Kubelet 出于对节点的保护,允许在节点资源不足的情况下,开启对节点上 Pod 进行驱逐的功能。最近对 Kubelet 的驱逐机制有所研究,发现其中有很多值得学习的地方,总结下来和大家分享。
Kubelet 的配置
Kubelet 的驱逐功能需要在配置中打开,并且配置驱逐的阈值。Kubelet 的配置中与驱逐相关的参数如下:
- type KubeletConfiguration struct {
- ...
- // Map of signal names to quantities that defines hard eviction thresholds. For example: {"memory.available": "300Mi"}.
- EvictionHard map[string]string
- // Map of signal names to quantities that defines soft eviction thresholds. For example: {"memory.available": "300Mi"}.
- EvictionSoft map[string]string
- // Map of signal names to quantities that defines grace periods for each soft eviction signal. For example: {"memory.available": "30s"}.
- EvictionSoftGracePeriod map[string]string
- // Duration for which the kubelet has to wait before transitioning out of an eviction pressure condition.
- EvictionPressureTransitionPeriod metav1.Duration
- // Maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
- EvictionMaxPodGracePeriod int32
- // Map of signal names to quantities that defines minimum reclaims, which describe the minimum
- // amount of a given resource the kubelet will reclaim when performing a pod eviction while
- // that resource is under pressure. For example: {"imagefs.available": "2Gi"}
- EvictionMinimumReclaim map[string]string
- ...
- }
其中,EvictionHard 表示硬驱逐,一旦达到阈值,就直接驱逐;EvictionSoft 表示软驱逐,即可以设置软驱逐周期,只有超过软驱逐周期后,才启动驱逐,周期用 EvictionSoftGracePeriod 设置;EvictionMinimumReclaim 表示设置最小可用的阈值,比如 imagefs。
可以设置的驱逐信号有:
- memory.available:node.status.capacity[memory] - node.stats.memory.workingSet,节点可用内存
- nodefs.available:node.stats.fs.available,Kubelet 使用的文件系统的可使用容量大小
- nodefs.inodesFree:node.stats.fs.inodesFree,Kubelet 使用的文件系统的可使用 inodes 数量
- imagefs.available:node.stats.runtime.imagefs.available,容器运行时用来存放镜像及容器可写层的文件系统的可使用容量
- imagefs.inodesFree:node.stats.runtime.imagefs.inodesFree,容器运行时用来存放镜像及容器可写层的文件系统的可使用 inodes 容量
- allocatableMemory.available:留给分配 Pod 用的可用内存
- pid.available:node.stats.rlimit.maxpid - node.stats.rlimit.curproc,留给分配 Pod 用的可用 PID
Eviction Manager 工作原理
Eviction Manager的主要工作在 synchronize 函数里。有两个地方触发 synchronize 任务,一个是 monitor 任务,每 10s 触发一次;另一个是根据用户配置的驱逐信号,启动的 notifier 任务,用来监听内核事件。
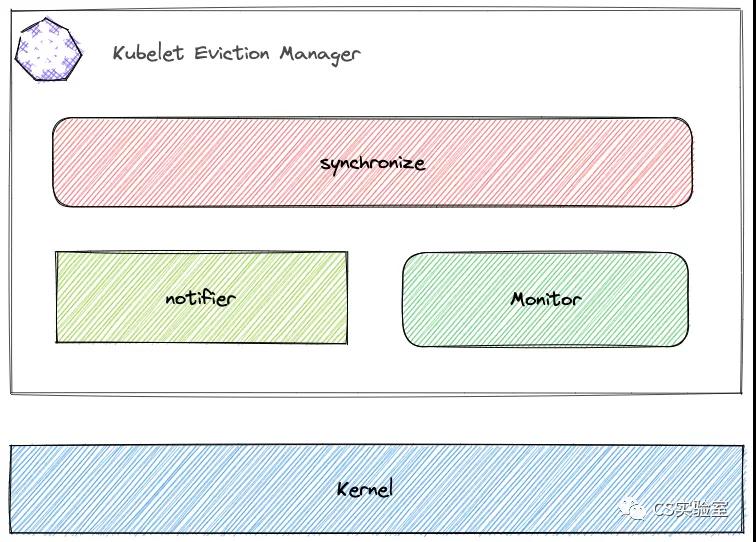
notifier
notifier 由 eviction manager 中的 thresholdNotifier 启动,用户配置的每一个驱逐信号,都对应一个 thresholdNotifier,而 thresholdNotifier 和 notifier 通过 channel 通信,当 notifier 向 channel 中发送消息时,对应的 thresholdNotifier 便触发一次 synchronize 逻辑。
notifier 采用的是内核的 cgroups Memory thresholds,cgroups 允许用户态进程通过 eventfd 来设置当 memory.usage_in_bytes 达到某阈值时,内核给应用发送通知。具体做法是向 cgroup.event_control 写入 "
notifier 的初始化代码如下(为了方便阅读,删除了部分不相干代码),主要是找到 memory.usage_in_bytes 的文件描述符 watchfd,cgroup.event_control 的文件描述符 controlfd,完成 cgroup memory thrsholds 的注册。
