2018 年,谷歌发表了一篇题为《Pre-training of deep bidirectional Transformers for Language Understanding》的论文。
在本文中,介绍了一种称为BERT(带转换器Transformers的双向编码Encoder 器表示)的语言模型,该模型在问答、自然语言推理、分类和通用语言理解评估或 (GLUE)等任务中取得了最先进的性能.
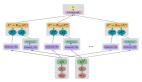
BERT全称为Bidirectional Encoder Representation from Transformers[1],是一种用于语言表征的预训练模型。
它基于谷歌2017年发布的Transformer架构,通常的Transformer使用一组编码器和解码器网络,而BERT只需要一个额外的输出层,对预训练进行fine-tune,就可以满足各种任务,根本没有必要针对特定任务对模型进行修改。
BERT将多个Transformer编码器堆叠在一起。Transformer基于著名的多头注意力(Multi-head Attention)模块,该模块在视觉和语言任务方面都取得了巨大成功。
在本文中,我们将使用 PyTorch来创建一个文本分类的Bert模型。
笔者介今天绍一个python库 --- simpletransformers,可以很好的解决高级预训练语言模型使用困难的问题。
simpletransformers使得高级预训练模型(BERT、RoBERTa、XLNet、XLM、DistilBERT、ALBERT、CamemBERT、XLM-RoBERTa、FlauBERT)的训练、评估和预测变得简单,每条只需3行即可初始化模型。
数据集来源:https://www.kaggle.com/jrobischon/wikipedia-movie-plots
该数据集包含对来自世界各地的 34,886 部电影的描述。列描述如下:
- 发行年份:电影发行的年份
- 标题:电影标题
- 起源:电影的起源(即美国、宝莱坞、泰米尔等)
- 剧情:主要演员
- 类型:电影类型
- 维基页面- 从中抓取情节描述的维基百科页面的 URL
- 情节:电影情节的长篇描述
- import numpy as np
- import pandas as pd
- import os, json, gc, re, random
- from tqdm.notebook import tqdm
- import torch, transformers, tokenizers
- movies_df = pd.read_csv("wiki_movie_plots_deduped.csv")
- from sklearn.preprocessing import LabelEncoder
- movies_df = movies_df[(movies_df["Origin/Ethnicity"]=="American") | (movies_df["Origin/Ethnicity"]=="British")]
- movies_df = movies_df[["Plot", "Genre"]]
- drop_indices = movies_df[movies_df["Genre"] == "unknown" ].index
- movies_df.drop(drop_indices, inplace=True)
- # Combine genres: 1) "sci-fi" with "science fiction" & 2) "romantic comedy" with "romance"
- movies_df["Genre"].replace({"sci-fi": "science fiction", "romantic comedy": "romance"}, inplace=True)
- # 根据频率选择电影类型
- shortlisted_genres = movies_df["Genre"].value_counts().reset_index(name="count").query("count > 200")["index"].tolist()
- movies_df = movies_df[movies_df["Genre"].isin(shortlisted_genres)].reset_index(drop=True)
- # Shuffle
- movies_df = movies_df.sample(frac=1).reset_index(drop=True)
- #从不同类型中抽取大致相同数量的电影情节样本(以减少阶级不平衡问题)
- movies_df = movies_df.groupby("Genre").head(400).reset_index(drop=True)
- label_encoder = LabelEncoder()
- movies_df["genre_encoded"] = label_encoder.fit_transform(movies_df["Genre"].tolist())
- movies_df = movies_df[["Plot", "Genre", "genre_encoded"]]
- movies_df

使用 torch 加载 BERT 模型,最简单的方法是使用 Simple Transformers 库,以便只需 3 行代码即可初始化、在给定数据集上训练和在给定数据集上评估 Transformer 模型。
- from simpletransformers.classification import ClassificationModel
- # 模型参数
- model_args = {
- "reprocess_input_data": True,
- "overwrite_output_dir": True,
- "save_model_every_epoch": False,
- "save_eval_checkpoints": False,
- "max_seq_length": 512,
- "train_batch_size": 16,
- "num_train_epochs": 4,
- }
- # Create a ClassificationModel
- model = ClassificationModel('bert', 'bert-base-cased', num_labels=len(shortlisted_genres), args=model_args)
训练模型
- train_df, eval_df = train_test_split(movies_df, test_size=0.2, stratify=movies_df["Genre"], random_state=42)
- # Train the model
- model.train_model(train_df[["Plot", "genre_encoded"]])
- # Evaluate the model
- result, model_outputs, wrong_predictions = model.eval_model(eval_df[["Plot", "genre_encoded"]])
- print(result)
- {'mcc': 0.5299659404649717, 'eval_loss': 1.4970421879083518}
- CPU times: user 19min 1s, sys: 4.95 s, total: 19min 6s
- Wall time: 20min 14s
关于simpletransformers的官方文档:https://simpletransformers.ai/docs
Github链接:https://github.com/ThilinaRajapakse/simpletransformers