大家好,我是Python进阶者。
前言
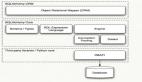
在我们做web开发的时候,经常需要用到与数据库交互,因为我们的数据通常都是保存在数据库中的,如果有人需要访问,就必须与数据库访问,所以今天我们介绍一个Flask中与数据库交互的插件---Flask-Sqlalchemy。
一、安装并导入
- pip install flask-sqlalchemy
- from flask_sqlalchemy import SQLAlchemy
- import os
- import pymysql as p
- from flask import Flask
二、基本用法
今天我们要了解的是Mysql数据库,所以这里重点介绍连接Mysql数据库的方法。
1.连接数据库
1).写在配置文件中然后读取
首先创建一个配置文件"config.py",内容为:
- db_type='mysql'
- db_conn='pymysql'
- host='127.0.0.1'
- username='root'
- password='123456'
- port='3306'
- db_name='people'
- SQLALCHEMY_DATABASE_URI='{}+{}://{}:{}@{}:{}/{}?charset=utf8'.format(db_type,db_conn,username,password,host,port,db_name)
- SQLALCHEMY_COMMIT_ON_TEARDOWN=False
- SQLALCHEMY_TRACK_MODIFICATIONS=True
然后在应用中导入配置文件:
- from flask_sqlalchemy import SQLAlchemy
- from flask import Flask
- import config
- app=Flask(__name__)
- app.config.from_object(config) # 连接数据库配置文件
- db=SQLAlchemy(app)
- db.create_all() # 创建所有的数据库
2).直接写在应用中读取
- app=Flask(__name__)
- p.install_as_MySQLdb() # mysql连接器,因为不支持py3版本,所以必须加上这行
- app.config['SECRET_KEY']=os.urandom(50)
- app.config['SQLALCHEMY_DATABASE_URI']='mysql+pymysql://root:123456@127.0.0.1:3306/people'
- app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN']=True # 每次请求结束后都会自动提交数据库中的变动
- app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True # 动态追踪修改设置,如未设置只会提示警告
- db = SQLAlchemy(app)
还有许多其它的配置参数,比如:
- SQLALCHEMY_NATIVE_UNICODE # 可以用于显式禁用原生 unicode 支持
- SQLALCHEMY_POOL_SIZE # 数据库连接池的大小,默认是引擎默认值(5)
- SQLALCHEMY_POOL_TIMEOUT # 设定连接池的连接超时时间,默认是 10
- SQLALCHEMY_POOL_RECYCLE # 多少秒后自动回收连接,mysql默认为2小时
- SQLALCHEMY_RECORD_QUERIES # 可以用于显式地禁用或启用查询记录
- SQLALCHEMY_ECHO # 为Ture时用于调试,显示错误信息
- SQLALCHEMY_BINDS # 一个映射 binds 到连接 URI 的字典
3).使用独特的创建引擎
- from sqlalchemy import create_engine
- # echo参数为True时,会显示每条执行的SQL语句,为False时关闭
- engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/people',echo=True)
- engine.connect()
这样我们就算与People数据库建立连接了,接下来我们来建立一张表。
4).创建连接多个数据库
- app.config['SQLALCHEMY_BINDS']={
- 'users': "mysql+pymysql://root:123456@127.0.0.1:3306/user",
- 'admin': 'sqlite://C:/Users/Administrator/Desktop/admin',
