













1.序篇-先说结论
本文主要记录博主在生产环境中踩的 flink 针对 java enum serde 时的坑。
结论:在 flink 程序中,如果状态中有存储 java enum,那么添加或者删除 enum 中的一个枚举值时,就有可能导致状态恢复异常,这里的异常可能不是在恢复过程中会实际抛出一个异常,而是有可能是 enum A 的值恢复给 enum B。
我从以下几个章节说明、解决这个问题,希望能抛砖引玉,带给大家一些启发。
- 踩坑场景篇-这个坑是啥样的
- 问题排查篇-坑的排查过程
- 问题原理解析篇-导致问题的机制是什么
- 避坑篇-如何避免这种问题
- 总结篇
2.踩坑场景篇-这个坑是啥样的
对任务做一个简单的过滤条件修改,任务重新上线之后,从 flink web ui 确认是从 savepoint 重启成功了,但是实际最终产出的数据上来看却像是没有从 savepoint 重启。
逻辑就是计算分维度的当天累计 pv。代码很简单,在后面会贴出来。
如下图:

在 00:04 分重启时出现了当天累计 pv 出现了从零累计的情况。
但是预期正常的曲线应该张下面这样。

任务是使用 DataStream 编写(基于 flink 1.13.1)。
- public class SenerioTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- env.setParallelism(1);
- env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- env.addSource(new SourceFunction<SourceModel>() {
- private volatile boolean isCancel = false;
- @Override
- public void run(SourceContext<SourceModel> ctx) throws Exception {
- // 数据源
- }
- @Override
- public void cancel() {
- this.isCancel = true;
- }
- })
- .keyBy(new KeySelector<SourceModel, Long>() {
- @Override
- public Long getKey(SourceModel value) throws Exception {
- return value.getUserId() % 1000;
- }
- })
- .timeWindow(Time.minutes(1))
- .aggregate(
- new AggregateFunction<SourceModel, Map<Tuple2<DimNameEnum, String>, Long>, Map<Tuple2<DimNameEnum, String>, Long>>() {
- @Override
- public Map<Tuple2<DimNameEnum, String>, Long> createAccumulator() {
- return new HashMap<>();
- }
- @Override
- public Map<Tuple2<DimNameEnum, String>, Long> add(SourceModel value,
- Map<Tuple2<DimNameEnum, String>, Long> accumulator) {
- Lists.newArrayList(Tuple2.of(DimNameEnum.province, value.getProvince())
- , Tuple2.of(DimNameEnum.age, value.getAge())
- , Tuple2.of(DimNameEnum.sex, value.getSex()))
- .forEach(t -> {
- Long l = accumulator.get(t);
- if (null == l) {
- accumulator.put(t, 1L);
- } else {
- accumulator.put(t, l + 1);
- }
- });
- return accumulator;
- }
- @Override
- public Map<Tuple2<DimNameEnum, String>, Long> getResult(
- Map<Tuple2<DimNameEnum, String>, Long> accumulator) {
- return accumulator;
- }
- @Override
- public Map<Tuple2<DimNameEnum, String>, Long> merge(
- Map<Tuple2<DimNameEnum, String>, Long> a,
- Map<Tuple2<DimNameEnum, String>, Long> b) {
- return null;
- }
- },
- new ProcessWindowFunction<Map<Tuple2<DimNameEnum, String>, Long>, SinkModel, Long, TimeWindow>() {
- private transient ValueState<Map<Tuple2<DimNameEnum, String>, Long>> todayPv;
- @Override
- public void open(Configuration parameters) throws Exception {
- super.open(parameters);
- this.todayPv = getRuntimeContext().getState(new ValueStateDescriptor<Map<Tuple2<DimNameEnum, String>, Long>>(
- "todayPv", TypeInformation.of(
- new TypeHint<Map<Tuple2<DimNameEnum, String>, Long>>() {
- })));
- }
- @Override
