select * from XXX where id=1;
这应该是n年前入门mysql必用的查询语句了吧,学如逆水行舟,不进则退,这么久过去了,你知道这条语句在Mysql内部的执行过程吗?
我们先来看看司空见惯的Mysql基本架构示意图
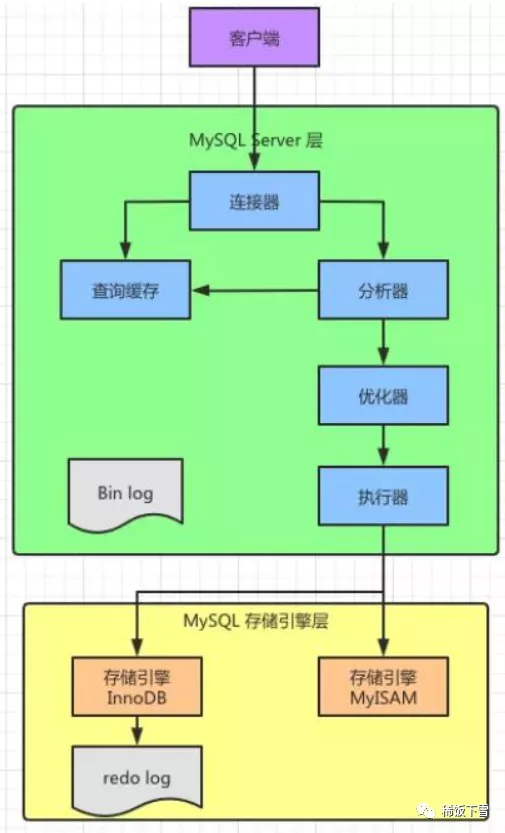
可以看到,Mysql可以分为
- Server层,包括连接器、查询缓存、分析器、优化器、执行器等,除了直接落地到磁盘、和从磁盘提取数据外的所有能力。
- 存储引擎层,负责了数据的读取和存储,支持InnoDB、MyISAM、Memory等多个存储引擎,默认的是InnoBD。
结构大概讲完了,有没有感觉,Mysql就像一个大型的加工厂,你把原材料,也就是sql语句放进去,然后Mysql就转动起来,从头到尾给你加工,最后得出一款产品,也就是执行结果。
嗯,这个比喻好,确实他妈的像,那么这个加工厂具体做了啥呢?
连接器小妹妹
首先,我们都会使用连接命令连上mysql
mysql -hip-pport -u$user -p
这个时候,出来接待我们的就是连接器小妹妹了
连接器小妹妹负责跟我们进行了典型的TPC握手,然后开始问我们的身份,要拿芝麻开门什么的密码来验证我们是否有权限,如果账户或者密码错误了,则会直接跟我们说
"Access denied for user“
验证通过了,则我们和连接器的连接便成功简历了,可以使用
show processlist
查看连接的状态

其中Sleep状态表明是空闲连接
连接建立后,连接器小妹妹还会告诉我们一些规则,比如
如果连接太长时间没动静,则会自动将连接断开,默认是8个小时
如果连接被断开了,等我吗再次发送请求的时候,连接器小妹妹则会告诉我们
Lost connection to MySQL server during query
那么能改吗?
可以的,只需要我们告诉连接器小妹妹,将wait_timeout的参数修改一下就可以了
听起来都是长连接,那么能进行短连接吗?
可以的,连接器小妹妹说了:
如果你们和我建立长连接的话,连接成功后,你们后续有请求,都会一直使用同一个连接。但是如果是短连接,则每次执行完很少的几次操作后我就要就断开连接了,下次再来你们再建立一次连接吧
我们也可以看到,其实和连接器小妹妹建立连接的过程是挺麻烦的,所以平常我们尽量会减少这个行为,一般都会使用长连接。
但是啊,有时候用着用着,mysql这边内存涨的特别快,这是为什么呢?我特地问了连接器小妹妹,她告诉我
mysql在执行过程中临时使用的内存是管理在连接对象里边的,而这些对象只有在连接断开的时候才释放,所以内存占用越来越大,最后有可能被系统强行干掉了,也就是OOM
丢,这么严重,那么我到底用长连接还是短连接呢?
肯定是长连接啦,别急,还是有解决办法的,我们这边给了两个方案
- 定期断开长连接,使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开 连接,之后要查询再重连。
- 如果你用的是MySQL 5.7或更新版本,可以在每次执行一个比较大的操作后,通过执行mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证, 但是会将连接恢复到刚刚创建完时的状态。
到了这里,连接器小妹妹的活就干完了,后面出来接待我们的是缓存查询小哥哥。
缓存查询小哥哥
缓存查询小哥哥也比较简单,一来就将我们的sql语句拿去做对比,他那边有个字典,用key-value的格式记录着查询过的key和结果,而他的做法也极其简单,只要找到一样的,则将结果给回我们了,只有当找不到记录,才会继续走后面的流程,然后继续记录到字典内。
这个时候,我就很疑惑了,如果实际上数据更新了,但是你的字典还是旧的怎么办呢?