- 'buy': 'postgresql://root:123321@127.0.0.1/buy'
- }
然后引用表:
- db.create_all(bind=['users'])
- db.create_all(bind='admin')
指定Users数据库中的表:
- __bind_key__ = 'users'
- bind key 内部存储在表的 info 字典中 即:info={'bind_key': 'users'}
2.建立数据表并插入值
1).继承"db.Model"类
- from flask_sqlalchemy import SQLAlchemy
- from flask import Flask
- import config
- app=Flask(__name__)
- app.config.from_object(config) # 添加配置文件
- db=SQLAlchemy(app)
- class User(db.Model):
- __tablename__='users'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True) # 整数类型的自增主键
- username=db.Column(db.String(100),nullable=False) # 字符类型不为空
- password=db.Column(db.String(100),nullable=False) # 字符类型不为空
- def __init__(self,username,password):
- self.username=username
- self.password=password
- def __repr__(self):
- # 打印当前类名和它的实例化后的值
- return ' %s is %r' %(self.__class__.__name__,self.username)
- # 请求钩子,第一次请求之前执行
- @app.before_first_request
- def create_table():
- db.drop_all() # 删除所有表
- db.create_all() # 创建新的表
- @app.route('/')
- def create():
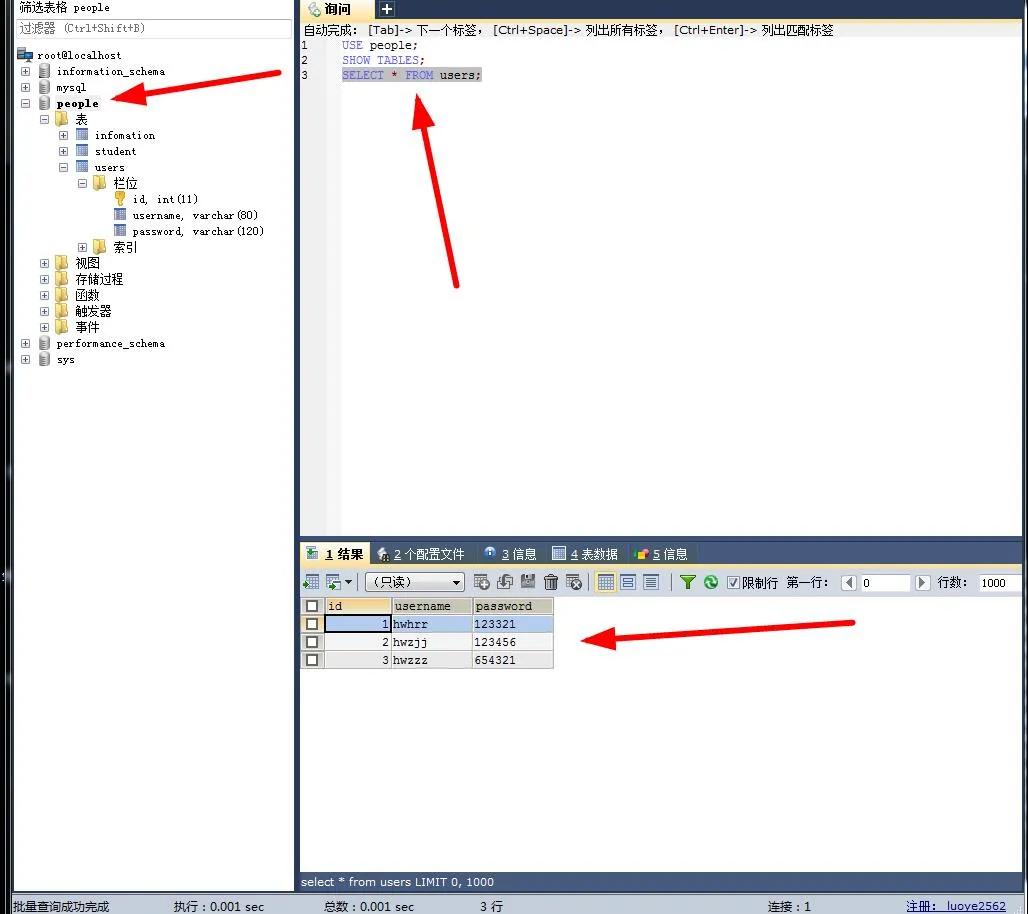
- use1= User('hwhrr', '123321')
- use2= User('hwzjj', '123456')
- use3= User('hwzzz', '654321')
- db.session.add_all([use1,use2,use3]) # 添加所有的用户,添加一个用户去掉_all后面加一个元祖即可
- db.session.commit() # 提交数据
- return use1.__repr__() # 返回用户1的值
- if __name__ == '__main__':
- app.run(debug=True)
- Column 参数列表
- name 列名
- type_ 类型
- *args 列表参数
- Constraint(约束), ForeignKey(外键), ColumnDefault(默认), Sequenceobjects(序列)定义
- key 列名的别名
- primary_key 如果为True,则是主键
- nullable 如果是True,则可以为null
- default 设置默认值,默认是None
- index 是否是索引,默认是True
- unique 是否唯一键,默认是False
- onupdate 指定一个更新时候的值
- autoincrement 设置为整型自动增长
- quote 如果列明是关键字,则强制转义,默认False
2).利用原始引擎来创建会话(稍微复杂点)
- from flask import Flask
- from sqlalchemy import create_engine
- from sqlalchemy.orm import sessionmaker
- from sqlalchemy.ext.declarative import declarative_base
- from sqlalchemy import Column, Integer, String
- app=Flask(__name__)
- Base = declarative_base()
- # 创建连接数据库的引擎并且打开回显
- engine = create_engine("mysql+pymysql://root:123456@localhost/people",echo=True)
- Session = sessionmaker(bind=engine) # 创建会话标记
