













本文转自雷锋网,如需转载请至雷锋网官网申请授权。
人工智能系统需要依赖大量数据,然而数据的流转过程以及人工智能模型本身都有可能泄漏敏感隐私数据。
例如,在数据流转的任意阶段,恶意攻击者可以对匿名数据集发起攻击,从而窃取数据;
例如,在数据发布阶段,恶意攻击者可以使用身份重识别对匿名数据集发起攻击,从而窃取隐私信息......
学界针对上述隐私泄露问题提出了多种针对性的保护方法,基于差分隐私和同态加密的联邦学习是一种常见的隐私保护方法。
联邦学习在 2015 年提出,其能在不暴露用户数据的条件下进行多方机器学习模型的训练,以期保护隐私信息。
但由谷歌所提出的联邦学习,不仅必须保证数据集特征空间一致,且引入噪声对模型精确度造成影响,此外,还存在部分敏感信息传递等问题,这些不足限制了联邦学习在实际生产中的应用前景。
2018年,联邦迁移学习理论被提出。该理论中,训练所使用的多个数据集,无需保证特征空间的一致。另外,该理论使用同态加密替代差分隐私对隐私数据进行保护。这些改进为联邦学习在金融、医疗等场景中的应用带来了极大的便利。但是联邦迁移学习在实际使用中暴露出了严重的性能缺陷。
针对这个问题,来自于香港科技大学、星云Clustar以及鹏城实验室的研究人员联合发表了《量化评估联邦迁移学习(Quantifying the Performance of Federated Transfer Learning)》。该论文通过对联邦迁移学习框架进行研究,提出了联邦学习在实际应用中所面临的性能方面的挑战,并给出了相应优化方案。

论文作者:敬清贺,王伟俨,张骏雪,田晗,陈凯
编译: 程孝典(星云Clustar软件工程师)
论文:https://arxiv.org/abs/1912.12795
性能方面的挑战主要包括:
1、联邦迁移学习的性能瓶颈主要来自于计算和传输;
2、跨进程通信和内存拷贝是当前联邦迁移学习实现的主要性能瓶颈;
3、不同的参与方往往位于相距较远的两个站点中,只能通过高延迟的广域网传输数据,因此耗时也远高于分布式机器学习。
一、联邦迁移学习简介
联邦学习理论基于查分隐私对数据进行保护,若干数据持有者可以在原始数据不离开本地的前提下实现联合模型训练。但是最初的联邦学习体系中,参与者之间必须保证数据的特征空间完全相同。举例说明,如果A公司持有的数据包含用户性别、年龄、年收入等信息,则B公司的数据也必须包含这些信息,才能和A公司进行联邦学习。除此之外,该体系还存在噪声对模型精确度造成影响、仍存在部分敏感信息传递等问题,这就限制了联邦学习在实际生产中的应用前景。
为了摆脱这一系列限制,联邦迁移学习(Federated Transfer Learning)于2018年被提出。在该理论中,训练所使用的多个数据集,无需保证特征空间的一致。另外,该理论使用同态加密替代差分隐私对隐私数据进行保护。这些改进为联邦学习对金融、医疗等场景中的应用带来了极大的便利。但是联邦迁移学习在实际使用中遭遇了严重的性能不足问题。
