为什么我们要了解ddd?
作为一个开发者,我们肯定接手过其他的人的项目。我想你一定有个这样的经历:
面对冗杂的系统,模块彼此关联,没有人能描述清楚每个细节,没有文档,即使有文档也和系统对不上。当新需求需要修改一个功能时,往往光回顾该功能涉及的流程就需要很长时间,更别提修改带来的不可预知的影响面。于是 RD 就加开关,小心翼翼地切流量上线,一有问题赶紧关闭开关。
面对此般场景,你要么跑路,要么重构。重构是克服演进式设计中大杂烩问题的主力,通过在单独的类及方法级别上做一系列小步重构来完成,我们可以很容易重构出一个独立的类来放某些通用的逻辑,但是,你会发现你很难给它一个业务上的含义,只能给予一个技术维度描绘的含义。你正在一边重构一边给后人挖坑。
作为一个架构师,在软件开发中如何降低系统复杂度是一个永恒的挑战,虽然通过一系列的设计模式或范例来降低一些常见的复杂度。但是问题在于,这些理念是通过技术手段解决技术问题,但并没有从根本上解决业务的问题。
如果你也有这方面的苦恼,那么ddd 的思想也许能为你带来启发。
DDD 和传统数据驱动的区别
DDD 全程是 Domain-Driven Design,中文叫领域驱动设计,是一套应对复杂软件系统分析和设计的面向对象建模方法论。
什么是数据驱动
传统的数据驱动开发模式,View、Service、dao这种三层分层模式,开发者会很自然的写出过程式代码,这种开发方式中的对象只是数据载体,而没有行为,是一种贫血对象模型。以数据为中心,以数据库ER图为设计驱动,分层架构在这种开发模式下可以认为是数据处理和实现的过程。
什么是领域驱动
以前的系统分析和设计是分开的,导致需求和成品非常容易出现偏差,两者相对独立,还会导致沟通困难,DDD 则打破了这种隔阂,提出了领域模型概念,统一了分析和设计编程,使得软件能够更灵活快速跟随需求变化。
DDD 的宏观理念其实并不难懂,但是如同 REST 一样,DDD 也只是一个设计思想,缺少一套完整的规范,导致DDD新手落地困难。
由于 DDD 不是一套框架,而是一种架构思想,所以在代码层面缺乏了足够的约束,导致 DDD 在实际应用中上手门槛很高,甚至可以说绝大部分人都对 DDD 的理解有所偏差。举个例子(贫血域模型)在实际应用当中层出不穷,而一些仍然火热的 ORM 工具比如 Hibernate,Entity Framework 实际上助长了贫血模型的扩散。同样的,传统的基于数据库技术以及 MVC 的四层应用架构(UI、Business、Data Access、Database),在一定程度上和 DDD 的一些概念混淆,导致绝大部分人在实际应用当中仅仅用到了 DDD 的建模的思想,而其对于整个架构体系的思想无法落地。
从单机的时代,服务化的架构还局限于单机 +LB 用 MVC 提供 Rest 接口供外部调用,到今天,在一个所有的东西都能被称之为“服务”的时代(XAAS),人们在踩过诸多拆分服务的坑(拆分过细导致服务爆炸、拆分不合理导致频分重构等)之后,开始死锁原因了。DDD 的思想让我们能冷静下来,去思考到底哪些东西可以被服务化拆分,哪些逻辑需要聚合,才能带来最小的维护成本,而不是简单的去追求开发效率。
