字符怎么存储呢?就是靠编码,不同的字符对应不同的编码,然后在需要渲染的时候根据对应编码去查字体库,然后渲染对应字符的图形。
字符集
字符集(charset)最早是 ASCII 码,也就是 abc ABC 123 等 128 个字符,因为计算机最早就是美国发明的。后来欧洲也制定了一套字符集标准,叫做 ISO,后来中国也搞了一套,叫做 GBK。
国际标准化组织觉得不能这样各自搞一套,不然同一个编码在不同字符集里面就不同的意思,于是就提出了 unicode 编码,把全世界大部分编码收录,这样每个字符只有唯一的编码。
但是 ASCII 码只需要 1 个字节就可以存储,而 GBK 需要 2 个字节,还有的字符集需要 3 个字节等。有的只要一个字节存储却存了 2 个字节,比较浪费空间。所以就出现了 utf-8、utf-16、utf-24 等不同编码方案。
utf-8、utf-16、utf-24 都是 unicode 编码,但是具体实现方案不同。
UTF-8 为了节省空间,设计了从 1 到 6 个字节的变长存储方案。而 UTF-16 是固定 2 个字节,UTF-24 是固定 4 个字节。
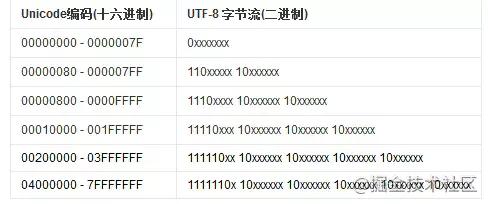
最后,UTF-8 因为占用空间最少,所以被广泛应用。
Node.js 的 Buffer 的 encoding
每种语言都支持字符集的编码解码,Node.js 也同样。
Node.js 里面可以通过 Buffer 来存储二进制的数据,而二进制的数据转为字符串的时候就需要指定字符集,Buffer 的 from、byteLength、lastIndexOf 等方法都支持指定 encoding:
具体支持的 encoding 有这些:
utf8、ucs2、utf16le、latin1、ascii、base64、hex
可能有的同学会发现:base64、hex 不是字符集啊,怎么也出现在这里?
是的,字节到字符的编码方案除了字符集之外,也有用于转为明文字符的 base64、以及转为 16 进制的 hex。
这也是为什么 Node.js 把它叫做 encoding 而不是 charset,因为支持的编解码方案不只是字符集。
如果不指定 encoding,默认是 utf8。
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf.toString());// hello world
- 1.
- 2.
- 3.
encoding 的 源码
我去翻了下 Node.js 关于 encoding 的源码:
这一段是实现 encoding 的:
https://github.com/nodejs/node/blob/master/lib/buffer.js#L587-L726
可以看到每个 encoding 都实现了 encoding、encodingVal、byteLength、write、slice、indexOf 这几个 api,因为这些 api 用不同 encoding 方案,会有不同的结果,Node.js 会根据传入的 encoding 来返回不同的对象,这是一种多态的思想。
const encodingOps = {
utf8: {
encoding: 'utf8',
encodingVal: encodingsMap.utf8,
byteLength: byteLengthUtf8,
write: (buf, string, offset, len) => buf.utf8Write(string, offset, len),
slice: (buf, start, end) => buf.utf8Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf8, dir)
},
ucs2: {
encoding: 'ucs2',
encodingVal: encodingsMap.utf16le,
byteLength: (string) => string.length * 2,
write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
slice: (buf, start, end) => buf.ucs2Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
},
utf16le: {
encoding: 'utf16le',
encodingVal: encodingsMap.utf16le,
byteLength: (string) => string.length * 2,
write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
slice: (buf, start, end) => buf.ucs2Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
},
latin1: {
encoding: 'latin1',
encodingVal: encodingsMap.latin1,
byteLength: (string) => string.length,
write: (buf, string, offset, len) => buf.latin1Write(string, offset, len),
slice: (buf, start, end) => buf.latin1Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.latin1, dir)
},
ascii: {
encoding: 'ascii',
encodingVal: encodingsMap.ascii,
byteLength: (string) => string.length,
write: (buf, string, offset, len) => buf.asciiWrite(string, offset, len),
slice: (buf, start, end) => buf.asciiSlice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.ascii),
byteOffset,
encodingsMap.ascii,
dir)
},
base64: {
encoding: 'base64',
encodingVal: encodingsMap.base64,
byteLength: (string) => base64ByteLength(string, string.length),
write: (buf, string, offset, len) => buf.base64Write(string, offset, len),
slice: (buf, start, end) => buf.base64Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.base64),
byteOffset,
encodingsMap.base64,
dir)
},
hex: {
encoding: 'hex',
encodingVal: encodingsMap.hex,
byteLength: (string) => string.length >>> 1,
write: (buf, string, offset, len) => buf.hexWrite(string, offset, len),
slice: (buf, start, end) => buf.hexSlice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.hex),
byteOffset,
encodingsMap.hex,
dir)
}
};
function getEncodingOps(encoding) {
encoding += '';
switch (encoding.length) {
case 4:
if (encoding === 'utf8') return encodingOps.utf8;
if (encoding === 'ucs2') return encodingOps.ucs2;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'utf8') return encodingOps.utf8;
if (encoding === 'ucs2') return encodingOps.ucs2;
break;
case 5:
if (encoding === 'utf-8') return encodingOps.utf8;
if (encoding === 'ascii') return encodingOps.ascii;
if (encoding === 'ucs-2') return encodingOps.ucs2;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'utf-8') return encodingOps.utf8;
if (encoding === 'ascii') return encodingOps.ascii;
if (encoding === 'ucs-2') return encodingOps.ucs2;
break;
case 7:
if (encoding === 'utf16le' ||
StringPrototypeToLowerCase(encoding) === 'utf16le')
return encodingOps.utf16le;
break;
case 8:
if (encoding === 'utf-16le' ||
StringPrototypeToLowerCase(encoding) === 'utf-16le')
return encodingOps.utf16le;
break;
case 6:
if (encoding === 'latin1' || encoding === 'binary')
return encodingOps.latin1;
if (encoding === 'base64') return encodingOps.base64;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'latin1' || encoding === 'binary')
return encodingOps.latin1;
if (encoding === 'base64') return encodingOps.base64;
break;
case 3:
if (encoding === 'hex' || StringPrototypeToLowerCase(encoding) === 'hex')
return encodingOps.hex;
break;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
总结
计算机中存储数据的最小单位是位,但是存储信息最小的单位是字节,基于编码和字符的映射关系又实现了各种字符集,包括 ascii、iso、gbk 等,而国际标准化组织提出了 unicode 来包含所有字符,unicode 实现方案有若干种:utf-8、utf-16、utf-32,他们分别用不同的字节数来存储字符。其中 utf-8 是变长的,存储体积最小,所以被广泛应用。
Node.js 通过 Buffer 存储二进制数据,而转为字符串时需要指定编码方案,这个编码方案不只是包含字符集(charset),也支持 hex、base64 的方案,包括:
utf8、ucs2、utf16le、latin1、ascii、base64、hex
我们看了下 encoding 的 Node.js 源码,发现每种编码方案都会用实现一系列 api,这是一种多态的思想。