联邦迁移学习的典型工作流程如图一所示,其中需要三个不同的参与者:Guest、Host和Arbiter。其中Guest和Host是数据持有者,同时也负责主要的数值计算和加密工作;Arbiter在计算开始前生成密钥,并发送至Host和Guest,此外,Arbiter负责训练过程中的梯度聚合以及收敛检查。如果Host和Guest所持有的数据中样本不同而特征相同,这种联邦迁移学习被称为同构的或横向的(homogeneous);如果双方数据集样本相同而特征不同,则称联邦迁移学习为异构的或纵向的(heterogeneous)。
在训练过程中,Host和Guest首先使用本地数据进行初步计算,并对计算结果进行加密,这些中间结果可以被用于梯度和损失的计算。接下来,双方将加密结果发送至Arbiter进行聚合,Arbiter对密文进行解密后,返回给Host和Guest,双方使用接收的数值更新本地模型。联邦迁移学习需要重复此训练过程,直至模型收敛。
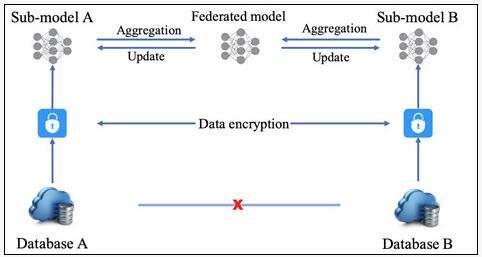
图一:联邦迁移学习工作流程
二、联邦迁移学习性能分析
从联邦迁移学习的工作流程中,可以发现它和分布式机器学习在一些方面上十分相似,二者均包含多个持有不同数据的工作节点,且均根据聚合的结果更新模型。但是,两种体系之间存在相当明显的区别:在分布式机器学习中,参数服务器(parameter server)是中心调度节点,负责将数据和计算分配到不同的工作节点中从而优化训练性能;在联邦迁移学习中,不同的数据持有者对本方工作节点和数据都有着完全独立的管理,除此之外,联邦迁移学习中所使用的同态加密,将极大地增加计算和数据传输时间。
因此,和分布式机器学习相比,联邦迁移学习是一种复杂度更高的系统,也可以认为分布式机器学习性能是衡量联邦迁移学习性能的合适指标。近年来,有关分布式机器学习的方案设计以及性能优化的研究十分火热,而联邦迁移学习则鲜有人踏足。量化分布式机器学习和联邦迁移学习的性能差距,对联邦迁移学习的性能优化,具有启发性的借鉴和参考价值。
图二为分布式机器学习和联邦迁移学习在使用相同数据集训练相同模型的性能对比图。图(a)代表模型训练端到端性能对比,根据测试结果,两种系统的运行时间差距在18倍以上。根据分布式机器学习中的经验,计算和数据传输往往是系统运行中时间占比最高的两个部分,因此图(b)和图(c)又分别展示了两种系统在计算和数据传输中的耗时对比,结果显示,联邦迁移学习的这两段耗时,均在分布式机器学习的20倍左右,这也证实了联邦迁移学习的性能瓶颈主要来自于计算和传输。因此,接下来,我们将分别从这两个方面对联邦迁移学习的时间开销进行分析。
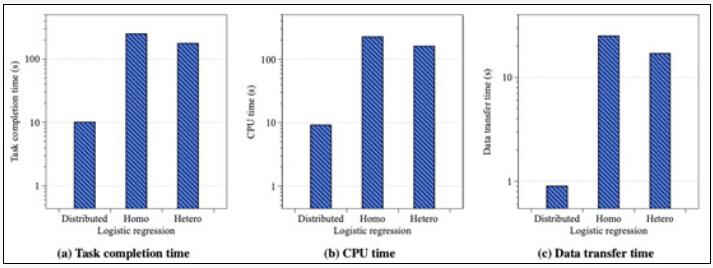
图二:分布式机器学习和联邦迁移学习(包括横向和纵向)的性能对比
三、计算开销分析
1、性能分析
为了进行深入的分析,我们将计算时间划分为两个部分:模型训练(数值计算)和额外操作(包括跨进程通信和内存拷贝等),如图三所示。我们从测试中发现,训练任务的端到端时间开销中,仅有18%左右的时间用于数值计算,而绝大部分的时间都花费在了内存拷贝等额外工作中。
具体说明额外操作,联邦迁移学习的底层实现中需要使用不同编语言以实现不同的功能,而跨语言环境的数据交换和内存拷贝耗时较长,如Python和Java虚拟机(JVM)之间的数据传递。此外,联邦迁移学习底层需要开启多个进程,分别管理任务创建、数据传递等工作,而跨进程通信同样开销巨大。总的来说,跨进程通信和内存拷贝是当前联邦迁移学习实现的主要性能瓶颈。