有了 DDD 的指导,加之微服务的事件,才是完美的架构。
DDD 与微服务的关系
系统的复杂度越来越来高是必然趋势,原因可能来自自身业务的演进,也有可能是技术的创新,然而一个人和团队对复杂性的认知是有极限的,就像一个服务器的性能极限一样,解决的办法只有分而治之,将大问题拆解为小问题,最终突破这种极限。微服务在这方面都给出来了理论指导和最佳实践,诸如注册中心、熔断、限流等解决方案,但微服务并没有对“应对复杂业务场景”这个问题给出合理的解决方案,这是因为微服务的侧重点是治理,而不是分。
我们都知道,架构一个系统的时候,应该从以下几方面考虑:
- 功能维度
- 质量维度(包括性能和可用性)
- 工程维度
微服务在第二个做得很好,但第一个维度和第三个维度做的不够。这就给 DDD 了一个“可乘之机”,DDD 给出了微服务在功能划分上没有给出的很好指导这个缺陷。所以说它们在面对复杂问题和构建系统时是一种互补的关系。
DDD 与微服务如何协作
知道了 DDD 与微服务还不够,我们还需要知道他们是怎么协作的。
一个系统(或者一个公司)的业务范围和在这个范围里进行的活动,被称之为领域,领域是现实生活中面对的问题域,和软件系统无关,领域可以划分为子域,比如电商领域可以划分为商品子域、订单子域、发票子域、库存子域 等,在不同子域里,不同概念会有不同的含义,所以我们在建模的时候必须要有一个明确的边界,这个边界在 DDD 中被称之为限界上下文,它是系统架构内部的一个边界,《整洁之道》这本书里提到:
系统架构是由系统内部的架构边界,以及边界之间的依赖关系所定义的,与系统中组件之间的调用方式无关。
所谓的服务本身只是一种比函数调用方式成本稍高的,分割应用程序行为的一种形式,与系统架构无关。
所以复杂系统划分的第一要素就是划分系统内部架构边界,也就是划分上下文,以及明确之间的关系,这对应之前说的第一维度(功能维度),这就是 DDD 的用武之处。其次,我们才考虑基于非功能的维度如何划分,这才是微服务发挥优势的地方。
假如我们把服务划分成 ABC 三个上下文:
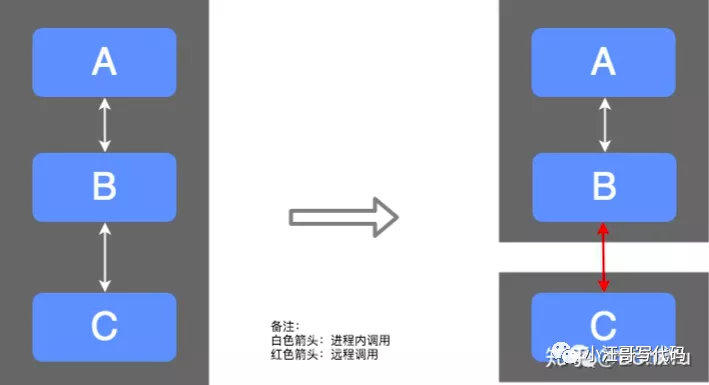
我们可以在一个进程内部署单体应用,也可以通过远程调用来完成功能调用,这就是目前的微服务方式,更多的时候我们是两种方式的混合,比如 A 和 B 在一个部署单元内,C 单独部署,这是因为 C 非常重要,或并发量比较大,或需求变更比较频繁,这时候 C 独立部署有几个好处:
- C 独立部署资源:资源更合理的倾斜,独立扩容缩容。
- 弹力服务:重试、熔断、降级等,已达到故障隔离。
- 技术栈独立:C 可以使用其他语言编写,更合适个性化团队技术栈。
- 团队独立:可以由不同团队负责。
架构是可以演进的,所以拆分需要考虑架构的阶段,早期更注重业务逻辑边界,后期需要考虑更多方面,比如数据量、复杂性等,但即使有这个方针,也常会见仁见智,没有人能一下子将边界定义正确,其实这里根本就没有明确的对错。
即使边界定义的不太合适,通过聚合根可以保障我们能够演进出更合适的上下文,在上下文内部通过实体和值对象来对领域概念进行建模,一组实体和值对象归属于一个聚合根。
