今日凌晨,Cerebras Systems宣布推出 世界上第一个人类大脑规模的AI解决方案,一台CS-2 AI计算机可支持超过120万亿参数规模的训练。 相比之下,人类大脑大约有100万亿个突触。
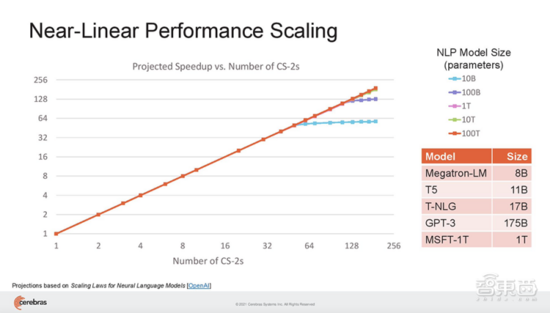
此外,Cerebras还 实现了192台CS-2 AI计算机近乎线性的扩展,从而打造出包含高达1.63亿个核心的计算集群。

Cerebras成立于2016年,迄今在14个国家拥有超过350位工程师,此前Cerebras推出的世界最大计算芯片WSE和WSE-2一度震惊业界。

WSE-2采用7nm工艺,是一个面积达46225平方毫米的单晶圆级芯片,拥有2.6万亿个晶体管和85万个AI优化核,无论是核心数还是片上内存容量均远高于迄今性能最强的GPU。
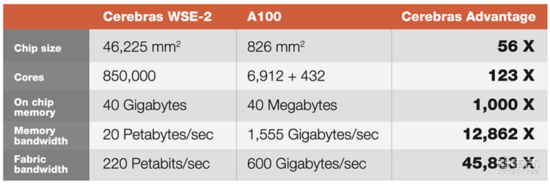
WSE-2被集成在Cerebras CS-2 AI计算机中。随着近年业界超大规模AI模型突破1万亿参数,小型集群难以支撑单个模型的高速训练。
而Cerebras最新公布的成果, 将单台CS-2机器可支持的神经网络参数规模,扩大至现有最大模型的100倍——达到120万亿参数 。

在国际芯片架构顶会Hot Chips上,Cerebras联合创始人兼首席硬件架构师Sean Lie详细展示了实现这一突破的 新技术组合, 包括4项创新:
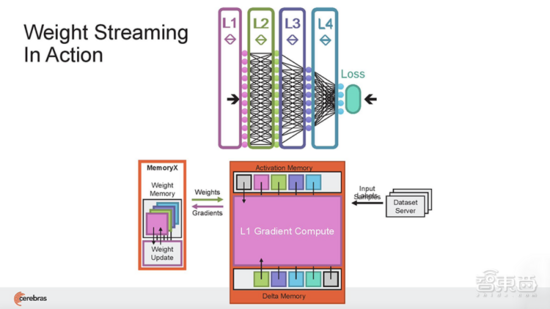
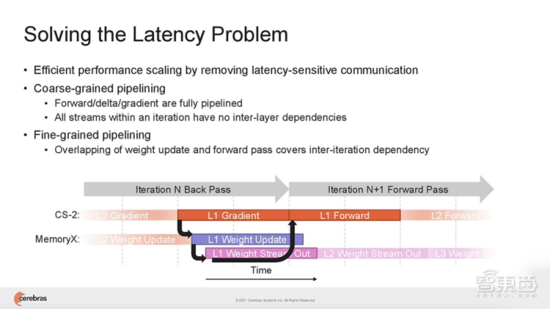
(1)Cerebras Weight Streaming:一种新的软件执行架构, 首次实现在芯片外存储模型参数的能力,同时提供像片上一样的训练和推理性能 。这种新的执行模型分解了计算和参数存储,使得扩展集群大小和速度更加独立灵活,并消除了大型集群往往面临的延迟和内存带宽问题,极大简化工作负载分布模型, 使得用户无需更改软件,即可从使用1台CS-2扩展到192台CS-2。
(2)Cerebras MemoryX:一种内存扩展技术,为WSE-2提供高达2.4PB的片外高性能存储,能保持媲美片上的性能。 借助MemoryX,CS-2可以支持高达120万亿参数的模型。

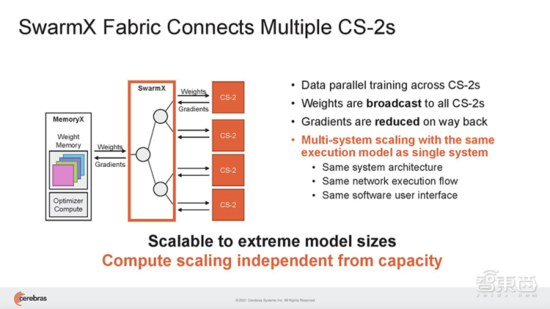
(3)Cerebras SwarmX:是一种高性能、AI优化的通信结构,将片上结构扩展至片外,使Cerebras能够 连接多达192台CS-2的1.63亿个AI优化核 ,协同工作来训练单个神经网络。
(4)Selectable Sparsity:一种动态稀疏选择技术,使用户能够在模型中选择权重稀疏程度,并直接减少FLOP和解决时间。权重稀疏在机器学习研究领域一直颇具挑战性,因为它在GPU上效率极低。该技术使CS-2能够加速工作,并使用包括非结构化和动态权重稀疏性在内的各种可用稀疏性类型在更短的时间内生成答案。

