讲解 Linux Load 高如何排查的话题属于老生常谈了,但多数文章只是聚焦了几个点,缺少整体排查思路的介绍。所谓 “授人以鱼不如授人以渔”。本文试图建立一个方法和套路,来帮助读者对 Load 高问题排查有一个更全面的认识。
从消除误解开始
没有基线的 Load,是不靠谱的 Load
从接触 Unix/Linux 系统管理的第一天起,很多人就开始接触 System Load Average 这个监控指标了,然而,并非所有人都知道这个指标的真正含义。一般说来,经常能听到以下误解:
Load 高是 CPU 负载高……
传统 Unix 于 Linux 设计不同。Unix 系统,Load 高就是可运行进程多引发的,但对 Linux 来说不是。对 Linux 来说 Load 高可能有两种情况:
系统中处于 R 状态的进程数增加引发的
系统中处于 D 状态的进程数增加引发的
Loadavg 数值大于某个值就一定有问题……
Loadavg 的数值是相对值,受到 CPU 和 IO 设备多少的影响,甚至会受到某些软件定义的虚拟资源的影响。Load 高的判断需要基于某个历史基线 (Baseline),不能无原则的跨系统去比较 Load。
Load 高系统一定很忙…..
Load 高系统可以很忙,例如 CPU 负载高,CPU 很忙。但 Load 高,系统不都很忙,如 IO 负载高,磁盘可以很忙,但 CPU 可以比较空闲,如 iowait 高。这里要注意,iowait 本质上是一种特殊的 CPU 空闲状态。另一种 Load 高,可能 CPU 和磁盘外设都很空闲,可能支持锁竞争引起的,这时候 CPU 时间里,iowait 不高,但 idle 高。
Brendan Gregg 在最近的博客 [Linux Load Averages: Solving the Mystery] (http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html) 中,讨论了 Unix 和 Linux Load Average 的差异,并且回朔到 24 年前 Linux 社区的讨论,并找到了当时为什么 Linux 要修改 Unix Load Average 的定义。文章认为,正是由于 Linux 引入的 D 状态线程的计算方式,从而导致 Load 高的原因变得含混起来。因为系统中引发 D 状态切换的原因实在是太多了,绝非 IO 负载,锁竞争这么简单!正是由于这种含混,Load 的数值更加难以跨系统,跨应用类型去比较。所有 Load 高低的依据,全都应该基于历史的基线。本微信公众号也曾写过一篇相关文章,可以参见Linux Load Average那些事儿。
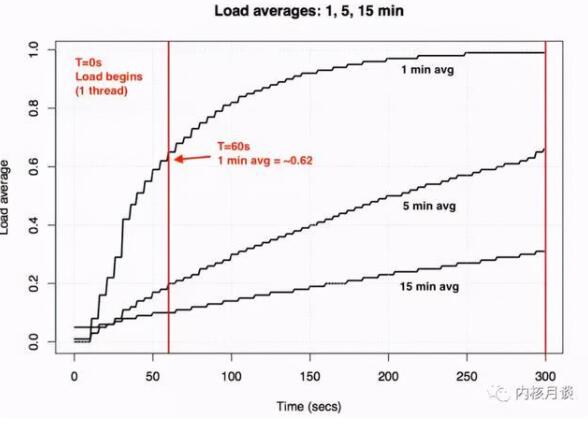
如何排查 Load 高的问题
如前所述,由于在 Linux 操作系统里,Load 是一个定义及其含混的指标,排查 loadavg 高就是一个很复杂的过程。其基本思路就是,根据引起 Load 变化的根源是 R 状态任务增多,还是 D 状态任务增多,来进入到不同的流程。