- public void process(Long aLong, Context context,
- Iterable<Map<Tuple2<DimNameEnum, String>, Long>> elements, Collector<SinkModel> out)
- throws Exception {
- // 将 elements 数据 merge 到 todayPv 中
- // 每天零点将 state 清空重新累计
- // 然后 out#collect 出去即可
- }
- });
- env.execute();
- }
- @Data
- @Builder
- private static class SourceModel {
- private long userId;
- private String province;
- private String age;
- private String sex;
- private long timestamp;
- }
- @Data
- @Builder
- private static class SinkModel {
- private String dimName;
- private String dimValue;
- private long timestamp;
- }
- enum DimNameEnum {
- province,
- age,
- sex,
- ;
- }
- }
3.问题排查篇-坑的排查过程
3.1.愚蠢的怀疑引擎
首先怀疑是状态没有正常恢复。
但是查看 flink web ui 以及 tm 日志,都显示是从 savepoint 正常恢复了。
还怀疑是不是出现了 flink web ui 展示的内容和实际的执行不一致的情况。
但是发现任务的 ck 大小是正常的,复合预期的。
3.2.老老实实打 log 吧
既然能从 savepoint 正常恢复,那么就把状态值用 log 打出来看看到底发生了什么事情呗。
如下列代码,在 ProcessWindowFunction 中加上 log 日志。
- this.todayPv.value()
- .forEach(new BiConsumer<Tuple2<DimNameEnum, String>, Long>() {
- @Override
- public void accept(Tuple2<DimNameEnum, String> k,
- Long v) {
- log.info("key 值:{},value 值:{}", k.toString(), v);
- }
- });
发现结果如下:
- ...
- key 值:(uv_type,男),value 值:1000
- ...
发现状态中存储的 DimNameEnum.province,DimNameEnum.age 的数据都是正确的,但是缺缺少了 DimNameEnum.sex,多了 (uv_type,男) 这样的数据,于是查看代码,发现之前多加了一种枚举类型 DimNameEnum.uv_type。代码如下:
- enum DimNameEnum {
- province,
- age,
- uv_type,
- sex,
- ;
- }
于是怀疑 flink 针对枚举值的 serde 不是按照枚举值名称来进行匹配的,而是按照枚举值下标来进行匹配的。因此就出现了 DimNameEnum.uv_type 将 DimNameEnum.sex 的位置占了的情况。
4.问题原理解析篇-导致问题的机制是什么
来看看源码吧。
测试代码如下:
- public class EnumsStateTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- env.setParallelism(1);
- env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- TypeInformation<StateTestEnums> t = TypeInformation.of(StateTestEnums.class);
- EnumSerializer<StateTestEnums> e = (EnumSerializer<StateTestEnums>) t.createSerializer(env.getConfig());
- DataOutputSerializer d = new DataOutputSerializer(10000);
- e.serialize(StateTestEnums.A, d);
- env.execute();
- }
- enum StateTestEnums {
- A,
- B,
- C
- ;
- }
- }
debug 结果如下:
首先看看对应的 TypeInformation 和 TypeSerializer。
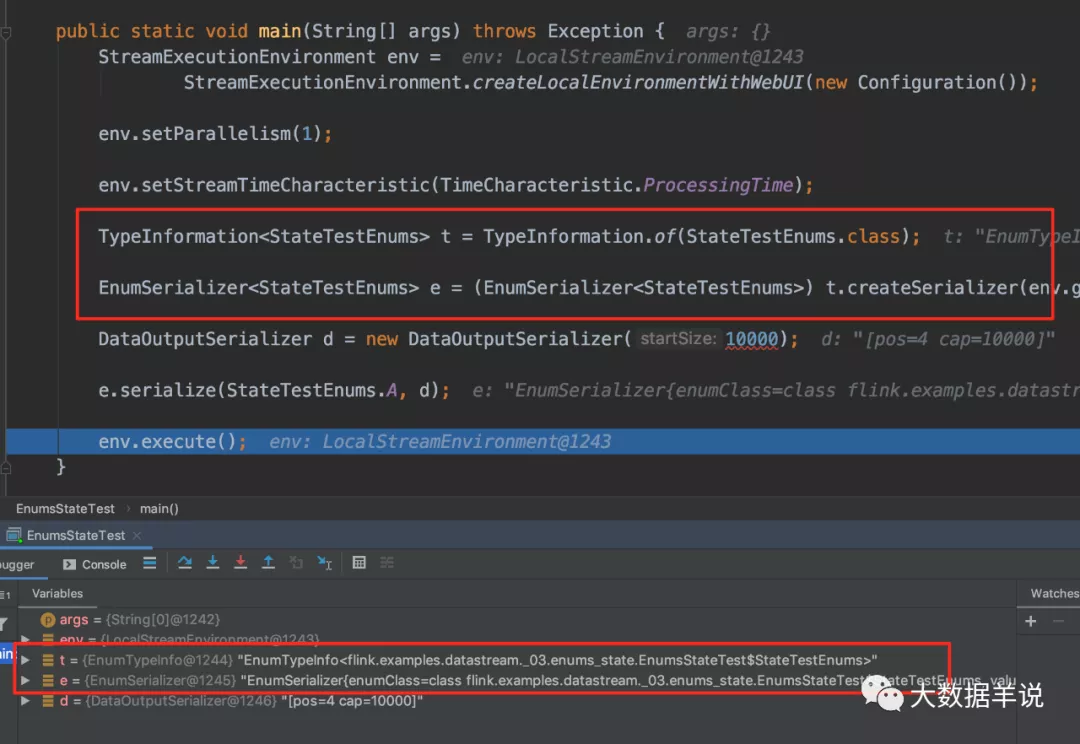
发现 enum 类型的序列化器是 EnumSerializer, 看看 EnumSerializer 的 serde 实现,如图所示:

最关键的两个变量:
- 序列化时用 valueToOrdinal
- 反序列化时用 values
从而印证了上面的说法。flink enum 序列化时使用的是枚举值下标进行 serde,因此一旦枚举值顺序发生改变,或者添加、删除一个枚举值,就会导致其他枚举值的下标出现错位的情况。从而导致数据错误。
5.避坑篇-如何避免这种问题
5.1.枚举解决
在上述场景中,如果又想要把新枚举值加进去,又需要状态能够正常恢复,正常产出数据。
那么可以把新的枚举值在尾部添加,比如下面这样。
- enum DimNameEnum {
- province,
- age,
- sex,
- uv_type, // 添加在尾部
- ;
- }
5.2.非枚举解决
还有一种方法如标题,就是别用枚举值,直接用 string 就 vans 了。
6.总结篇
本文主要介绍了 flink 枚举值 serde 中的坑,当在 enum 中添加删除枚举值时,就有可能导致状态岔劈。随后给出了原因是由于 enum serde 器的实现导致的这种情况,最后给出了解决方案。
本文转载自微信公众号「大数据羊说」,可以通过以下二维码关注。转载本文请联系大数据羊说公众号。













