大规模系统的分片部署是一个难点,既要考虑容灾和故障转移,又要考虑负载均衡和资源利用率。本文就从服务状态、故障转移、负载及资源利用率等几个方面来阐述下他们的关系,并带大家一起看下,facebook面对这种挑战是怎么做系统架构的~
1有状态&无状态的服务部署
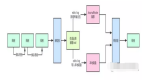
应用服务,根据其类型一般可以分为两种:无状态服务 和 有状态服务
无状态的服务,扩展起来其实比较容易,用流量路由等负载均衡方式即可实现;
但是有状态服务不太容易,让所有服务器一直能够持有全部数据时不现实的。
-- 散列是一种方案 --
如一致性散列策略,将数据散列部署。但是,一致性散列会存在一些不可避免的问题,主要有数据倾斜、数据漂移等。虽然我们可以通过将某节点的一部分数据移到其他节点来解决,但这需要非常细粒度的负载统计标尺来进行发现和衡量。

来源:百度百科
另外,由于一致性散列对多数据中心的支持不太友好,比如,希望让某些区域的用户走特定数据中心,以降低延迟的话,用该策略不好实现。
-- 分片是另一种方案 --
其目的是支持业务增长、应对系统的高并发及吞吐量。并且加载和使用更加灵活。

来源:fb engineering
数以万计、亿计的数据分散存储在多个数据库实例中,则每个实例都叫一个分片。另外,为了容错,每个分片都可以有多个副本,而每个副本根据不同的一致性要求可以分为主副本和从副本。
然后,分片又通过多种策略规范,显示计算出到服务器的映射,以向用户提供完整的服务。这些策略规范包括:不同用户ID选择不同的服务分区、不同地理位置的请求分散到较近的数据中心等等。
从这个要求来看,分片的方式要比散列更灵活,更适用大型服务部署。
2故障是一种常态
在分布式环境下,我们对故障需要有清晰的认知--故障的发生不应该被当成是小概率事件,而应该被当成一种常态。
这也是系统设计应该遵守的一个前提条件。这样系统才有可能更加稳固。
所以,服务的容错能力、从故障中恢复的能力,是实现服务高可用的关键。
那可以有哪些措施呢?
-- 复制 --
数据、服务的冗余部署,是提高容错能力的常用手段。比如服务主备和数据库主从。
但是有些情况下,这种方式是可以打商量的。如果单个容错域的故障会导致所有冗余副本宕机,那复制还有啥作用?
-- 自动检测 & 故障转移 --
想要高可用,故障的发现和自动检测机制是前提。然后才是故障转移。
故障转移的快慢,决定了程序的可用性高低。那么,所有的故障都必须立马进行转移才能达到最好的效果么?
也不竟然。
如果新副本的构建成本非常大呢?比如要加载庞大的数据量资源等等,指不定还没构建完,原故障机器就恢复了说不定。
-- 故障转移限流 --
一个服务挂了不是最可怕的,最可怕的是它能把全链路都带崩。就比如上一篇文章中写的《Zookeeper引发的全链路崩溃》一样,级联问题,绝对不容小觑!
因此,在进行故障转移时,要给予这个问题足够的重视,以免引发正常服务在脉冲流量下崩盘。
3资源是宝贵的,不浪费才最好
就算是阿里的财大气粗,每个季度也会有运维同学和业务同学,因为1%的CPU利用率,在服务容器数量分配上来回博弈好多次。
业务同学当然是想机器越多越好,因为机器越多,单节点的故障几率就可以小些;
而运维同学的任务则是尽可能提高资源利用率。毕竟有那么多要买718、911的。。。不都得钱么~
-- 负载均衡 --
负载均衡是指在应用服务器之间持续均匀地分布分片及其工作负载的过程。它可以有效地利用资源,避免热点。
- 异构的硬件。由于硬件规格不同,服务所能承载的压力也不尽相同,因此需要考虑硬件限制来分配负载。
- 动态资源。比如可用的磁盘空间、空闲的CPU等,如果负载和这些动态资源绑定,那么不同的时间点,服务负载是不能一概而论的。
-- 弹性扩展 --
很多时候,我们的很多应用都是为用户提供服务的。而用户的行为随着作息呈现一定的规律性,如白天的访问量大,晚上的访问量小。
因此,弹性计算其实是在不影响可靠性的前提下提高资源效率的一种解决方案,即根据负载变化动态调整资源分配。
4Facebook怎么平衡上述诉求[1]
我们平常见到,其实不同的团队有不同的分片管理策略。比如,本地生活有一套自己的外卖服务分片的管理容灾方案、大文娱也有一套自己视频服务的分片管理。
facebook早期也是如此。不同团队间各有各的方案,但是这些方案都更偏重于解决故障转移,保障系统可用性,对负载均衡考虑较少。
这样的方式,其实对集团资源利用率、操作性上有些不适合。基于这样的考虑,facebook设计了一个通用的分片管理平台Shard Manager,简称 SM 。。。
距今,已经有成百上千的应用程序被构建或迁移到分片管理器上,在几十万的服务器上构建出总计超过千万的分片副本。。。
那么,我们来一起看下,他们是怎么做的。
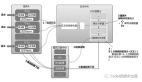
1、基础架构分层设计