按照 DDD 的约束要求:
- 第一,聚合根来保证内部实体规则的正确性和数据一致性;
- 第二,外部对象只能通过 id 来引用聚合根,不能引用聚合根内部的实体;
- 第三,聚合根之间不能共享一个数据库事务,他们之间的数据一致性需要通过最终一致性来保证。
有了聚合根,再基于这些约束,未来可以根据需要,把聚合根升级为上下文,甚至拆分成微服务,都是比较容易的。
其实DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。而微服务追求业务层面的复用,设计出来的系统架构和业务一致;在技术架构上则系统模块之间充分解耦,可以自由地选择合适的技术架构,去中心化地治理技术和数据。
可以参见下图来更好地理解双方之间的协作关系:
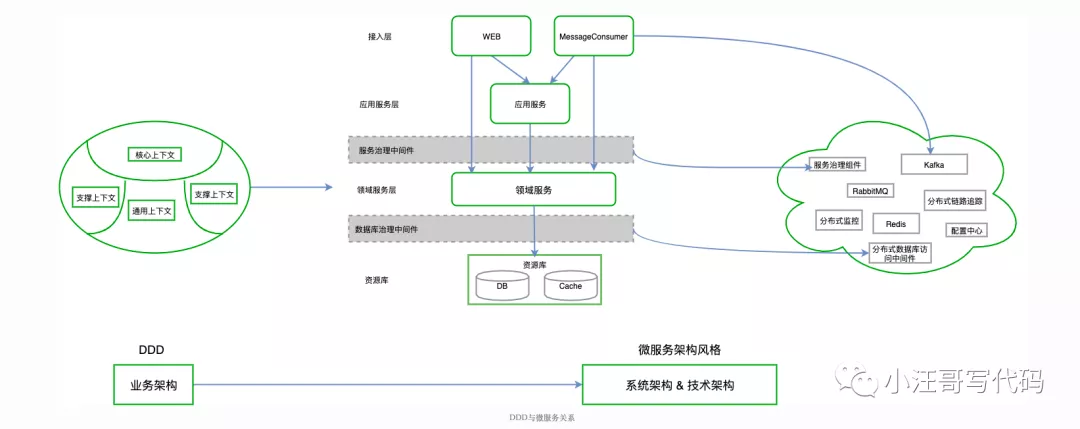
DDD 的相关术语与基本概念
我们来认识一下 DDD 的一些概念吧,每个概念找了一个 Spring 模式开发的映射概念,方便理解,但要仅仅作为理解用,不要过于依赖。另外,这里可能需要结合后面的代码反复结合理解,才能融汇贯通到实际工作中。
领域
映射概念:切分的服务。
领域就是范围。范围的重点是边界。领域的核心思想是将问题逐级细分来减低业务和系统的复杂度,这也是 DDD 讨论的核心。
子域
映射概念:子服务。
领域可以进一步划分成子领域,即子域。这是处理高度复杂领域的设计思想,它试图分离技术实现的复杂性。这个拆分的里面在很多架构里都有,比如 C4。
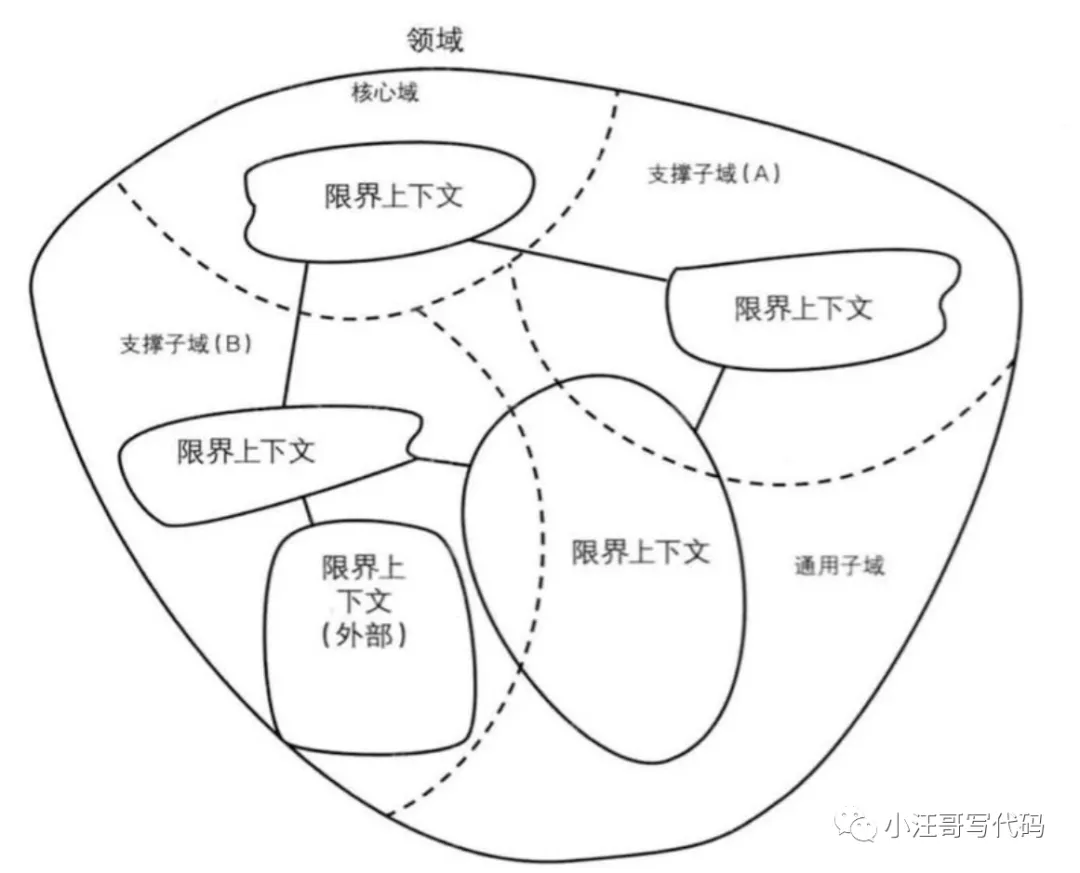
核心域
映射概念:核心服务。
在领域划分过程中,会不断划分子域,子域按重要程度会被划分成三类:核心域、通用域、支撑域。
通用域
映射概念:中间件服务或第三方服务。
支撑域
映射概念:企业公共服务。
统一语言
映射概念:统一概念。
定义上下文的含义。它的价值是可以解决交流障碍,不管你是 RD、PM、QA 等什么角色,让每个团队使用统一的语言(概念)来交流,甚至可读性更好的代码。
通用语言包含属于和用例场景,并且能直接反应在代码中。
可以在事件风暴(开会)中来统一语言,甚至是中英文的映射、业务与代码模型的映射等。可以使用一个表格来记录。
限界上下文
映射概念:服务职责划分的边界。
定义上下文的边界。领域模型存在边界之内。对于同一个概念,不同上下文会有不同的理解,比如商品,在销售阶段叫商品,在运输阶段就叫货品。
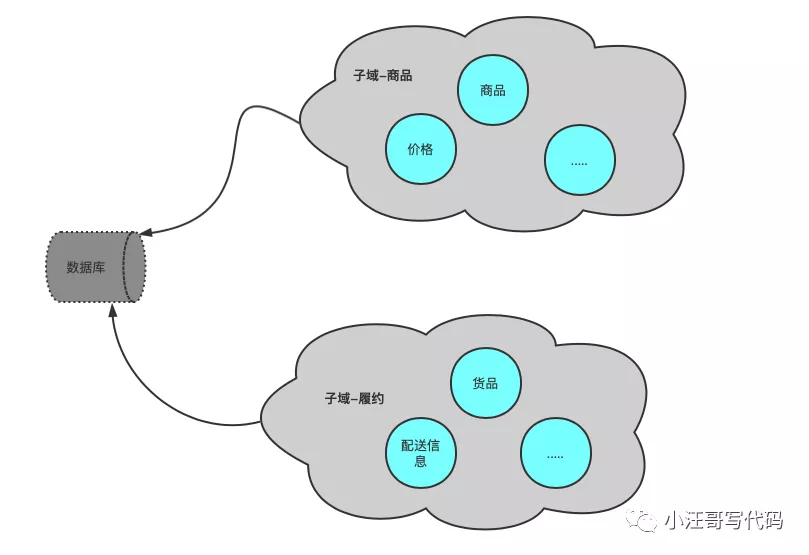
理论上,限界上下文的边界就是微服务的边界,因此,理解限界上下文在设计中非常重要。
聚合
映射概念:包。
聚合概念类似于你理解的包的概念,每个包里包含一类实体或者行为,它有助于分散系统复杂性,也是一种高层次的抽象,可以简化对领域模型的理解。
拆分的实体不能都放在一个服务里,这就涉及到了拆分,那么有拆分就有聚合。聚合是为了保证领域内对象之间的一致性问题。
在定义聚合的时候,应该遵守不变形约束法则:
