从 cpu 聊
起cpu (central process) 是计算机的大脑,它提供了一套指令集,我们写的程序最终会通过 cpu 指令来控制的计算机的运行。
cpu 会对指令进行译码,然后通过逻辑电路执行该指令。整个执行的流程分为了多个阶段,叫做流水线。指令流水线包括取指令、译码、执行、取数、写回五步,这是一个指令周期。cpu 会不断的执行指令周期来完成各种任务。
指令和数据都会首先加载到内存中,在程序运行时依次取到 cpu 里。cpu 访问内存虽然比较快,但比起 cpu 执行速度来说还是比较慢的,为了缓解这种速度矛盾,cpu 设计了 3 级缓存,也就是 L1、L2、L3 的缓存。
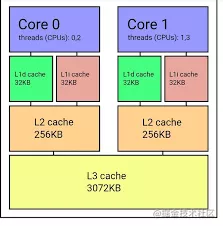
如图,多核 cpu 各核心都有自有独立的 L1、L2 缓存,然后共享 L3 缓存,这 3 级缓存容量是逐渐递增的,但是速度是逐渐下降的,但是也会比访问内存快一些。
有了这 3 级缓存以后,cpu 执行速度和访问内存速度的矛盾就可以得到缓解,不需要一直访问内存,cpu 每次会加载一个缓存行,也就是 64 字节大小的数据到缓存中。这样访问临近的数据的时候就可以直接访问缓存。
从内存中把数据和指令加载到 cpu 的缓存中,然后通过控制器控制指令的译码、执行,通过运算器进行运算,之后把结果写回内存。这就是 cpu 的工作流程。
cpu 每个核只有一个线程,也就是单控制流、单数据流。这样的架构导致 cpu 在一些场景下效率是不高的,比如 3d 渲染的场景。
3d 渲染流程
3d 的渲染首先是建立 3d 的模型,它由一系列三维空间中的顶点构成,3 个顶点构成一个三角形,然后所有的顶点构成的三角形拼接起来就是 3d 模型。

顶点、三角形,这是 3d 的基础。3d 引擎首先要计算顶点数据,确定 3d 图形的形状。之后还要对每个面进行贴图,可以在每个三角形画上不同的纹理。
3d 图形要显示在二维的屏幕上就要做投影,这个投影的过程叫做光栅化。(光栅是一种光学仪器,在这里就代表 3d 投影到 2d 屏幕的过程)
光栅化要计算 3d 图形投影到屏幕的每一个像素的颜色,计算完所有的像素之后会写到显存的帧缓冲区,完成了一帧的渲染,之后会继续这样计算下一帧。
也就是说,3d 渲染的流程是:
- 计算顶点数据,构成 3d 的图形
- 给每个三角形贴图,画上纹理
- 投影到二维的屏幕,计算每个像素的颜色(光栅化)
- 把一帧的数据写入显存的帧缓冲区
顶点的数量是非常庞大的,而 cpu 只能顺序的一个个计算,所以处理这种 3d 渲染会特别费劲,于是就出现了专门用于这种 3d 数据的并行计算的硬件,也就是 GPU。
GPU 的构成
和 cpu 的一个一个数据计算不同,gpu 是并行的,有成百上千个核心用于并行计算。
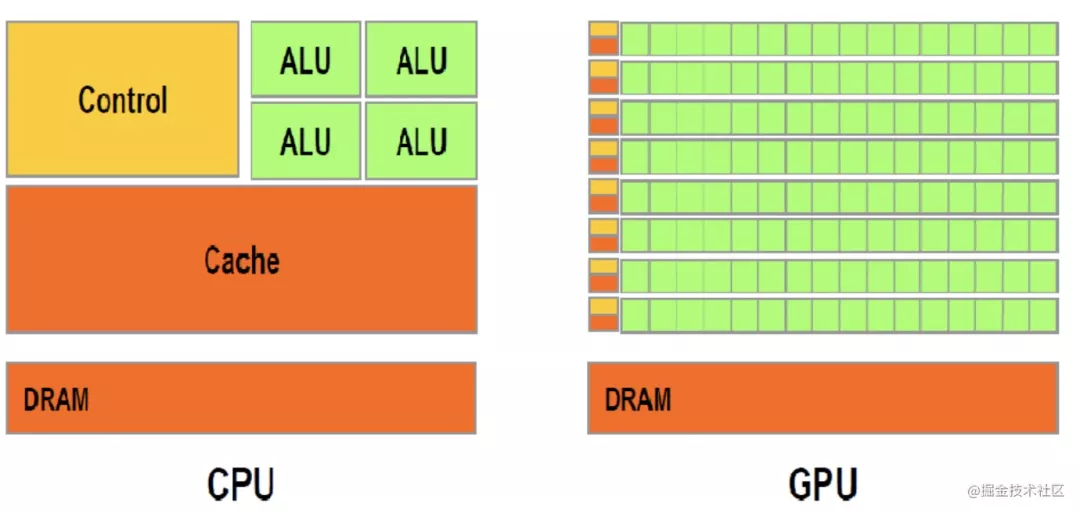