- func NewCgroupNotifier(path, attribute string, threshold int64) (CgroupNotifier, error) {
- var watchfd, eventfd, epfd, controlfd int
- watchfd, err = unix.Open(fmt.Sprintf("%s/%s", path, attribute), unix.O_RDONLY|unix.O_CLOEXEC, 0)
- defer unix.Close(watchfd)
- controlfd, err = unix.Open(fmt.Sprintf("%s/cgroup.event_control", path), unix.O_WRONLY|unix.O_CLOEXEC, 0)
- defer unix.Close(controlfd)
- eventfd, err = unix.Eventfd(0, unix.EFD_CLOEXEC)
- defer func() {
- // Close eventfd if we get an error later in initialization
- if err != nil {
- unix.Close(eventfd)
- }
- }()
- epfd, err = unix.EpollCreate1(unix.EPOLL_CLOEXEC)
- defer func() {
- // Close epfd if we get an error later in initialization
- if err != nil {
- unix.Close(epfd)
- }
- }()
- config := fmt.Sprintf("%d %d %d", eventfd, watchfd, threshold)
- _, err = unix.Write(controlfd, []byte(config))
- return &linuxCgroupNotifier{
- eventfd: eventfd,
- epfd: epfd,
- stop: make(chan struct{}),
- }, nil
- }
notifier 在启动时还会通过 epoll 来监听上述的 eventfd,当监听到内核发送的事件时,说明使用的内存已超过阈值,便向 channel 中发送信号。
- func (n *linuxCgroupNotifier) Start(eventCh chan<- struct{}) {
- err := unix.EpollCtl(n.epfd, unix.EPOLL_CTL_ADD, n.eventfd, &unix.EpollEvent{
- Fd: int32(n.eventfd),
- Events: unix.EPOLLIN,
- })
- for {
- select {
- case <-n.stop:
- return
- default:
- }
- event, err := wait(n.epfd, n.eventfd, notifierRefreshInterval)
- if err != nil {
- klog.InfoS("Eviction manager: error while waiting for memcg events", "err", err)
- return
- } else if !event {
- // Timeout on wait. This is expected if the threshold was not crossed
- continue
- }
- // Consume the event from the eventfd
- buf := make([]byte, eventSize)
- _, err = unix.Read(n.eventfd, buf)
- if err != nil {
- klog.InfoS("Eviction manager: error reading memcg events", "err", err)
- return
- }
- eventCh <- struct{}{}
- }
- }
synchronize 逻辑每次执行都会判断 10s 内 notifier 是否有更新,并重新启动 notifier。cgroup memory threshold 的计算方式为内存总量减去用户设置的驱逐阈值。
synchronize
Eviction Manager 的主逻辑 synchronize 细节比较多,这里就不贴源码了,梳理下来主要是以下几个事项:
- 针对每个信号构建排序函数;
- 更新 threshold 并重新启动 notifier;
- 获取当前节点的资源使用情况(cgroup 的信息)和所有活跃的 pod;
- 针对每个信号,分别确定当前节点的资源使用情况是否达到驱逐的阈值,如果都没有,则退出当前循环;
- 将所有的信号进行优先级排序,优先级为:跟内存有关的信号先进行驱逐;
- 向 apiserver 发送 驱逐事件;
- 将所有活跃的 pod 进行优先级排序;
- 按照排序后的顺序对 pod 进行驱逐。
计算驱逐顺序
对 pod 的驱逐顺序主要取决于三个因素:
- pod 的资源使用情况是否超过其 requests;
- pod 的 priority 值;
- pod 的内存使用情况;
三个因素的判断顺序也是根据注册进 orderedBy 的顺序。这里 orderedBy 函数的多级排序也是 Kubernetes 里一个值得学习(抄作业)的一个实现,感兴趣的读者可以自行查阅源码。
- // rankMemoryPressure orders the input pods for eviction in response to memory pressure.
