Atwood定律说,凡是可以用Javascript实现的应用,最终都会用Javascript实现掉。作为最热门的机器学习领域,服务端是Python的主场,但是到了手机端呢?Android和iOS里默认都没有Python。但是有浏览器的地方就有js,现在还有个新场景 - 小程序。
除此之外,为了可以在不联网情况下进行训练的,也有支持本地框架比如React Native的。
可以说,只要有前端的地方,就有机器学习的框架在。
js唯一的问题在于,变化太快,每年都有很多新库出现,但是也有不少老的库宣布不维护了。但是,万变不离其宗,工具本身虽然经常有变化,但是它们的类型是非常稳定的。
选择机器学习工具的方法论
我们要写机器学习算法,需要什么样的工具呢?
机器学习工具可以分为以下四个层次:
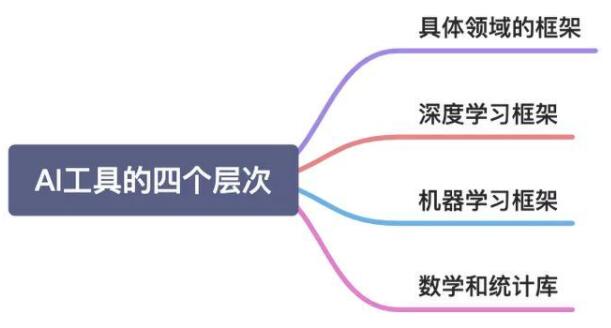
层次一:直接服务于具体领域的框架
首先我们需要直接服务于具体领域的框架,比如处理CV的,NLP的,推荐算法之类的。
比如nlp.js,上一个版本发布在2020年10月。nlp.js的代码写起来是这样的:
- const { NlpManager } = require('node-nlp');const manager = new NlpManager({ languages: ['en'], forceNER: true });// Adds the utterances and intents for the NLPmanager.addDocument('en', 'goodbye for now', 'greetings.bye');manager.addDocument('en', 'bye bye take care', 'greetings.bye');manager.addDocument('en', 'okay see you later', 'greetings.bye');manager.addDocument('en', 'bye for now', 'greetings.bye');manager.addDocument('en', 'i must go', 'greetings.bye');manager.addDocument('en', 'hello', 'greetings.hello');manager.addDocument('en', 'hi', 'greetings.hello');manager.addDocument('en', 'howdy', 'greetings.hello');// Train also the NLGmanager.addAnswer('en', 'greetings.bye', 'Till next time');manager.addAnswer('en', 'greetings.bye', 'see you soon!');manager.addAnswer('en', 'greetings.hello', 'Hey there!');manager.addAnswer('en', 'greetings.hello', 'Greetings!');// Train and save the model.(async() => { await manager.train(); manager.save(); const response = await manager.process('en', 'I should go now'); console.log(response);})();
运行起来很简单,装个库就好:
npm install node-nlp
训练的速度也很快:
- Epoch 1 loss 0.4629286907733636 time 1msEpoch 2 loss 0.2818764774939686 time 0msEpoch 3 loss 0.16872372018062168 time 0msEpoch 4 loss 0.11241683507408215 time 0ms...Epoch 31 loss 0.00004645272306535786 time 0ms
输出的结果类似这样:
- { locale: 'en', utterance: 'I should go now', settings: undefined, languageGuessed: false, localeIso2: 'en', language: 'English', nluAnswer: { classifications: [ [Object] ], entities: undefined, explanation: undefined }, classifications: [ { intent: 'greetings.bye', score: 1 } ], intent: 'greetings.bye', score: 1, domain: 'default', sourceEntities: [ { start: 12, end: 14, resolution: [Object], text: 'now', typeName: 