












2021年7月24日,由江苏省未来网络创新研究院主办、SDNLAB承办的2021中国5G网络创新论坛上,多家机构谈到了DPU的进展,我们对此进行了整理,以飨读者。
5G时代带来通信带宽的巨大提升,更多的带宽使能更多的应用。数据量的迅猛增多以及服务器网络带宽的快速增长都已经远超计算能力的增长,有线速I/O处理需求的应用程序受到CPU和内存的限制,现有系统也会因为CPU资源占用而导致延迟增加,包处理性能出现波动。
5G时代带来互联终端设备的大爆发,也带来数据大爆发。据统计2019年全球产生数据45ZB,预计到2024年这一数字将达到142ZB,其中24%的数据将来自终端实时数据。海量数据条件下低时延网络传输及数据处理的算力需求及性能压力巨大。
5G时代带来个性化定制私域网络时代。5G网络不止用于公众客户,更主要的赋能各行各业,作为新基建的重要组成,推动社会发展。5G将大量部署在网络边缘,提供实时应用和服务。据IDC统计,近10年来全球算力增长明显滞后于数据的增长。每3.5个月全球算力的需求就会翻一倍,远超算力增长的速度。算力,作为先进生产力,承载了十万亿美元规模经济。在5G的推动下,计算组织从“端-云”一体,到“端-边缘-云”一体;从内存计算发展到网内计算。基础设施云资源作为5G发展的重要基石,也发生了极大的变化。
5G的需求
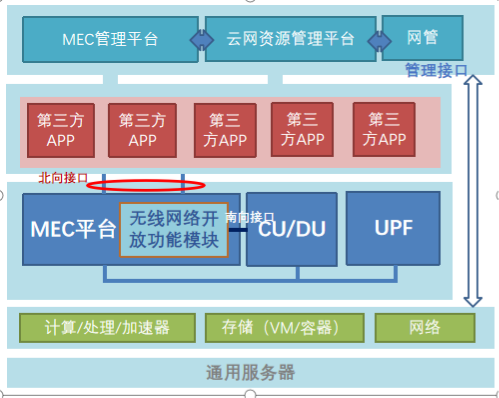
5G MEC是一种分布式计算部署架构,将计算能力、业务以及部分5G网络能力部署到网络边缘,实现低时延的就地数据处理、敏感数据本地处理。MEC可以很好的适配低频、频次不确定性同时时间敏感的业务场景。(来源:网络通信与安全紫金山实验室)
5G MEC包括5G网关UPF、边缘应用平台MEP、行业应用APP以及虚拟化基础设施。5G MEC作为一体式设备部署在靠近终端用户侧的边缘位置,提供大带宽、低时延的网络连接能力,AI、图像渲染等计算能力,以及面向行业的安全能力。
边缘计算将从传统的集中式互联网交换(Internet Exchange IX)模型扩展到边缘交换模型。位于边缘的最终用户和设备远离主要IX点,流量到达这些位置所需的距离会降低性能并显著增加传输成本。网络互联需要在靠近最终用户的最后一公里网络附近的边缘进行。数据在边缘互联和共享,不涉及核心网。边缘互联将更多流量保留在本地。
低延迟网络是边缘计算的重要组成,要求网络节点尽可能靠近本地。随着越来越多的数据在本地产生本保存,网络互联密度将在边缘激增,骨干网将延伸到边缘,对等互联和数据交换将发生在接入网的1-2跳内。随着边缘计算基础设施的建设,许多设施将发挥网络间数据交换点的作用。网络汇聚于这些节点,为边缘服务提供支持,降低边缘服务延迟,缩短光纤距离,减少网络跳数。随着计算向边缘扩展,网络交叉连接也将更加分散。预计到2025年,75%的数据将在工厂、医院、零售、城市的边缘产生、处理、存储和分析。
5G具有灵活的前导码,以满足低延迟连接的需求。随着边缘计算需求的增长,现有的回传网络处理速度无法匹配5G网络数据产生的速度和容量需求,需要在边缘部署新的、更快和更高容量的路由。
5G虚拟化网络功能需要高度分布式的数据中心。这类数据中心可以部署足够多的服务器,在运行5G网络的同时运行边缘云服务。
将工作负载置于边缘要求对应用构建和运行的方式进行调整,让代码可以从数据中心的服务器到客户场所设备中的微控制器。需要管理高度分布式的应用和数据,编排大规模的边缘操作。(云原生技术和DevSecOps技术)推送到边缘的代码应该是自包含的,每个组件必须完整,包含代码、配置、库以及软件定义的环境,代码作为一个整体构建、测试和部署,确保容器或虚拟机可以在任何地方运行。
DPU的出现
在云基础设施领域,CPU用于通用计算,构建应用生态,虚拟化技术例如Hypevisor等占用大量的内存和CPU资源,而真正用作共享的资源受到较大的影响。以网络协议处理为例,解析报文需要接近100个cycle,线速处理10G的网络需要约4个Xeon CPU的核,单做网络数据包处理,就可以占去一个8核高端CPU一半的算力。而GPU用于加速计算,专注于图像处理、流媒体处理,并继续朝着AR、VR处理,AI加速的方向发展。在云基础设施领域,需要一种技术,能够卸载CPU负荷,最大限度的将硬件资源共享给租户。
