Google 近日发布了一个端到端的神经音频编解码器 —— SoundStream。最重要的是,Google 表示这是世界上第一个由神经网络驱动并支持语音、音乐和环境声音等不同声音类型的音频编解码器,可以在智能手机的处理器上实时处理上述各种音频。
音频编解码器是压缩音频文件的基本工具,以使其体积更小,并在传输过程中尽可能节省时间。因此,音频编解码器对于流媒体、在线语音和视频通话这类有音频传输需求的服务而言至关重要。
虽然音频编解码器能够压缩音频体积,加速音频传输过程,但压缩后的音频也会损失音频质量和细节,产生可以让用户察觉到的差异。而这就是 SoundStream 能够弥补的地方。
今年 2 月的时候,Google 发布了一个用于低比特率语音的神经音频编解码器 Lyra,并在今年 4 月正式开源。SoundStream 是 Lyra 的一个扩展版本。SoundStream 不仅集成了 Lyra 在低比特率「语音」方面的能力,还具有对更多声音类型的编码支持,包括清晰的语音、嘈杂的语音、带有回声的语音、音乐和环境声音等。
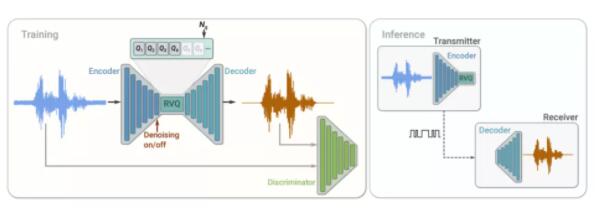
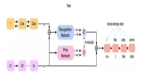
SoundStream 是围绕一个由编码器、解码器和量化器组成的神经网络系统而建立的。编码器将音频转换为编码信号,之后使用量化器进行压缩,并使用解码器转换回音频。因此,在经过训练神经网络模型后,编码器和解码器可以在不同的客户端工作,有助于在各种环境下以不损失质量的前提传输音频。
Google 已经在网站上发布了不同音频压缩样本与原始音频样本的对比。通过对比测试,经过 SoundStream 处理过的 3 kbps 的音频要优于 Opus 音频编解码器处理过的 12 kbps 音频,效果与 ECS 编解码器处理过的 9 kbps 十分接近。
目前 Google 自己的在线会议平台 Google Meet 和视频平台 YouTube 仍在使用 Opus 音频编解码器。随着 SoundStream 技术的不断进步,可能很快就能看到 Google 将在自己的服务中使用自己的技术。
Google 表示,SoundStream 是将机器学习技术应用在音频编解码器中重要的一步,比目前最先进的编解码器 Opus 和 EVS 效果更好。SoundStream 将被整合进 Lyra,并随着 Lyra 下一版本的发布一同推出。开发人员可以利用现有的 Lyra API 和工具,来提供更好的音质。