facebook基础设施架构
Host management: 即主机管理,使用资源配额系统,管理所有物理服务器,并给各团队分配容量。
Container management: 每个团队从下层获取到容量后,以容器为单位将其分配给各个应用程序。
Shard management: 在下层提供的容器内为分片应用程序分配分片。
Sharded applications: 在每个分片中,应用程序分配并运行相关的工作负载。
Products: 上层应用程序。
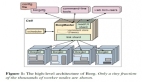
2、Shard Management整体架构
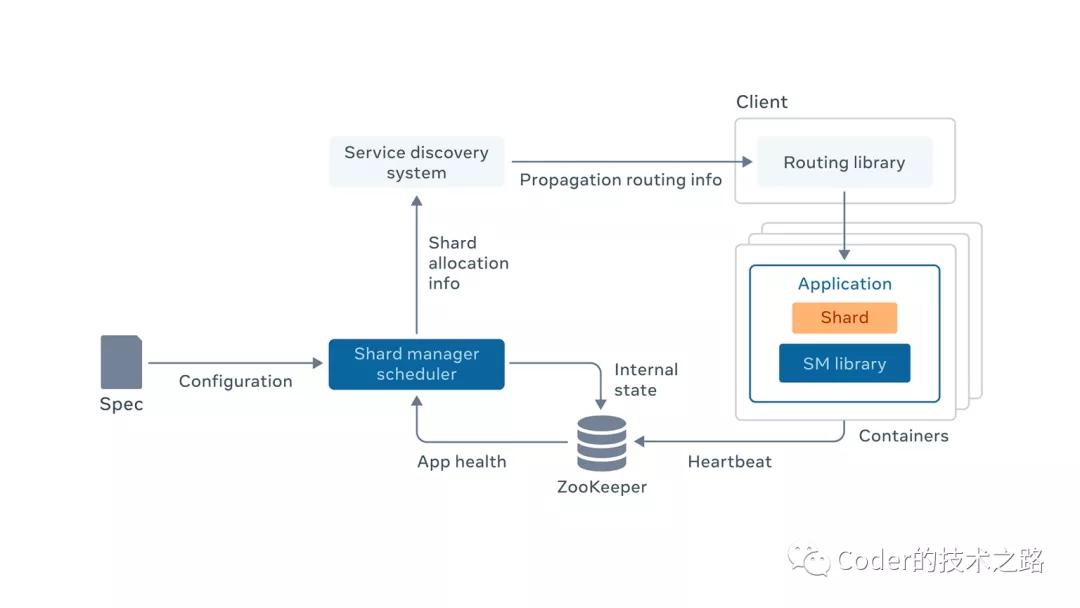
来源:fb engineering
应用程序实现分片状态转换接口(该接口由SM library定义,由应用程序实现),并根据调度程序的调用进行状态转换。
应用程序向 ZooKeeper 上报服务器成员资格和活动状态。由Shard Manager Scheduler 收集应用程序监测的自身动态负载信息。
Shard Manager Scheduler 是协调分片转换和移动的中央服务。它收集应用程序状态;监控服务器加入、服务器故障和负载变化等状态变化;通过对应用程序服务器的RPC调用来驱动分片状态转换,从而实现分片分配的调整。
Shard Manager Scheduler 将分片分配的公共视图发布到服务发现系统(该系统保障了自己的高可用和可扩展);
服务发现系统将信息传递到应用程序的客户端用于计算请求路由。
那么,Shard Manager Scheduler挂了怎么办呢?
一是,其内部可以进行分片扩展,来保证其高可用;
二是,由上述设计可知,中央处理程序不在客户端调用的关键路径上,即使挂了,应用程序还是可以以现有的分片来执行运转,业务不会受中央处理器宕机的影响。
3、标准化分片管理
为了实现上述架构,facebook定义了几个原语:
- //分片加载
- status add_shard(shard_id)
- //分片删除
- status drop_shard(shard_id)
- //主从切换
- status change_role(shard_id, primary <-> secondary)
- //验证和变更副本成员关系
- status update_membership(shard_id, [m1, m2, ...])
- //客户端路由计算和直连调用
- rpc_client create_rpc_client(app_name, shard_id)
- rpc_client.execute(args)
根据上述原语,通过组合,即可以合成高级分片移动协议:
如,我们希望将将分片A,从当前负载较高的服务器A,移动到负载较低的服务器B:
- Status status= A.drop_share(xx);
- if(status == success){
- B.add_share(xx)
- }
不仅是普通服务,对于主从切换、paxos协议的服务管理也可以用上述原语满足,有兴趣的同学可以自己试试组合一下,这个对我们工作中的系统设计时非常有帮助的。
那么,针对文章前半部分涉及到的一些分片管理的难点和问题,facebook在该架构下是怎么应对的呢?
对于容错中的复制,Shard Manager允许在每个分片上配置复制因子,以实现合理的复制策略,如果不需要复制,则可以通过复制因子来控制;
对于故障转移,Shard Manager通过配置故障转移延迟策略,来权衡新副本的构建成本和服务的不可用时间;
对于故障节流,Shard Manager支持限制分片故障转移速度,来保护其余健康服务器不会被冲垮;
对于负载均衡,Shard Manager支持根据硬件规格定制负载因子;通过定期收集应用程序每个副本的负载,来实现各实例间的平衡;并支持多资源平衡,确保短板资源可用。
对于弹性,Shard Manager支持分片缩放和扩展,针对不同流量实行不同的扩展速率。
参考资料
[1]fb engineering: "使用ShardManager扩展服务"