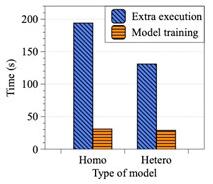
图三:模型训练时间和额外时间开销对比
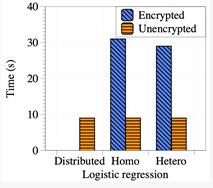
图四:加密运算对模型训练时间的影响
而在模型训练时间中,一个较为明显的时间开销就是同态加密。联邦迁移学习中所使用的部分同态加密将原本的浮点运算扩展为数千位大整数之间的运算,这显然大幅降低了运算性能。因此,图四对比了密态模型训练与纯明文模型训练的运行时间。测试结果显示同态加密运算为模型训练过程引入了超过两倍的额外时间开销。因此,加速同态加密运算是优化联邦迁移学习性能的可行方案。
2、优化方案
从降低额外开销的角度,可以借鉴Unix domain socket或者JTux等以实现更高效率的跨进程通信。同时,使用JVM本地内存,可以有效提升跨环境内存拷贝速度。
从加速数值计算的角度,可以通过使用高性能计算硬件实现高吞吐率的同态加密运算。现如今以GPU和FPGA为代表的计算硬件设备,由于其充足的计算、存储和通信资源,可以高并发地处理大部分数值计算。通过大幅降低同态加密开销,可以有效提升模型训练整体性能。
四、数据传输开销分析
1、性能分析
除了计算开销的明显上涨,联邦迁移学习中增长接近20倍的数据传输开销也值得注意。造成该现象的原因主要有三个:首先,在计算开销中,同态加密运算大大提升了数据位宽,这不仅增加了计算时间,也大幅增加了需要传输的总数据量,从而对数据传输时间造成了影响;其次,与传统的机器学习算法相比,联邦迁移学习中为了保护数据隐私,增加了不同参与方之间的数据交换,频繁的数据传输必然带来总传输时间的上升;最后,分布式机器学习往往部署在密集的数据中心网络中,数据传输延时非常低,因此跨节点通信带来的开销也相对较低,而反观联邦迁移学习,在实际应用中,不同的参与方往往位于相距较远的两个站点中,只能通过高延迟的广域网传输数据,因此耗时也远高于分布式机器学习,如图四所示,当我们将联邦迁移学习的不同参与方部署在世界各地的数据中心网络中时,数据带宽较低,数据传输延迟将占到整体运行时间的30%以上,造成十分严重的影响。
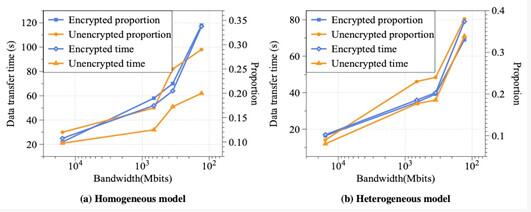
图四:当参与方部署在不同地理位置时,数据传输时间以及在端到端运行时间中的占比
2、优化方案
在跨站点多方数据交换中,网络质量扮演着重要的角色,而密集的通信很容易造成网络拥塞,因此,探索网络拥塞控制技术以提升数据传输性能是一种可行的解决方案。以PCC算法为代表的拥塞控制算法,可以通过细粒度的拥塞控制规则优化长距离数据传输的网络性能,进而提升联邦迁移学习的整体性能。
五、总结
作为机器学习在隐私计算中的拓展延伸,联邦迁移学习对打破数据孤岛,实现数据的更高价值有极其重要的作用。但是和所有的安全计算系统类似,性能和安全之间的平衡难以把控。现有的联邦迁移学习系统框架还远无法满足实际生产中的性能需求。通过深入的性能分析,计算、内存拷贝以及数据传输等环节中的开销问题,都是联邦迁移学习的端到端性能恶化的重要原因。为了实现联邦迁移学习在更多场景中的落地,结合多样的解决方案对各个环节进行针对性优化不可或缺。




