聚合边界内必须具有哪些信息,如果没有这些信息就不能称为一个有效的聚合;
聚合内的某些对象的状态必须满足某个业务规则:
一个聚合只有一个聚合根,聚合根是可以独立存在的,聚合中其他实体或值对象依赖与聚合根。
只有聚合根才能被外部访问到,聚合根维护聚合的内部一致性。
聚合根
映射概念:包。
一个上下文内可能包含多个聚合,每个聚合都有一个根实体,叫做聚合根,一个聚合只有一个聚合根。
实体
映射概念:Domain 或 entity。
《领域驱动设计模式、原理与实践》一书中讲到,实体是具有身份和连贯性的领域概念,可以看出,实体其实也是一种特殊的领域,这里我们需要注意两点:唯一标示(身份)、连续性。两者缺一不可。
你可以想象,文章可以是实体,作者也可以是,因为它们有 id 作为唯一标示。
值对象
映射概念:Domain 或 entity。
为了更好地展示领域模型之间的关系,制定的一个对象,本质上也是一种实体,但相对实体而言,它没有状态和身份标识,它存在的目的就是为了表示一个值,通常使用值对象来传达数量的形式来表示。
比如 money,让它具有 id 显然是不合理的,你也不可能通过 id 查询一个 money。
定义值对象要依照具体场景的区分来看,你甚至可以把 Article 中的 Author 当成一个值对象,但一定要清楚,Author 独立存在的时候是实体,或者要拿 Author 做复杂的业务逻辑,那么 Author 也会升级为聚合根。
四种领域模型
失血模型、贫血模型、充血模型、胀血模型
四种模型示例
- 失血模型
Domain Object 只有属性的 getter/setter 方法的纯数据类,所有的业务逻辑完全由 business object 来完成。
- public class Article implements Serializable {
- private Integer id;
- private String title;
- private Integer classId;
- private Integer authorId;
- private String authorName;
- private String content;
- private Date pubDate;
- //getter/setter/toString
- }
- public interface ArticleDao {
- public Article getArticleById(Integer id);
- public Article findAll();
- public void updateArticle(Article article);
- }
- 贫血模型
简单来说,就是 Domain Object 包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到 Service 层。
- public class Article implements Serializable {
- private Integer id;
- private String title;