Cerebras首席执行官兼联合创始人Andrew Feldman称这推动了行业的发展。阿贡国家实验室副主任Rick Stevens亦肯定这一发明,认为这将是我们第一次能够探索大脑规模的模型,为研究和见解开辟广阔的新途径。
一、 Weight Streaming :存算分离,实现片外存储模型参数
使用大型集群解决AI问题的最大挑战之一,是为特定的神经网络设置、配置和优化它们所需的复杂性和时间。软件执行架构Cerebras Weight Streaming恰恰能降低对集群系统编程的难度。

Weight Streaming建立在WSE超大尺寸的基础上,其计算和参数存储完全分离。通过与最高配置2.4PB的存储设备MemoryX结合,单台CS-2可支持运行拥有120万亿个参数的模型。
参与测试的120万亿参数神经网络由Cerebras内部开发,不是已公开发布的神经网络。
在Weight Streaming中,模型权重存在中央芯片外存储位置,流到晶圆片上,用于计算神经网络的每一层。在神经网络训练的delta通道上,梯度从晶圆流到中央存储区MemoryX中用于更新权重。
与GPU不同,GPU的片上内存量很小,需要跨多个芯片分区大型模型,而WSE-2足够大,可以适应和执行超大规模的层,而无需传统的块或分区来分解。
这种无需分区就能适应片上内存中每个模型层的能力,可以被赋予相同的神经网络工作负载映射,并独立于集群中所有其他CS-2对每个层进行相同的计算。
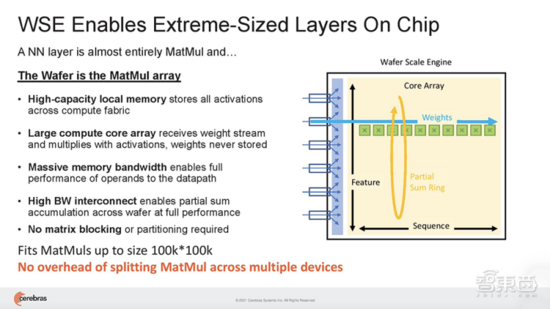
这带来的好处是, 用户无需进行任何软件更改,就能很方便地将模型从运行在单台CS-2上,扩展到在任意大小的集群上。也就是说,在大量CS-2系统集群上运行AI模型,编程就像在单台CS-2上运行模型一样。
Cambrian AI创始人兼首席分析师Karl Freund评价道:“Weight Streaming的执行模型非常简洁、优雅,允许在CS-2集群难以置信的计算资源上进行更简单的工作分配。通过Weight Streaming,Cerebras消除了我们今天在构建和高效使用巨大集群方面所面临的所有复杂性,推动行业向前发展,我认为这将是一场变革之旅。”
二、 MemoryX :实现百万亿参数模型
拥有100万亿个参数的人脑规模级AI模型,大约需要2PB字节的内存才能存储。
前文提及模型参数能够在片外存储并高效地流至CS-2,实现接近片上的性能,而存储神经网络参数权重的关键设施,即是Cerebras MemoryX。