这里给出了 Load 增高的排查的一般套路,仅供参考:
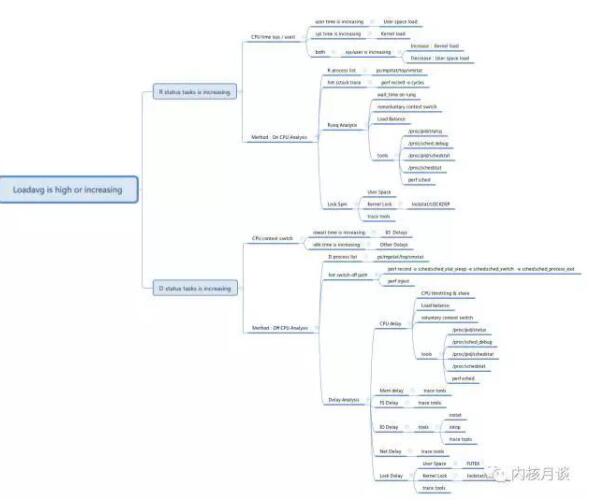
在 Linux 系统里,读取 /proc/stat 文件,即可获取系统中 R 状态的进程数;但 D 状态的任务数恐怕最直接的方式还是使用 ps 命令比较方便。而 /proc/stat 文件里 procs_blocked 则给出的是处于等待磁盘 IO 的进程数:

通过简单区分 R 状态任务增多,还是 D 状态任务增多,我们就可以进入到不同的排查流程里。下面,我们就这个大图的排查思路,做一个简单的梳理。
R 状态任务增多
即通常所说的 CPU 负载高。此类问题的排查定位主要思路是系统,容器,进程的运行时间分析上,找到在 CPU 上的热点路径,或者分析 CPU 的运行时间主要是在哪段代码上。
CPU user 和 sys 时间的分布通常能帮助人们快速定位与用户态进程有关,还是与内核有关。另外,CPU 的 run queue 长度和调度等待时间,非主动的上下文切换 (nonvoluntary context switch) 次数都能帮助大致理解问题的场景。
因此,如果要将问题的场景关联到相关的代码,通常需要使用 perf,systemtap, ftrace 这种动态的跟踪工具。
关联到代码路径后,接下来的代码时间分析过程中,代码中的一些无效的运行时间也是分析中首要关注的,例如用户态和内核态中的自旋锁 (Spin Lock)。
当然,如果 CPU 上运行的都是有非常意义,非常有效率的代码,那唯一要考虑的就是,是不是负载真得太大了。
D 状态任务增多
根据 Linux 内核的设计, D 状态任务本质上是 TASK_UNINTERRUPTIBLE 引发的主动睡眠,因此其可能性非常多。但是由于 Linux 内核 CPU 空闲时间上对 IO 栈引发的睡眠做了特殊的定义,即 iowait,因此iowait 成为 D 状态分类里定位是否 Load 高是由 IO 引发的一个重要参考。
当然,如前所述, /proc/stat 中的 procs_blocked 的变化趋势也可以是一个非常好的判定因 iowait引发的 Load 高的一个参考。
CPU iowait 高
很多人通常都对 CPU iowait 有一个误解,以为 iowait 高是因为这时的 CPU 正在忙于做 IO 操作。其实恰恰相反, iowait 高的时候,CPU 正处于空闲状态,没有任何任务可以运行。只是因为此时存在已经发出的磁盘 IO,因此这时的空闲状态被标识成了 iowait ,而不是 idle。
但此时,如果用 perf probe 命令,我们可以清楚得看到,在 iowait 状态的 CPU,实际上是运行在 pid 为 0 的 idle 线程上:
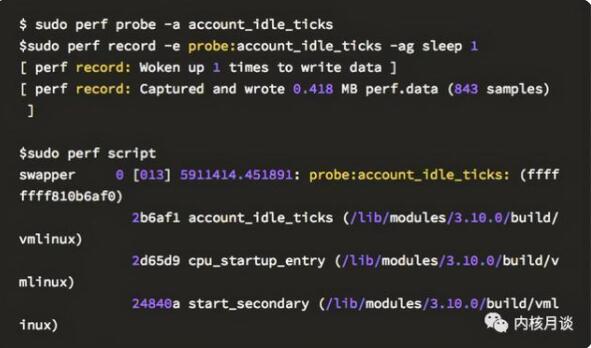