'datetimeV2.datetime' } ], entities: [ { start: 12, end: 14, len: 3, accuracy: 0.95, sourceText: 'now', utteranceText: 'now', entity: 'datetime', resolution: [Object] } ], answers: [ { answer: 'Till next time', opts: undefined }, { answer: 'see you soon!', opts: undefined } ], answer: 'see you soon!', actions: [], sentiment: { score: 0.5, numWords: 4, numHits: 1, average: 0.125, type: 'senticon', locale: 'en', vote: 'positive' }}
层次二:深度学习框架
第二是我们的核心内容,深度学习框架。
说到Javascript深度学习,占统治地位的仍然是Tensorflow.js,我们来看个经典的强化学习的例子:
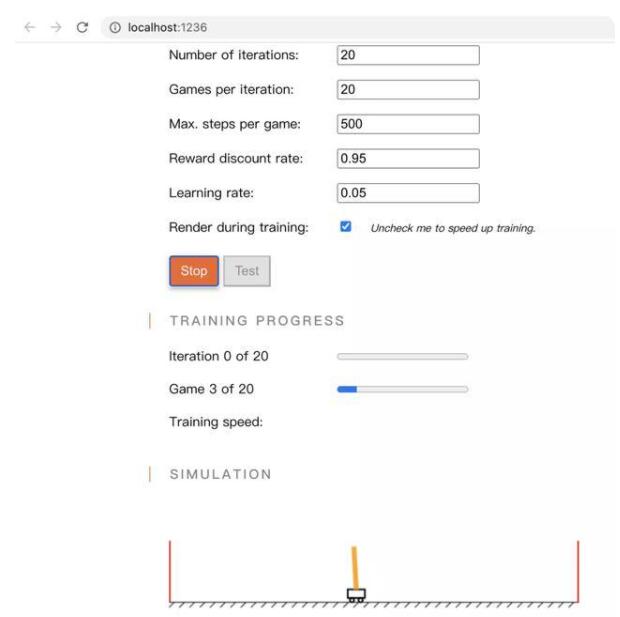
使用浏览器的local storage和indexdb作为存储,边训练边展示训练效果的过程,很有前端的风范。
我们再看另一个大厂微软的例子,支持webGL和wasm,基于浏览器不容易:
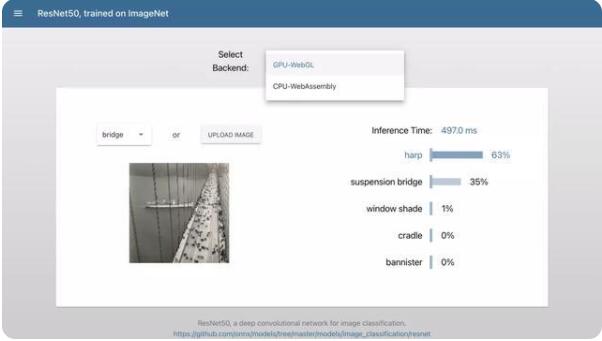
另外需要强调的是,用于前端的框架并不是简单的把native或者python框架移植过来的,比如说它要处理兼容性的问题:

很多同学都对Tensorflow有一定了解,我们就手写一个网页,然后在其中调tf的API就好:
- <!DOCTYPE html><html> <head> <meta encoding="UTF-8"/> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.0.0/dist/tf.min.js"></script> </head> <body> <div id="tf-display"></div> <script> let a = tf.tensor1d([1.0]); let d1 = document.getElementById("tf-display"); d1.innerText = a;</script> </body></html>
层次三:机器学习框架
第三是机器学习的框架。光了解深度学习还不够,传统的机器学习在更贴近业务的时候,可能效果更好,还节省算力资源。比如可以使用mljs库,地址在:https://github.com/mljs/ml
比如我们想做个k-means聚类,可以使用mljs框架的ml-kmeans库:
- const kmeans = require('ml-kmeans');let data = [[1, 1, 1], [1, 2, 1], [-1, -1, -1], [-1, -1, -1.5]];let centers = [[1, 2, 1], [-1, -1, -1]];let ans = kmeans(data, 2, { initialization: centers });console.log(ans);
装个包就可以玩了:
npm i ml-kmeans
运行结果如下:
- KMeansResult { clusters: [ 0, 0, 1, 1 ], centroids: [ { centroid: [Array], error: 0.25, size: 2 }, { centroid: [Array], error: 0.0625, size: 2 } ], converged: true, iterations: 2, [Symbol(distance)]: [Function: squaredEuclidean]}
我们也可以直接在网页中使用,比如我们写个K近邻的例子:
- <!DOCTYPE html><html> <head> <meta encoding="UTF-8" /> <script src="https://www.lactame.com/lib/ml/4.0.0/ml.min.js"></script> </head> <body> <div id="ml-display"></div> <script> const train_dataset = [ [0, 0, 0], [0, 1, 1], [1, 1, 0], [2, 2, 2], [1, 2, 2], [2, 1, 2], ]; const train_labels = [0, 0, 0, 1, 1, 1]; let knn = new ML.KNN(train_dataset, train_labels, { k: 2 }); // consider 2 nearest neighbors const test_dataset = [ [0.9, 0.9, 0.9], [1.1, 1.1, 1.1], [1.1, 1.1, 1.2], [1.2, 1.2, 1.2], ]; let ans = knn.predict(test_dataset); let d1 = document.getElementById("ml-display"); d1.innerText = ans;</script> </body></html>