- private Integer classId;
- private Integer authorId;
- private String authorName;
- private String content;
- private Date pubDate;
- //getter/setter/toString
- //判断是否是热门分类(假设等于57或102的类别的文章就是热门分类的文章)
- public boolean isHotClass(Article article){
- return Stream.of(57,102)
- .anyMatch(classId -> classId.equals(article.getClassId()));
- }
- //更新分类,但未持久化,这里不能依赖Dao去操作实体化
- public Article changeClass(Article article, ArticleClass ac){
- return article.setClassId(ac.getId());
- }
- }
- @Repository("articleDao")
- public class ArticleDaoImpl implements ArticleDao{
- @Resource
- private ArticleDao articleDao;
- public void changeClass(Article article, ArticleClass ac){
- article.changeClass(article, ac);
- articleDao.update(article)
- }
- }
注意这个模式不在 Domain 层里依赖 DAO。持久化的工作还需要在 DAO 或者 Service 中进行。
这样做的优缺点
优点:各层单向依赖,结构清晰。
缺点:
Domain Object 的部分比较紧密依赖的持久化 Domain Logic 被分离到 Service 层,显得不够 OO
Service 层过于厚重
- 充血模型
充血模型和第二种模型差不多,区别在于业务逻辑划分,将绝大多数业务逻辑放到 Domain 中,Service 是很薄的一层,封装少量业务逻辑,并且不和 DAO 打交道:
Service (事务封装) —> Domain Object <—> DAO
- public class Article implements Serializable {
- @Resource
- private static ArticleDao articleDao;
- private Integer id;
- private String title;
- private Integer classId;
- private Integer authorId;
- private String authorName;
- private String content;
- private Date pubDate;
- //getter/setter/toString