相关的 idle 线程的循环如何分别对 CPU iowait 和 idle 计数的代码,如下所示:
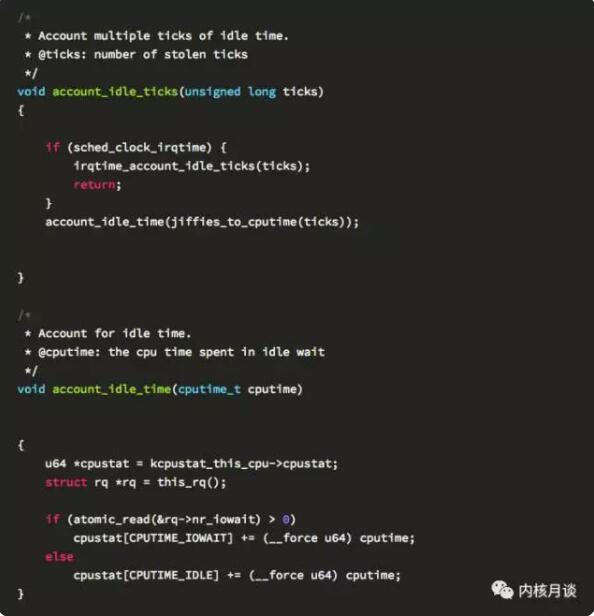
而 Linux IO 栈和文件系统的代码则会调用 io_schedule,等待磁盘 IO 的完成。这时候,对 CPU 时间被记为 iowait 起关键计数的原子变量 rq->nr_iowait 则会在睡眠前被增加。注意,io_schedule 在被调用前,通常 caller 会先将任务显式地设置成 TASK_UNINTERRUPTIBLE 状态:
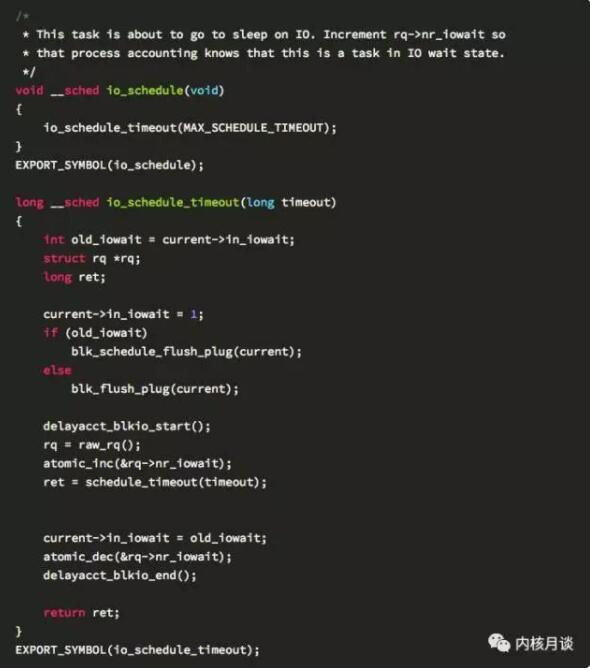
CPU idle 高
如前所述,有相当多的内核的阻塞,即 TASK_UNINTERRUPTIBLE 的睡眠,实际上与等待磁盘 IO 无关,如内核中的锁竞争,再如内存直接页回收的睡眠,又如内核中一些代码路径上的主动阻塞,等待资源。
Brendan Gregg 在最近的博客 [Linux Load Averages: Solving the Mystery] (http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html)中,使用 perf 命令产生的 TASK_UNINTERRUPTIBLE 的睡眠的火焰图,很好的展示了引起 CPU idle 高的多样性。本文不在赘述。
因此,CPU idle 高的分析,实质上就是分析内核的代码路径引起阻塞的主因是什么。通常,我们可以使用 perf inject 对 perf record 记录的上下文切换的事件进行处理,关联出进程从 CPU 切出 (swtich out) 和再次切入 (switch in) 的内核代码路径,生成一个所谓的 Off CPU 火焰图.
当然,类似于锁竞争这样的比较简单的问题,Off CPU 火焰图足以一步定位出问题。但是对于更加复杂的因 D 状态而阻塞的延迟问题,可能 Off CPU 火焰图只能给我们一个调查的起点。
例如,当我们看到,Off CPU 火焰图的主要睡眠时间是因为 epoll_wait 等待引发的。那么,我们继续要排查的应该是网络栈的延迟,即本文大图中的 Net Delay 这部分。
至此,你也许会发现,CPU iowait 和 idle 高的性能分析的实质就是 延迟分析。这就是大图按照内核中资源管理的大方向,将延迟分析细化成了六大延迟分析:
CPU 延迟
内存延迟
文件系统延迟
IO 栈延迟
网络栈延迟
锁及同步原语竞争
任何上述代码路径引发的 TASK_UNINTERRUPTIBLE 的睡眠,都是我们要分析的对象!
以问题结束
限于篇幅,本文很难将其所涉及的细节一一展开,因为读到这里,你也许会发现,原来 Load 高的分析,实际上就是对系统的全面负载分析。怪不得叫 System Load 呢。这也是 Load 分析为什么很难在一篇文章里去全面覆盖。