MemoryX是DRAM和Flash的组合,专为支持大型神经网络运行而设计,同时也包含精确调度和执行权重更新的智能。
其架构具有可扩展性, 支持从4TB至2.4PB的配置,支持2000亿至120万亿的参数规模 。
三、 SwarmX :几乎线性扩展性能,支持 192台 CS-2 互连
虽然一台CS-2机器就可以存储给定层的所有参数,但Cerebras还提议用一种高性能互连结构技术SwarmX,来实现数据并行性。
该技术通过将Cerebras的片上结构扩展至片外,扩展了AI集群的边界。
从历史上看,更大的AI集群会带来显著的性能和功率损失。在计算方面,性能呈亚线性增长,而功率和成本呈超线性增长。随着越来越多的图形处理器被添加到集群中,每个处理器对解决问题的贡献越来越小。
SwarmX结构既做通信,也做计算,能使集群实现 接近线性的性能扩展。这 意味着如果扩展至16个系统,训练神经网络的速度接近提高16倍。 其结构独立于MemoryX进行扩展,每个MemoryX单元可用于任意数量的CS-2。
在这种完全分离的模式下, SwarmX结构支持从2台CS-2扩展到最多192台,由于每台CS-2提供85万个AI优化核,因此将支持多达1.63亿个AI优化核的集群。
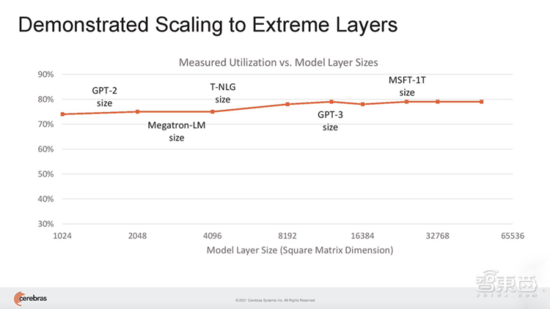
Feldman说,CS-2的利用率要高得多。其他方法的利用率在10%~20%之间,而Cerebras在最大网络上的利用率在70%~80%之间。“今天每个CS2都取代了数百个GPU,我们现在可以用集群方法取代数千个GPU。”
四、 Selectable Sparsity :动态稀疏提升计算效率
稀疏性对提高计算效率至为关键。随着AI社区努力应对训练大型模型的成本呈指数级增长,用稀疏性及其他算法技术来减少将模型训练为最先进精度所需的计算FLOP愈发重要。
现有稀疏性研究已经能带来10倍的速度提升。
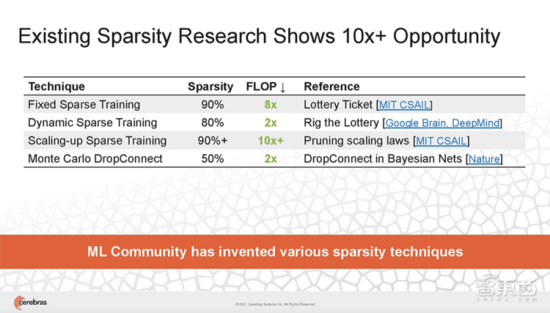
为了加速训练,Cerebras提出一种新的稀疏方法Selectable Sparsity,来减少找到解决方案所需的计算工作量,从而缩短了应答时间。
Cerebras WSE基于一种细粒度的数据流架构,专为稀疏计算而设计,其85万个AI优化核能够单独忽略0,仅对非0数据进行计算。这是其他架构无法做到的。
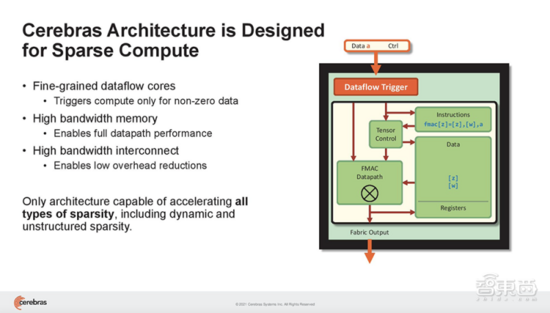
在神经网络中,稀疏有多种类型。稀疏性可以存在于激活和参数中,可以是结构化或非结构化。
Cerebras架构特有的数据流调度和巨大的内存带宽,使此类细粒度处理能加速动态稀疏、非结构化稀疏等一切形式的稀疏。结果是,CS-2可以选择和拨出稀疏,以产生特定程度的FLOP减少,从而减少应答时间。
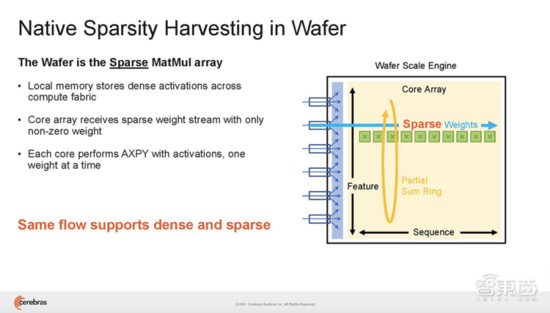
结语:新技术组合让集群扩展不再复杂
大型集群历来受设置和配置挑战的困扰,准备和优化在大型GPU集群上运行的神经网络需要更多时间。为了在GPU集群上实现合理的利用率,研究人员往往需要人工对模型进行分区、管理内存大小和带宽限制、进行额外的超参数和优化器调优等复杂而重复的操作。
而通过将Weight Streaming、MemoryX和SwarmX等技术相结合,Cerebras简化了大型集群的构建过程。它开发了一个全然不同的架构,完全消除了扩展的复杂性。由于WSE-2足够大,无需在多台CS-2上划分神经网络的层,即便是当今最大的网络层也可以映射到单台CS-2。
Cerebras集群中的每台CS-2计算机将有相同的软件配置,添加另一台CS-2几乎不会改变任何工作的执行。因此,在数十台CS-2上运行神经网络与在单个系统上运行在研究人员看来是一样的,设置集群就像为单台机器编译工作负载并将相同的映射应用到所需集群大小的所有机器一样简单。
总体来说,Cerebras的新技术组合旨在加速运行超大规模AI模型,不过就目前AI发展进程来看,全球能用上这种集群系统的机构预计还很有限。