












第一章 Oracle索引位图转换介绍
1.1 索引位图转换
首先介绍一下索引位图转换概念:
索引位图转换是优化器对目标表上的一个或多个目标索引执行位图布尔运算。Oracle数据库里有一个映射函数(Mapping Function),它可以实现B树索引中ROWID和对应位图索引中的位图之间互相转换。目的是对相同ROWID做AND、OR等连接运算。
当执行计划中出现“BITMAP CONVERSION FROM/TO ROWIDS”、“BITMAP AND”,说明Oracle对应的索引将其中的ROWID转换成了位图,然后对转换后的位图执行了BITMAP AND(位图按位与)布尔运算。最后将布尔运算的结果再次用映射函数转换成了ROWID并回表得到最终的结果。
1.2 性能分析
根据我们以往的经验,用映射函数将ROWID转换成位图,这期间可能访问了多个索引,甚至一个索引会访问N多次。然后在执行位图布尔运算。最后再将运算结果转换为ROWID并回表,这个过程在实际生产环境中的执行效率往往是有问题的,我们可以通过隐藏参数_b_tree_bitmap_plans禁掉该过程中从ROWID到位图的转换。
但实际上当我们看到“BITMAP CONVERSION FROM/TO ROWIDS”的执行计划,一定代表着存在性能问题吗?
下面我用一个案例来说明:
创建测试表结构如下:
- DROP TABLE T1 PURGE;
- CREATE TABLE T1 AS SELECT * FROM DBA_OBJECTS;
- CREATE INDEX IDX_T1_ID ON T1(OBJECT_ID);
- EXEC dbms_stats.gather_table_stats(ownname=>'SZT',tabname =>'T1');
第二章 实验环境测试
实验脚本如下:
- select * from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
目的是通过单个索引,将优化器走索引位图转换与否的执行效率比较。
2.1 比较执行效率
首先测试默认情况下的执行计划:
- select * from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
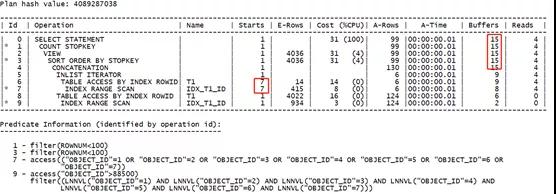
可以看到,优化器没有对索引做位图转换,而是使用了OR扩展的方式。分别访问两部分的查询条件,并对其中的IN条件使用IN-LIST迭代的方式获取数据。
分析这样的优势:
IN条件中多个值会分别被访问并与索引中的数据作比较,条件中的多个值也不会访问索引多次,执行效率较高。通过逻辑读部分也能确定。
通过HINT,尝试让优化器走出索引位图转换方式:
- select /*+ OUTLINE_LEAF(@"SEL$2") OUTLINE_LEAF(@"SEL$1")
- BITMAP_TREE(@"SEL$2" "T1"@"SEL$2" OR(1 1 ("T1"."OBJECT_ID") 2 ("T1"."OBJECT_ID") 3 ("T1"."OBJECT_ID") 4
- ("T1"."OBJECT_ID") 5 ("T1"."OBJECT_ID") 6 ("T1"."OBJECT_ID") 7 ("T1"."OBJECT_ID") 8 ("T1"."OBJECT_ID"))) */* from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
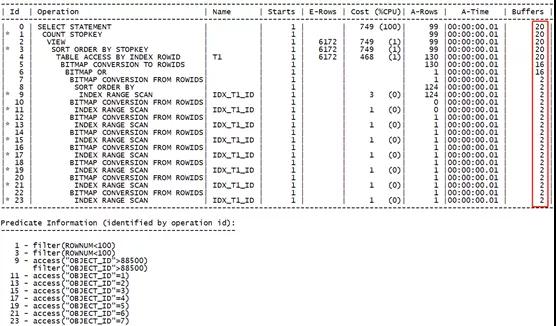
可以看到,每一次位图访问都只得到一个对应的IN条件值,且相同索引访问多次每次都消耗固定的逻辑读,据此分析当前场景下位图索引转换执行效率不佳。原因来自于索引的多次访问。
我们查看相应表上的索引信息:

可以看到索引建立的原则就是唯一值与表数据1:1的情况。同时,由于采用了OBJECT_ID,其自增长特性,索引的聚簇因子比较小,属于相对高效的索引。
得出结论:在聚簇因子较小时,通过OR扩展、IN-LIST迭代的方式其执行效率高于索引位图转换。且优化器也能准确评估COST成本。
但实际生产环境中,大部分索引的聚簇因子没有这么高效。下面我们降低聚簇因子值及进行测试。
2.2 降低索引的聚簇因子:
让我们重新创建新表。实验脚本如下:
- CREATE TABLE T2 AS SELECT * FROM DBA_OBJECTS WHERE 1=2;
- insert into t2 select * from dba_objects order by dbms_random.value; --随机插入
- CREATE INDEX IDX_T2_ID ON T1(OBJECT_ID);
- EXEC dbms_stats.gather_table_stats(ownname=>'SZT',tabname =>'T2');
通过打乱表数据的顺序,降低聚簇因子值。