gpu 也是有着指令、译码、执行的流程,只不过,每个指令会并行执行 n 个计算,是单控制流多数据流的,而 cpu 是单控制流单数据流。
所以,对于 3d 渲染这种要计算成万个顶点数据和像素点的场景,GPU 会比 CPU 高效很多。
但是,gpu 全是优点么?也不是。
cpu 和 gpu 的区别
cpu 是通用的,能够执行各种逻辑和运算,而 gpu 则是主要是用于并行计算大批量的重复任务,不能处理复杂逻辑。
如上图,cpu 中控制器和缓存占据了很大一部分,而 gpu 中这两部分则很少,但是有更多的核心用于计算。
两者对比的话,cpu 相当于一个大学生,能够解决各种难题,但是计算 1 万个加法就没那么快,而 gpu 就像一帮小学生,解决不了难题,但是计算加法这种就很快,因为人多。
也就是说如果逻辑复杂,那么只能用 cpu,如果只是计算量大,并且每个计算都比较重复,那就比较适合 gpu。
3d 的渲染中有大量这种重复却简单的计算,比如顶点数据和光栅化的像素数据,通过 gpu 就可以并发的一次计算成百上千个。
opengl、webgl、css 硬件加速
显卡中集成了 gpu,提供了驱动,使用 gpu 能力需要使用驱动的 api。gpu 的 api 有一套开源标准叫做 opengl,有三百多个函数,用于各种图形的绘制。(在 windows 下有一套自己的标准叫做 DirectX)
我们在网页中绘制 3d 图形是使用 webgl 的 api,而浏览器在实现 webgl 的时候也是基于 opengl 的 api,最终会驱动 gpu 进行渲染。
css 大部分样式还是通过 cpu 来计算的,但 css 中也有一些 3d 的样式和动画的样式,计算这些样式同样有很多重复且大量的计算任务,可以交给 gpu 来跑。
浏览器在处理下面的 css 的时候,会使用 gpu 渲染:
- transform
- opacity
- filter
- will-change
浏览器是把内容分到不同的图层分别渲染的,最后合并到一起,而触发 gpu 渲染会新建一个图层,把该元素样式的计算交给 gpu。
opacity 需要改变每个像素的值,符合重复且大量的特点,会新建图层,交给 gpu 渲染。transform 是动画,每个样式值的计算也符合重复且大量的特点,也默认会使用 gpu 加速。同理 fiter 也是一样。
这里要注意的是 gpu 硬件加速是需要新建图层的,而把该元素移动到新图层是个耗时操作,界面可能会闪一下,所以最好提前做。will-change 就是提前告诉浏览器在一开始就把元素放到新的图层,方便后面用 gpu 渲染的时候,不需要做图层的新建。
当然,有的时候我们想强制触发硬件渲染,就可以通过上面的属性,比如
- will-change: transform;
或者
- transform:translate3d(0, 0, 0);
