前言
分布式系统设计成主从节点主要是为了保障数据一致性,主从设计是一种最直观的数据一致性保障机制。
比如主从复制,主节点负责写,从节点负责读,提高读的性能。从节点定期通过心跳与主节点沟通,一旦主节点挂掉了,从节点马上接手主节点的任务。
但是主节点暂时失去响应,如瞬时负载过高,网络拥塞或者其他原因导致主节点暂时失去响应,超过响应超时时间,这个时候从节点启动,承担起leader的职责,但是原先的主节点又恢复了服务。这个时候,如果没有选举机制(不能仅仅自己宣告自己是leader,还要广而告之,让其他服务器或者客户端知道自己是leader),有可能会存在两个leader节点,导致集群发生混乱。
所以有了以下关于大数据框架主从选举的总结,赶快收藏吧!总有一个不经意时刻你会用到。
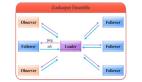
Zookeeper选举
Zookeeper介绍
Zookeeper从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper特点
集群种只要有半数以上节点存活,Zookeeper集群就能正常提供服务。所以这就是选举机制的奇数原则(Zookeeper适合安装奇数台服务)。
一个领导者Leaders和多个跟随者Follower组成的集群。
Zookeeper的选举机制
全新集群选举
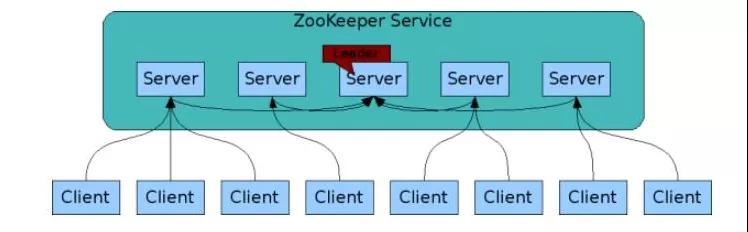
假设有五台服务器组成的Zookeeper集群,它们的id从Service1到Service5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING。
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING。
- 服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING。
- 服务器5启动,同第4步一样当FOLLOWING。
非全新集群选举
对于运行正常的zookeeper集群,中途有机器down掉,需要重新选举时,选举过程就需要加入数据ID、服务器ID、和逻辑时钟。
逻辑时钟:这个值从0开始,每次选举必须一致。小的选举结果被忽略,重新投票(除去选举次数不完整的服务器)。
数据id:数据新的version大,数据每次更新都会更新version。数据id大的胜出(选出数据最新的服务器)。
服务器id:即myid。数据id相同的情况下,服务器id大的胜出(数据相同的情况下,选择服务器id最大,即权重最大的服务器)。
Kafka依赖Zookeeper的选举
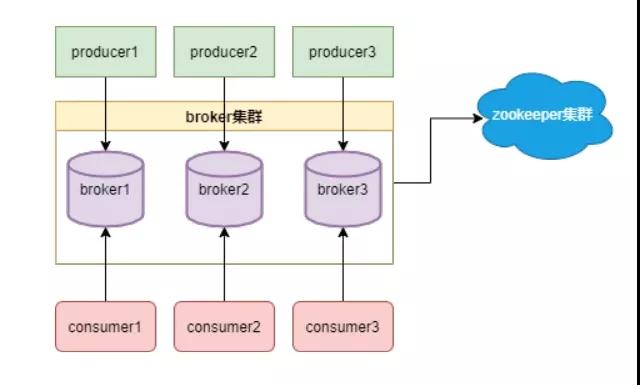
Kafka依赖ZK做了哪些事
ZooKeeper 作为给分布式系统提供协调服务的工具被 kafka 所依赖。在分布式系统中,消费者需要知道有哪些生产者是可用的,而如果每次消费者都需要和生产者建立连接并测试是否成功连接,那效率也太低了,显然是不可取的。而通过使用 ZooKeeper 协调服务,Kafka 就能将 Producer,Consumer,Broker 等结合在一起,同时借助 ZooKeeper,Kafka 就能够将所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现负载均衡。
Kafka选举
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
因此这个集合中的任何一个节点随时都可以被选为leader。ISR在ZooKeeper中维护。ISR中有f+1个节点(follow+leader),就可以允许在f个节点down掉的情况下不会丢失消息并正常提供服。ISR的成员是动态的,如果一个节点被淘汰了,当它重新达到“同步中”的状态时,他可以重新加入ISR。因此如果leader宕了,直接从ISR中选择一个follower就行。
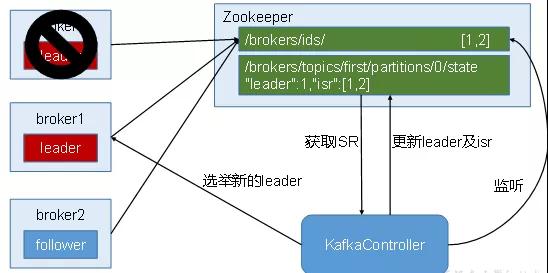
如果全挂呢?