可以看到聚簇因子几乎接近于表中数据行数,且索引叶子块也有所增加。
2.2.1 比较执行效率
- select * from (
- select * from t2 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
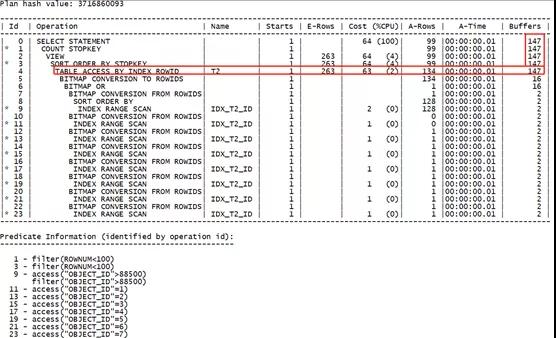
可以看到,默认情况下执行计划变为了索引位图转换的形式。
分析其优势:只进行了一次回表。
通过HINT让优化器走回原有执行计划:
- select * from (
- select /*+ USE_CONCAT(@"SEL$2" 8 OR_PREDICATES(1)) */ * from t2 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
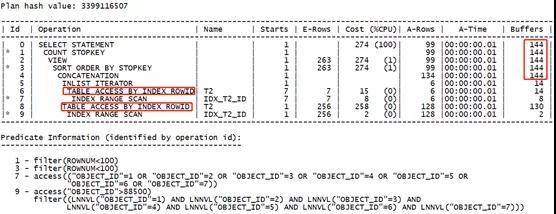
可以看到,由于回表了两次,且聚簇因子较大,其消耗的逻辑读已经逐渐接近于索引位图转换的方式了。
且分析其回表逻辑读:
- 位图形式:134行回表,消耗147-16=131。
- OR扩展:128行回表,消耗130-2=128。
回表的逻辑读十分接近。
总结:
索引位图转换的优势是减少回表次数。
OR扩展的优势是其IN-LIST迭代部分消耗逻辑读较低。
分析到此,我们已经基本明确不同方式的优劣了,但对实际的逻辑读消耗对比还不够确定。
下面让我们增大查询的条件范围。
2.2.2 增大查询条件范围
- select * from (
- select * from t2 WHERE object_id>88450 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
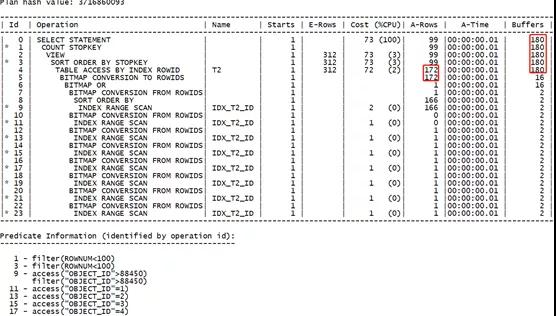
测试OR扩展:
- select /*+ USE_CONCAT(@"SEL$2" 8 OR_PREDICATES(1)) */* from (
- select * from t2 WHERE object_id>88450 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
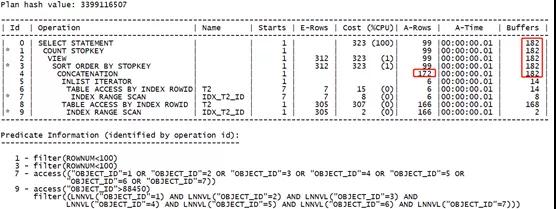
可以看到,当增大查询范围值后,两种不同执行计划其实际的消耗越来越接近了,最后通过索引位图转换的方式其执行效率甚至高于原有的OR扩展的形式。因此我们在判断执行效率时,还是要具体情况具体分析。
分析回表的逻辑读开销:
- 位图形式:172行回表,消耗180-16=164
- OR扩展:166行回表,消耗168-2=166
据此我们又可以确定,传统的回表方式其实际的资源开销高于索引位图转换后的回表方式。这又是索引位图转换的一大好处。
得出结论:
聚簇因子越大的索引,其越能在索引位图转换的方式中受益。因为其只需要回表一次。
索引位图转换后的回表,其消耗的资源开销会低于传统的回表方式。这也是索引位图转换的优势之一。
第三章 总结
以上,我们通过3个测试例子,验证的不同场景下的执行计划表现。
关于开头部分我们的疑问,可以很明确做答了。
1.索引位图转换和传统的OR扩展、IN-LIST迭代等形式、其执行效率要具体情况具体分析。主要受影响于相关索引上的聚簇因子值。
2.索引位图转换的优势是一次性统一回表,ROWID回表的开销也会略低于传统的形式。
3. IN-LIST迭代的优势是对于IN后面条件多个值的访问,其实际资源开销较低。
墨天轮原文链接:https://www.modb.pro/db/25952(复制链接至浏览器或点击文末阅读原文查看)
关于作者
张程,云和恩墨SQL优化工程师,长期服务于金融、保险行业。现负责:公司Oracle、SQLServer、MySQL数据库优化方面的技术工作;公司SQL审核软件SQM的审核相关工作。热衷于性能优化的学习与分享。











