpenMLDB是为了在线服务所设计的,需要保证线上服务质量,不允许线上的节点过长时间离线。在这种背景下,如果节点离线,则需要从网络磁盘中去重新拉回来去构建内存数据,由此恢复的时间会比较长。
因此,在该种情况下需要用PMem优化OpenMLDB。
PMem的用法有多种:数据和 index放在DRAM,log Snapshot存在外存。其中最简单的用法是把PMem当成memory mode,这种用法可以通过大容量解决成本问题,但无法享受内存数据持久化带来的快速恢复优势。
所以需要进一步通过AD mode做OpenMLDB优化,在这种优化情况下,整个系统数据库架构将发生改变,DRAM版本的OpenMLDB,需要将log Snapshot持久化到外部存储上。
在这种模式下,由于整个内存具有持久化功能,所以不需要将数据持久化到外存上。内部的Skiplist跳表数据结构具有持久化功能,数据会整体持久化在内存中。
显然,这有诸多优势,第一,没有 Sync的过程。第二,掉电后数据会立即从内存中恢复,无需漫长的时间恢复。
然而,这会遇到一个问题:如何保证持久化、语义的正确性和高效性。
其中最主要问题就是做Compare-And-Swap操作,在很多系统中去做无锁的并发情况,其实在 OpenMLDB里面也应用。在PMem环境下,CAS操作其实并不具有持久化语义。在多线程情况下,它会对Data inconsitency造成问题。
举个例子,第一个Thread进行Compare-And-Swap操作,第二个Thread基于计算出来的 t值做特征工程计算,然后把计算出来的特征进行flush。t1的值本来也应该被flush到 PMem,但可能在这个点掉电或者程序崩溃。在这种情况下,f1计算出来的特征被刷到了持久内存当中,然而原来的数据t1反而没有,这就造成了data inconsistency。
为了解决Compare-And-Swap问题,提出了Persistent-Compare-And-Swap。解决的思路是进行flush on read操作,每次做read时都去做持久化操作,能从根本上解决正确性问题。但是它会引入比较大的overhead,因为对每一个read都进行flush显然不对,某些read根本无需这样做。
在此情况下,本文引入smart pointer技术,即智能指针。在x86的架构上,内存地址要求八字节对齐,指针所指向的地址的最后三位一直是0。将三位的最后一位作为dirty的 flag,用于标记数据是否已被flush,如果已被flush,就无需再做 flush操作。基于该技术,可以做 persistent 操作,同时避免无效的、多余的、多次的flush持久化操作。
对于FEDB,本文使用真实的银行反欺诈数据,数据共有10TB,这里是一些优化过的不同版本。(在Paper里面称FEDB,开源以后叫open MLDB,所以表格里还是FEDB。)
首先,从性能角度来看,相较于这些传统的这种数据库,不管是DRAM版本的FEDB还是PMem版本的FEDB,都会达到相当好的性能。
基于 PMem版本优化有诸多优势:
一是long tail latency方面。黄色柱子和蓝色柱子分别代表了DRAM版本和典型的PMem版本,在 TP-99999标准下的long tail latency,大概有20%的性能改进。
二是 recovery time方面。基于DRAM需要6个小时才能完成一个完整的镜像恢复,但如果基于内存做持久化OpenMLDB,只需一分钟就能从内存重新恢复。其次,从CPU的角度来看,节省了一半左右的成本投入。
三、基于分级存储架构的Kafka优化
Kafka广泛用于大数据处理、人工智能,主要用于消息传输日志的搜集。Kafka架构具有高性能、高可扩展、高可用的特性。然而,由于它的logo文件需要做持久化,所以当压力上来时,无论是latency还是super都会受限于存储设备。
Pafka是Kafka的优化版本,Pafka版本在存储方面进行了优化。首先,由于整体上基于Kafka架构,所以客户业务代码是零迁移成本,他们无需做任何改造,即可零成本迁移到Kafka平台上,使用持久内存的Pafka可当做持久设备。它可打破性能瓶颈,在成本和性能上都有大幅度的提升。
从具体实现角度来讲,本来是通过这个文件 channel去存储到外部存储HDD或者SSD上,现在是通过PMDK将Kafka的 broker和 SEGMENT的存储,,将它赋能为可存储在PMem上。
在此,引入 MixChannel的概念,它不仅可存储在单一介质,还可以存储在PMem或者存储在第二级的外存上。例如,考虑到PMem的容量比较小,可以同时用 PMem和SSD或者HDD。
怎样把容量都用起来,保证一定的性能优势?在此引入分级存储的概念,然后引入数据迁移策略,将冷热数据分开存储,希望大部分热数据的读写能落到PMem上,冷数据落到速度比较慢的存储设备上。这个特性会在0.2.0版本中引入,在这个月底或者下个月初发布。现在的0.1.1版本全部存在PMem上。
0.1.1版本使用PMem做整个Kafka的性能兜底,是性能优化的表现。相比于 HDD或者SSD,它具有非常大的性能优势,例如SATA SSD,可以达到将近20倍的性能改善。
Pafka工作是下半年的重点工作,目前0.1.1版本已经开源,可以去试用,包括跟其他partner的合作,也已开始测试性能。0.1.1版本引入了PMem作为持久化介质,但并没有真正引入分级存储的概念。在0.2.0版本,会引入分级存储和数据迁移机制,能够在性能和容量上达到权衡,希望在数据量要求比较大的场景下,也能达到加速效果。
四、MenArk社区
该社区由第四范式主导创立,英特尔是赞助者之一。MenArk社区主要关注先进的存储架构技术,基于现代化存储架构为一些流行的开源软件做系统性优化。例如,Kafka、数据库系统、社区,将来都会去做优化工作。MenArk社区是一个开放性社区,欢迎合作伙伴的加入。同时,在此可以查看开源项目,主要包括:Kafka、OpenMLDB、PMems。