一旦所有节点都down了,Kafka不会保证数据的不丢失。所以当副本都down掉时,必须及时作出反应。等待ISR中的任何一个节点恢复并担任leader。
附:Kafka为什么要放弃ZK
本身就是一个分布式系统,但是需要另一个分布式系统来管理,复杂性无疑增加了。
部署的时候必须要部署两套系统,的运维人员必须要具备的运维能力。
Controller故障处理:依赖一个单一节点跟进行交互,如果这个节点发生了故障,就需要从中选择新的,新的选举成功后,会重新从拉取元数据进行初始化,并且需要通知其他所有的更新。老的需要关闭监听、事件处理线程和定时任务。分区数非常多时,这个过程非常耗时,而且这个过程中集群是不能工作的。
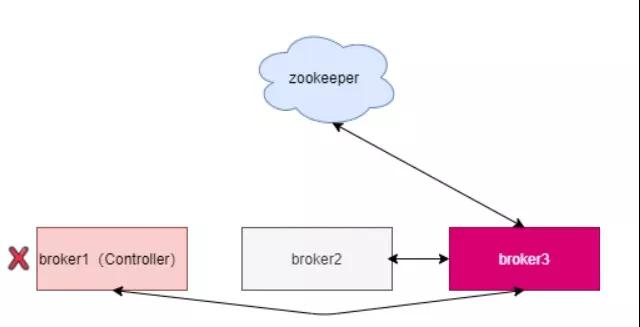
当分区数增加时,保存的元数据变多,集群压力变大
基于ZooKeeper的Hadoop高可用
HDFS 高可用
介绍
一个典型的HA集群,NameNode会被配置在两台独立的机器上,在任何时间上,一个NameNode处于活动状态,而另一个NameNode处于备份状态,活动状态的NameNode会响应集群中所有的客户端,备份状态的NameNode只是作为一个副本,保证在必要的时候提供一个快速的转移。所以对于HDFS来说,高可用其实就是针对NameNode的高可用。因为NameNode保存着集群的元数据信息,一旦丢失整个集群将不复存在。
主备切换控制器 ZKFailoverController:ZKFC 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
原理
当HDFS的两台NN启动时,ZKFC(Zookeeper FailoverController)也会启动,ZKFC会向ZK上写一个临时序列化的节点(默认节点名是:/hadoop-ha)并取得和ZK的连接,一旦NN挂掉,那么ZKFC也会挂掉,该节点会被ZK自动删除掉,ZKFC有Watcher机制(当子节点发生变化时触动),另一个伴随着NN启动的ZKFC发现子节点变化了,是不是排在第一位,是,就通知第二台NN开始接管,向JN同步数据(下载IDS文件并和FImage合并,并生成新的FImage),将元数据都变成最新的,若是挂掉的NN重新启动,那么ZKFC还会向ZK写个节点,等现接管的NN挂掉后再接管成为Master。
什么是ZKFC?