- //使用articleDao进行持久化交互
- public List<Article> findAll(){
- return articleDao.findAll();
- }
- //判断是否是热门分类(假设等于57或102的类别的文章就是热门分类的文章)
- public boolean isHotClass(Article article){
- return Stream.of(57,102)
- .anyMatch(classId -> classId.equals(article.getClassId()));
- }
- //更新分类,但未持久化,这里不能依赖Dao去操作实体化
- public Article changeClass(Article article, ArticleClass ac){
- return article.setClassId(ac.getId());
- }
- }
所有业务逻辑都在 Domain 中,事务管理也在 Item 中实现。这样做的优缺点如下。
优点:
更加符合 OO 的原则;
Service 层很薄,只充当 Facade 的角色,不和 DAO 打交道。
缺点:
DAO 和 Domain Object 形成了双向依赖,复杂的双向依赖会导致很多潜在的问题。
如何划分 Service 层逻辑和 Domain 层逻辑是非常含混的,在实际项目中,由于设计和开发人员的水平差异,可能 导致整个结构的混乱无序。
- 胀血模型
基于充血模型的第三个缺点,有同学提出,干脆取消 Service 层,只剩下 Domain Object 和 DAO 两层,在 Domain Object 的 Domain Logic 上面封装事务。
Domain Object (事务封装,业务逻辑) <—> DAO
似乎 Ruby on rails 就是这种模型,它甚至把 Domain Object 和 DAO 都合并了。
这样做的优缺点:
简化了分层
也算符合 OO
该模型缺点:
很多不是 Domain Logic 的 Service 逻辑也被强行放入 Domain Object ,引起了 Domain Object 模型的不稳定;
Domain Object 暴露给 Web 层过多的信息,可能引起意想不到的副作用。
DDD落地的一些思考
最近把一个新项目使用了DDD思想进行落地,项目代码结构如下:
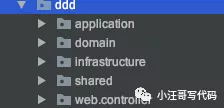
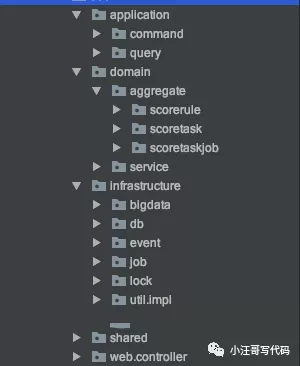
整体感觉还是不错的,不用文档,基本也能看清楚业务的脉络。使用Domain Primitive(DP)和CQRS 设计接口,接口语义更加清楚,接口参数的清晰度,业务代码逻辑的清晰度显著提高,而且方便后期读写分离,使用Event Sourcing模式,领域对象的状态完全是由事件驱动的,可以最大限度的实现系统的松耦合。
唯一的缺点就是代码量的膨胀,但是这也是不可避免的。对于大团队来讲利大于弊,减少沟通成本,小团队按需尝试。