十年前,网络处理器(NP)主要用于包处理、协议处理加速,应用在各种网关、防火墙、UTM等设备上,多采用多核NOC架构。后来Intel推出了DPDK技术,在用户空间上利用自身提供的数据平面库手法数据包,绕过linux内核协议栈,极大提升了包转发速率,原来需要NP来实现的网关类设备,现在X86就能满足性能要求。而DPU则是5G时代集网络加速为一体的新型数据处理单元。DPU内部融合了RDMA、网络功能、存储功能、安全功能、虚拟化功能。接手CPU不擅长的网络协议处理、数据加解密、数据压缩等数据处理任务,同时兼顾传输和计算的需求。DPU起到连接枢纽的作用,一端连接CPU、GPU、SSD、FPGA加速卡等本地资源,一端连接交换机/路由器等网络资源。总体而言,DPU不仅提高了网络传输效率,而且释放了CPU算力资源,从而带动整体数据中心的降本增效。
1950年以来,CPU是计算机或智能设备的核心
1990年以来,GPU登上舞台
而5G的时代是数据革命时代,也是DPU的时代。
什么是DPU
DPU是相当于智能网卡的升级版本,增强了网络安全和网络协议的处理能力,增强了分布式存储的处理能力,将软件定义网络、软件定义存储、软件定义加速器融合到一个有机的整体中,解决协议处理,数据安全,算法加速等计算负载,替代数据中心用于处理分布式存储和网络通信的CPU资源。
DPU本质上是分类计算,是将数据处理/预处理从CPU卸载,同时将算力分布在更靠近数据发生的地方,从而降低通信量,涵盖基于GPU的异构计算,基于网络的计算(In-NetworkComputing)、基于内存(In-Memory-Computing)的计算等多个方面。DPU定位于协同处理单元,是数据面与控制面分离思想的一种实现,其与CPU协作配合,后者负责通用控制,前者专注于数据处理。在局域网场景下DPU通过PCIe/CXL等技术连接同一边缘内各种CPU、GPU,广域网场景下主要通过Ethernet/infiniband等技术实现边缘与边缘间、边缘与云之间的连接。
DPU包括特定的报文处理引擎,如P4、POF等,此外还包含ARM等协处理器能够处理路由器场景中的大量分支预测。具备低延迟的交换能力,能将不同类型的数据包快速分发给不同的处理单元。
基于DPU的网络处理模块是完全可编程的。相比于ASIC,DPU能随着网络、协议、封装和加密算法的快速变化,以软件的速度改变硬件的能力。通过DPU提高每个网络节点上的计算能力,相比标准网卡,同等算力所需的服务器数量更少,降低了前期成本、空间、电力和散热的要求,DPU会降低大规模部署网络服务的TCO。
DPU将成为新的数据网关,集成安全功能,使网络接口成为隐私的边界。可将开销巨大的加解密算法如国密标准的非对称加密算法SM2、哈希算法SM3和对称分组密码算法SM4,交由DPU处理。未来,随着区块链技术的成熟,共识算法POW、验签等都会消耗大量的CPU算力也可以固化在DPU中。
DPU将成为存储的入口。分布式系统中NVMeof协议扩展到InfiniBand或TCP互联的节点中,实现存储的共享和远程访问。这些数据流的协议处理可以集成在DPU中,作为各种互联协议控制器。
DPU将成为云服务提供商管理资源的工具,云服务提供商将云资源管理占用全部下沉至DPU,将CPU、GPU全部释放出来,作为基础设施提供给云租户。提供者与使用者两者之间的资源严格区分,管理界面清晰,方便使用。
DPU实现的方式:
不同厂商DPU实现方式不一:
- Marvell收购了Innovium,提供面向5G的基带处理 DPU,其OCTEON 10系列DPU,采用台积电5nm制程,首次采用ARM Neoverse N2 CPU内核;
- Netronome,其NFP4000流处理器,包括48个数据包处理内核和60个流处理内核,所有这些内核都可以通过P4编程;
- Pensando其Capri处理器具有多个可编程的P4处理单元。
- Fungible,其DPU基于MIPS,面向网络、存储、虚拟化,包含52个MIPS小型通用核以及6个大类的专用核。
英伟达 2019年3月,收购以色列芯片公司Mellanox,其推出的BlueField-2包括8个ARM Cortex-A72核及多个专用加速核区域。DOCA(data center infrastructure-on-a-chip Architecture)作为 DPU上的软件开发平台,提供标准API,将驱动程序、库、示例代码、文档和与包装的容器组合在一起,支持基于DPU应用和服务的快速开发。