chrome devtools 可以看到是 cpu 渲染还是 gpu 渲染,打开 rendering 面板,勾选 layer borders,会发现蓝色和黄色的框。蓝色的是 cpu 渲染的,而黄色的是 gpu 渲染的。
比如这段文字,现在没有单独一个图层:
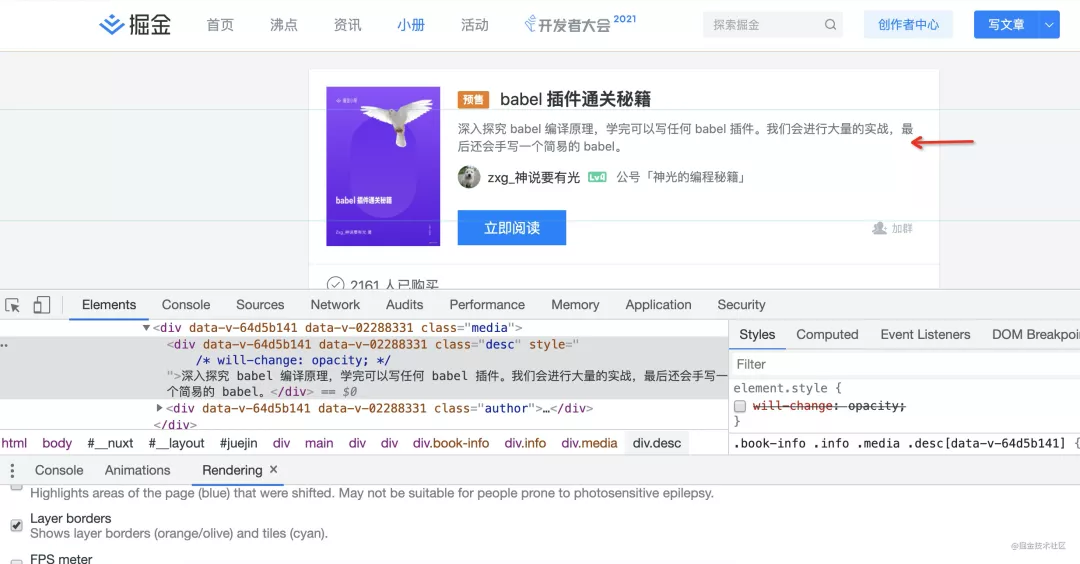
添加一个 will-change: transform 的属性,浏览器会新建图层来渲染该元素,然后使用 gpu 渲染:
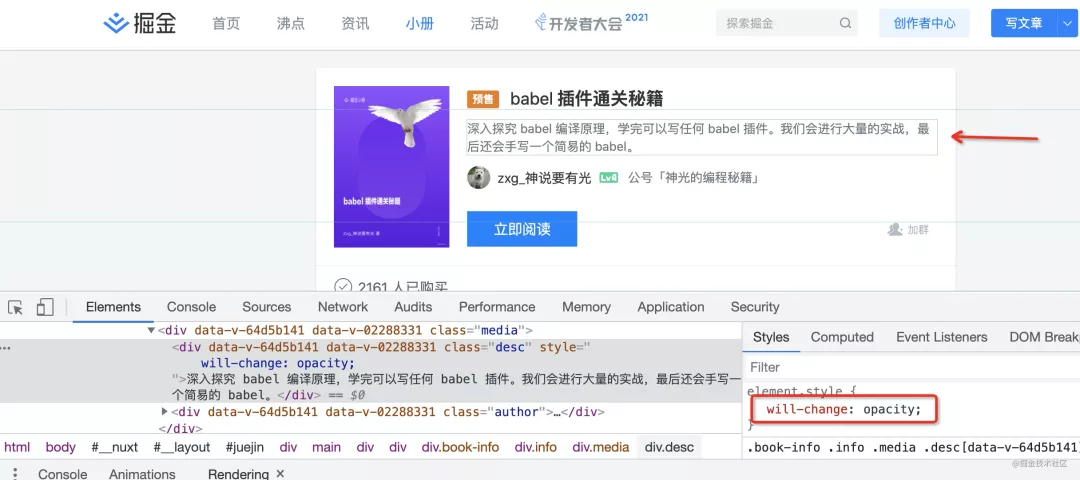
gpu 硬件加速能减轻 cpu 压力,使得渲染更流畅,但是也会增加内存的占用,对于 transform、opacity、filter 默认会开启硬件加速。其余情况,建议只在必要的时候用。
opencl 和神经网络
重复且大量的计算任务只有 3d 渲染一种场景么?
不是的,AI 领域的机器学习也很典型,它的特点是大量的神经元需要计算,但是每个计算都比较简单,也很适合用 gpu 来跑。
现在的 gpu 不只是能跑图形渲染,也提供了一些编程能力,这部分 api 有 opencl 标准。可以通过 gpu 的并行计算能力来跑一些有大量计算但是没有很多逻辑的的任务,会比 cpu 效率更高。
总结
cpu 提供了指令集,会不断的执行取指令、译码、执行、取数、写回的指令周期,控制着计算机的运转。
cpu 计算的速度比较快,而访问内存比较慢,为了缓和两者的矛盾,引入了 L1、L2、L3 的多级缓存体系,L1、L2、L3 是容器逐渐变大,访问速度逐渐变慢的关系,但还是比访问内存快。内存会通过一个缓存行(64 字节)的大小为单位来读入缓存,供 cpu 访问。
3d 渲染的流程是计算每一个顶点的数据,连成一个个三角形,然后进行纹理贴图,之后计算投影到二维屏幕的每一个像素的颜色,也就是光栅化,最后写入显存帧缓冲区,这样进行一帧帧的渲染。
cpu 的计算是一个个串行执行的,对于 3d 渲染这种涉及大量顶点、像素要计算的场景就不太合适,于是出现了 gpu。
gpu 可以并行执行大量重复的计算,有成百上千个计算单元,相比 cpu 虽然执行不了复杂逻辑,但是却能执行大量重复的运算。提供了 opengl 的标准 api。
css 中可以使用 gpu 加速渲染来减轻 cpu 压力,使得页面体验更流畅,默认 transform、opacity、filter 都会新建新的图层,交给 gpu 渲染。对于这样的元素可以使用 will-change: 属性名; 来告诉浏览器在最开始就把该元素放到新图层渲染。
gpu 的并行计算能力不只是 3d 渲染可以用,机器学习也有类似的场景,可以通过 opencl 的 api 来控制 gpu 进行计算。
gpu 和前端的关系还是挺密切的,不管是 webgl,还是 css 硬件加速,或者网页的性能都与之相关。希望这篇文章能够帮大家了解 gpu 的原理和应用。