缓存查询小哥哥说了,这个不用担心,字典上会记录着查询记录对应的表,如果对应的表有了更新,我这边就会将记录全部清空掉的。
哦,这样子,那么如果是更新比较频繁的情况,可能你的作用也不大哦哈哈哈
是的,你们可以通过
query_cache_type = DEMAND
将关闭掉的,而且在8.0开始,我已经被移除啦。
说完缓存查询小哥哥流下了悲伤的泪水,是啊,毕竟跟不上时代的技术,被淘汰也是难免的。
缓存查询小哥哥说完,便将另一位小哥叫了出来,这位小哥叫分析器。
分析器小哥哥
分析器小哥哥在拿到sql语句后,就开始自己捣鼓了起来,那么他具体做了啥呢?我们在旁边看捣鼓了很久,其实他就做了两步
第一步,词法分析,就是从SQL 语句中提取关键字,比如:查询的表,字段名,查询条件等等。
第二步,语法规则,就是判断SQL语句是否合乎MySQL的语法。
通过分析器小哥哥做的事情,我也明白了,其实词法分析就是将整个SQL语句拆分成一个个单词,而语法规则则根据MySQL定义的语法规则生成对应的数据结构,并存储在对象结构当中。
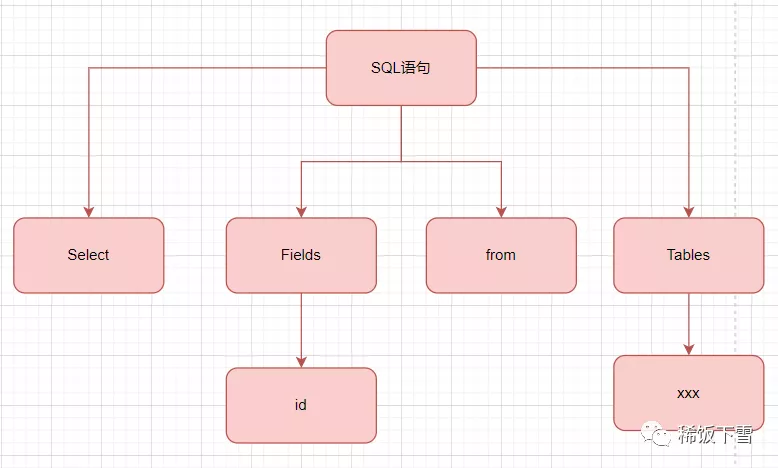
举个例子,假设有这样一个SQL语句“select id from XXX”。
先通过词法分析,从左到右逐个字符进行解析

然后再通过语法规则解析,判断输入的SQL 语句是否满足MySQL语法,并且生成语法树,语法树大概是这样的
优化器小姐姐
到了这里,优化器小姐姐已经知道我们要干嘛了 毕竟分析器小哥哥已经帮他分析好了,只是可能我们的语句不够优美,所以才需要知心的优化器小姐姐来做优化。
知心小姐姐怎么做的呢?我们看到小姐姐先将SQL语法树拿了出来,然后就开始工作了起来,不得不说,小姐姐工作的样子是真的好看,那么她具体做了啥呢?
在全程围观的我们,看到了她大概做了两件事
- 逻辑变化
- 代价优化
逻辑变化是啥呢?逻辑变换就是在关系代数基础上进行变换,其目的是为了化简,同时保证SQL变化前后的结果一致,也就是逻辑变化并不会带来结果集的变化。
其主要包括以下几个方面:
- 否定消除:针对表达式“和取”或“析取”前面出现“否定”的情况,应将关系条件进行拆分,从而将外层的“NOT”消除。
- 等值常量传递:利用了等值关系的传递特性,为了能够尽早执行“下推”运算。“下推”的基本策略是,始终将过滤表达式尽可能移至靠近数据源的位置。
- 常量表达式计算:对于能立刻计算出结果的表达式,直接计算结果,同时将结果与其他条件尽量提前进行化简。
总结下来就是替换和预处理啦。
代价优化呢?代价优化是用来确定每个表,根据条件是否应用索引,应用哪个索引和确定多表连接的顺序等问题,为了完成代价优化,需要找到一个代价最小的方案。
可以这说,我们要执行的查询都是通过代价优化来计算出来的,最终得出了最小代价计划去执行。
优化好后,接下来就是我们的执行器大哥出马了。
执行器大哥
到了这一步,就要准备执行了,开始执行的时候,执行器大哥会一脸严肃的翻看他的权限宝典
查看我们是否有执行查询的权限,如果没有,则会直接告诉我们
SELECT command denied to user 'root'@'localhost' for table 'XXX'
如果验证没问题,他则会根据表的引擎信息,判断要调用哪种引擎接口
例如SQL:select * from XXX where id=1;
假设 “id“ 字段没有设置索引,就会调用存储引擎从第一条开始查,如果碰到了id是1, 就将结果集返回,没有查找到就查看下一行,重复上一步的操作,直到读完整个表或者找到对应的记录。
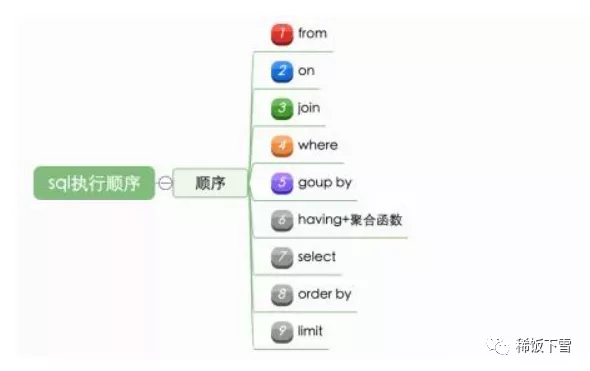
执行器还画了个草图解释了他一贯的执行顺序
最后
一条查询命令到了这里就算结束了,大致介绍了查询请求的执行流程,引入了连接器、查询缓存、分析器、优化器、执行器几兄弟的分工合作,最后,我们为即将消失的查询缓存器弟弟默哀三分钟......
本文转载自微信公众号「稀饭下雪」