英特尔,收购了深度学习芯片公司Nervana System,以及移动和嵌入式机器学习公司Movidius,将CPU与FPGA结合在一起构建DPU。提供DPDK(Intel Data Plane Development Kit),为用户空间高效的数据包处理提供库函数核驱动的支持,通过SR-IOV技术,实现不同应用通过DMA直接与PCIe设备一起工作。FPGA扩展到300万个逻辑单元,可以与其他处理模块一起实现网络、内存、存储和计算。
Broadcom基于Arm实现DPU,主要面向交换机、路由器芯片。以NetXtreme E系列控制器为基础,搭载TruFlow技术,推出了Stingray SmartNIC。
Xilinx 2019年收购了solarFlare,其最新发布的Alveo SN1000系列基于 16nm UltraScale+FPGA架构,容量为100万个LUT,包含一个NXP的16核ARM处理器,可以在FPGA上每秒处理400万个状态连接和1亿个数据包。其solarFlare onload(TCPDirect)功能应用于全球90%的金融交易所。
AWS Nitro,采用了网络卡、存储卡、控制器卡多卡形态来实现DPU功能。收购了以色列芯片上Annapurna labs。
阿里云,推出了MOC卡产品,集成了志强D处理器、FPGA,是一种单卡形态产品。
英伟达的DPU(BlueField-2)功能特色
从2021中国5G网络创新论坛上英伟达沈宇希嘉宾的演讲中获知,英伟达的BlueField-2采用SoC架构设计,最大200Gbps带宽,编码方式支持NRZ 25Gbps模式和PAM4 50Gbps模式,内置ConnectX-6 Dx网卡芯片,支持RDMA,同时支持TLS/IPSec。

DPU可以提供实时时钟。搭载ConnectX-6DX的DPU,通过PHC2SYS能够实现服务器与网卡之间400ns的同步精度,ConnetX-6DX之间借助PTP4l可以实现20ns的同步精度,满足5G无线DU时钟同步需求。
DPU增强边缘网络部署智能。DPU支持裸金属、虚拟化、容器化部署模式。裸金属控制层通过DPU仿真NVMe设备,数据层借助DPU的ASIC芯片高速转发,并通过NVMatrix基于Infiniband或RoCEv2无损网络连接后端高通量分部式集群。DPU可为裸金属物理机接入灵活可扩展的高速云盘服务。
DPU可以提供灵活可扩展的网络设备。DPU可以配置为两类设备:一类为NVIDIA原生设备,包括PF/VF、SF;另一类为VirtIO-Net设备。其中,SF专门针对基于裸金属的大规模容器开发,功能与VF设备相当,支持RDMA、内核协议栈,开启无需打开SR-IOV。该DPU最大支持512个SF(SubFunction)。
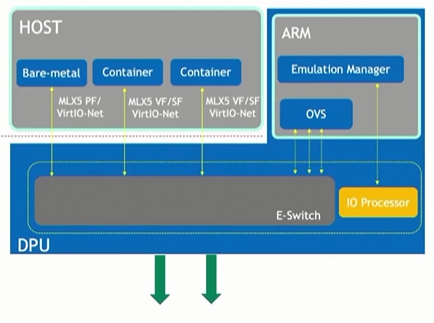
图3:DPU示意图
DPU对网络加速。DPU采用了ASAP2网络加速技术。ConnetX-6DX内置了Embeded switch(E-Switch),能够实现网络设备之前的数据交换和处理。E-Switch可编程,支持查表操作及表跳转,表项与OVS数据面匹配。OVS数据面可卸载至E-Switch,通过ASIC实现了内核OVS的卸载,转发性能高。通过ASAP2 将OVS数据面、控制面、管理面分开,后两者通过DPU的ARM计算组件来实现,数据面卸载到E-Switch,从而实现加速的效果。E-Switch支持多种Overlay协议的卸载,如VXLAN、GRE等,支持报文头修改,实现NAT功能。E-Switch支持Connection Track,实现TCP连接的状态监控,此外还支持流量统计和限速、镜像;E-Switch与现有SDN控制器及编排工具无缝兼容。基于该DPU,裸金属云可以快速部署,实现网络性能的提升。
DPU提供高可靠的存储。相比于智能网卡,DPU增加了存储卸载功能,通过SNAP技术向主机OS呈现多个存储设备。应用对DPU的访问由IO Processor统一处理,包括SPDK和硬件卸载两种处理方式。用户可以在DPU连接的存储设备上安装操作系统,并启动,从而构建本地完全没有磁盘的裸金属架构,实现比本地磁盘更高的可靠性。租户对存储的定义和访问都通过DPU完成,对主机操作系统无依赖,同时可以充分利用远端存储支持数据快速迁移(分钟级)。
小结
当前,虽然有众多巨头的参与,DPU市场仍然处于初级阶段。随着网络流量指数上涨,在任何有大流量的地方,DPU都将存在,市场前景广阔。在DPU加持下,5G时代边云协同、云网一体都将逐渐成为现实。




