- // It ranks by whether or not the pod's usage exceeds its requests, then by priority, and
- // finally by memory usage above requests.
- func rankMemoryPressure(pods []*v1.Pod, stats statsFunc) {
- orderedBy(exceedMemoryRequests(stats), priority, memory(stats)).Sort(pods)
- }
驱逐 Pod
接下来就是驱逐 Pod 的实现。Eviction Manager 驱逐 Pod 就是干净利落的 kill,里面具体的实现这里不展开分析,值得注意的是在驱逐之前有一个判断,如果 IsCriticalPod 返回为 true 则不驱逐。
- func (m *managerImpl) evictPod(pod *v1.Pod, gracePeriodOverride int64, evictMsg string, annotations map[string]string) bool {
- // If the pod is marked as critical and static, and support for critical pod annotations is enabled,
- // do not evict such pods. Static pods are not re-admitted after evictions.
- // https://github.com/kubernetes/kubernetes/issues/40573 has more details.
- if kubelettypes.IsCriticalPod(pod) {
- klog.ErrorS(nil, "Eviction manager: cannot evict a critical pod", "pod", klog.KObj(pod))
- return false
- }
- // record that we are evicting the pod
- m.recorder.AnnotatedEventf(pod, annotations, v1.EventTypeWarning, Reason, evictMsg)
- // this is a blocking call and should only return when the pod and its containers are killed.
- klog.V(3).InfoS("Evicting pod", "pod", klog.KObj(pod), "podUID", pod.UID, "message", evictMsg)
- err := m.killPodFunc(pod, true, &gracePeriodOverride, func(status *v1.PodStatus) {
- status.Phase = v1.PodFailed
- status.Reason = Reason
- status.Message = evictMsg
- })
- if err != nil {
- klog.ErrorS(err, "Eviction manager: pod failed to evict", "pod", klog.KObj(pod))
- } else {
- klog.InfoS("Eviction manager: pod is evicted successfully", "pod", klog.KObj(pod))
- }
- return true
- }
再看看 IsCriticalPod 的代码:
- func IsCriticalPod(pod *v1.Pod) bool {
- if IsStaticPod(pod) {
- return true
- }
- if IsMirrorPod(pod) {
- return true
- }
- if pod.Spec.Priority != nil && IsCriticalPodBasedOnPriority(*pod.Spec.Priority) {
- return true
- }
- return false
- }
- // IsMirrorPod returns true if the passed Pod is a Mirror Pod.
- func IsMirrorPod(pod *v1.Pod) bool {
- _, ok := pod.Annotations[ConfigMirrorAnnotationKey]
- return ok
- }
- // IsStaticPod returns true if the pod is a static pod.
- func IsStaticPod(pod *v1.Pod) bool {
- source, err := GetPodSource(pod)
- return err == nil && source != ApiserverSource
- }
- func IsCriticalPodBasedOnPriority(priority int32) bool {
- return priority >= scheduling.SystemCriticalPriority
- }
从代码看,如果 Pod 是 Static、Mirror、Critical Pod 都不驱逐。其中 Static 和 Mirror 都是从 Pod 的 annotation 中判断;而 Critical 则是通过 Pod 的 Priority 值判断的,如果 Priority 为 system-cluster-critical/system-node-critical 都属于 Critical Pod。
不过这里值得注意的是,官方文档里提及 Critical Pod 是说,如果非 Static Pod 被标记为 Critical,并不完全保证不会被驱逐:https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods 。因此,很有可能是社区并没有想清楚这种情况是否要驱逐,并不排除后面会改变这段逻辑,不过也有可能是文档没有及时更新??。
总结
本文主要分析了 Kubelet 的 Eviction Manager,包括其对 Linux CGroup 事件的监听、判断 Pod 驱逐的优先级等。了解了这些之后,我们就可以根据自身应用的重要性来设置优先级,甚至设置成 Critical Pod。