- ZKFC是一个Zookeeper的客户端,它主要用来监测和管理NameNodes的状态,每个NameNode机器上都会运行一个ZKFC程序,它的职责主要有:一是健康监控。ZKFC间歇性的ping NameNode,得到NameNode返回状态,如果NameNode失效或者不健康,那么ZKFS将会标记其为不健康;
- Zookeeper会话管理。当本地NaneNode运行良好时,ZKFC将会持有一个Zookeeper session,如果本地NameNode为Active,它同时也持有一个“排他锁”znode,如果session过期,那么次lock所对应的znode也将被删除;
- 选举。当集群中其中一个NameNode宕机,Zookeeper会自动将另一个激活。
内部操作与原理
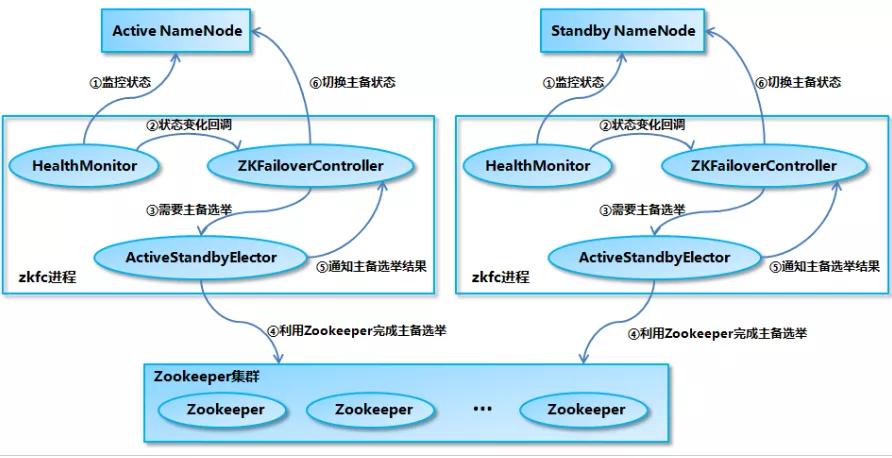
HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
几句话描述就是:ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
Yarn高可用
介绍
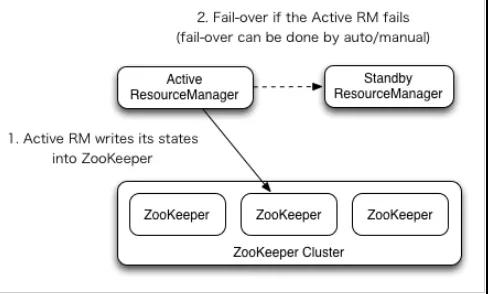
YARN ResourceManager 的高可用与 HDFS NameNode 的高可用类似但是 ResourceManager 不像 NameNode ,没有那么多的元数据信息需要维护,所以它的状态信息可以直接写到 Zookeeper 上,并依赖 Zookeeper 来进行主备选举。
内部操作与原理
- 在ZooKeeper上会有一个/yarn-leader-election/yarn1的锁节点,所有的ResourceManager在启动的时候,都会去竞争写一个Lock子节点:/yarn-leader-election/yarn1/ActiveBreadCrumb,该节点是临时节点。ZooKeepr能够保证最终只有一个ResourceManager能够创建成功。创建成功的那个ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
- RM会把job的信息存放在zookeeper的/rmstore目录下,active RM会向这个目录写app的信息。当active RM挂掉之后,standby RM会通过zkfc切换为active状态,然后从zookeeper的/rmstore目录下读取相应的作业信息。重新构建作业的内存信息,启动内部服务,开始接受NM的心跳信息,构建集群的资源信息,并且接受客户端的作业提交请求。
其他与总结
在大数据领域,还有许多框架依赖与Zookeeper去选择主从:比如Hbase集群,Kudu集群,Impala集群等等,最底层的原理大径相同。
总结
选举:Zookeeper能够很容易的实现集群管理的功能,若有多台Server组成一个服务集群,则必须要一个leader知道集群中每台机器的服务状态,从而做出调整重新分配服务策略。当集群中增加一台或多台Server时,leader同样需要知道。Zookeeper不仅能够维护当前的集群中机器的服务状态,而且能够选出一个leader来管理集群。
HA(分布式锁的应用):Master挂掉之后迅速切换到slave节点。