最后我们再来个决策树的例子
- const irisDataset = require('ml-dataset-iris');const DecisionTreeClassifier = require('ml-cart');const trainingSet = irisDataset.getNumbers();const predictions = irisDataset .getClasses() .map((elem) => irisDataset.getDistinctClasses().indexOf(elem));const options = { gainFunction: 'gini', maxDepth: 10, minNumSamples: 3,};const classifier = new DecisionTreeClassifier.DecisionTreeClassifier(options);classifier.train(trainingSet, predictions);const result = classifier.predict(trainingSet);console.log(result);
输出结果如下:
- [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... 50 more items]
层次四:数学和统计库
第四个层次是数学和统计库。做统计和数学计算,很多时候才是理解业务的最好手段。这个时候我们也不能空手上,也需要工具。
这方面的代表库有stdlib: https://stdlib.io/虽然它名字和实际都是标准库,但是为了数学和统计提供了很丰富的内容,比如150多个数学函数和35种统计分布。
我们先安装一下做后面的实验:
npm install @stdlib/stdlib
比如各种数学函数:
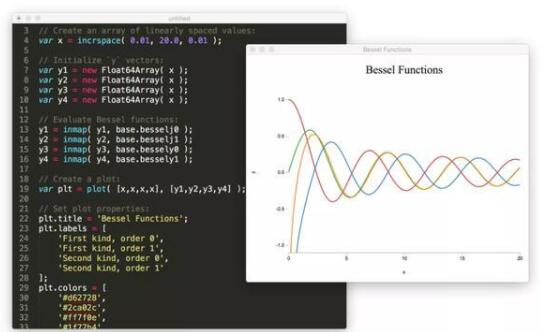
再比如各种随机分布:

我们以正态分布为例,看看stdlib是如何描述分布的:
- const Normal = require( '@stdlib/stats/base/dists/normal' ).Normal;let dist1 = new Normal( 0, 1 );console.log(dist1);let m1 = dist1.mean;console.log(m1);let v1 = dist1.variance;console.log(v1);
构造Normal时的两个参数是均值和方差。
输出如下:
Normal { mu: [Getter/Setter], sigma: [Getter/Setter] }01
这个无良的标准库竟然还支持50多种数据集,看个小例子,美国州首府的数据集:
- const capitals = require( '@stdlib/datasets/us-states-capitals' );const data_c = capitals();console.log(data_c);
输出结果如下:
- [ 'Montgomery', 'Juneau', 'Phoenix', 'Little Rock', 'Sacramento', 'Denver', 'Hartford', 'Dover', 'Tallahassee', 'Atlanta', 'Honolulu', 'Boise', 'Springfield', 'Indianapolis', 'Des Moines', 'Topeka', 'Frankfort', 'Baton Rouge', 'Augusta', 'Annapolis', 'Boston', 'Lansing', 'Saint Paul', 'Jackson', 'Jefferson City', 'Helena', 'Lincoln', 'Carson City', 'Concord', 'Trenton', 'Santa Fe', 'Albany', 'Raleigh', 'Bismarck', 'Columbus', 'Oklahoma City', 'Salem', 'Harrisburg', 'Providence', 'Columbia', 'Pierre', 'Nashville', 'Austin', 'Salt Lake City', 'Montpelier', 'Richmond', 'Olympia', 'Charleston', 'Madison', 'Cheyenne']
总结
综上,如果要做从0到1的业务,尽可能用第一层次的工具,这样最有助于快速落地。但是如果是要做增量,尤其是困难的增长,第三第四层次是首选,因为更有助于深刻理解数据。