- class User(Base):
- __tablename__ = 'article'
- id = Column(Integer, primary_key=True,autoincrement=True)
- username = Column(String(100),nullable=False)
- password = Column(String(100),nullable=False)
- def __init__(self, username,password):
- self.username = username
- self.password=password
- def __repr__(self):
- return ' %s is %r' %(self.__class__.__name__,self.username)
- @app.before_first_request
- def create_table():
- Base.metadata.drop_all(engine) # 删除所有数据库
- Base.metadata.create_all(engine) # 创建所有数据库
- @app.route('/')
- def index():
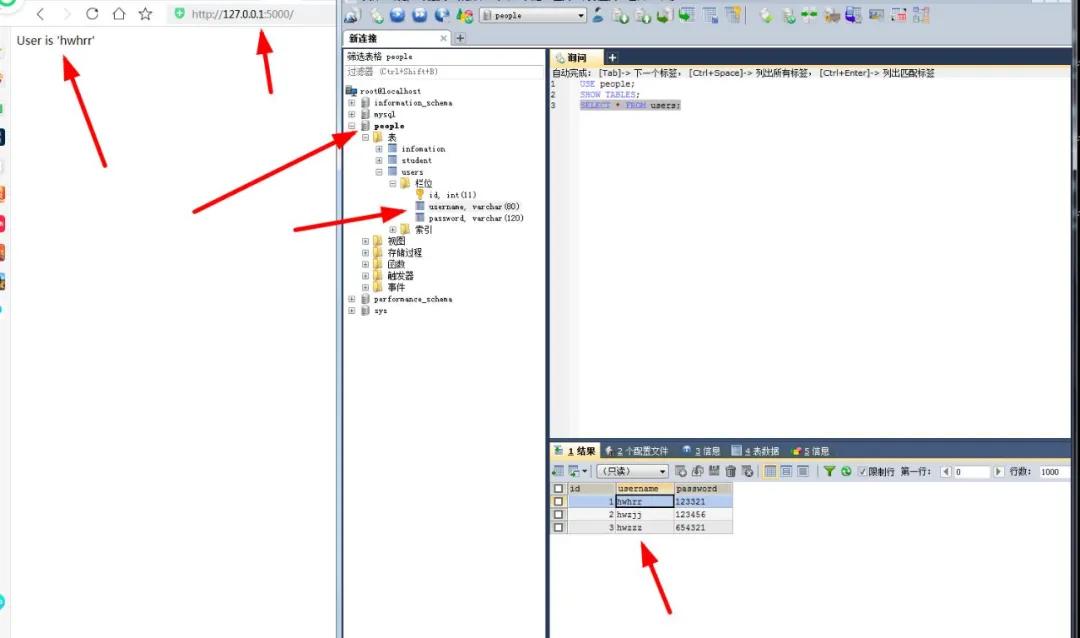
- user= User("hwhrr","123321")
- session = Session() # 创建会话
- session.add(user) # 添加内容
- session.commit() # 提交
- return user.__repr__()
- if __name__ == '__main__':
- app.run(debug=True)
3.数据库之间的关系
1). 一对一
只需让两张表都在同等的位置上,属于双向关系。
- class father(db.Model):
- __tablename__='Father'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- #主要是要在一个表上设置uselist 然后设置back_populates的值为其它表的映射返回值
- son_fa=db.relationship('son',uselist=False, back_populates='fa_son')
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
- class son(db.Model):
- __tablename__='Son'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- # 这里无需设置uselist
- fa_son=db.relationship('father',back_populates='son_fa')
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
2).一对多
我们需要建立一个主表和一个子表,分别命名为“father”和‘son’,然后需要建立外键和反射来互相引用建立一种关系,我们来看看:
- class father(db.Model):
- __tablename__='Father'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- # 表示另一端是son这个模型,backref可替代Father.id访问father模型
- son_fa=db.relationship('son',backref='fa',lazy='dynamic')
- # lazy表示加载方式:
- # dynamic:动态加载,只有用到了才加载 只可以用在一对多和多对多关系中
- # subquery:全部加载
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
- class son(db.Model):
- __tablename__='Son'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- f_id=db.Column(db.Integer,db.ForeignKey('Father.id')) # 建立外键关联,指明表名和字段
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self._class__.__name__,self.name)
- @app.route('/')
- def create():
- use1= father('hw', 45)
- use2= son('hyy', 20)
- db.session.add_all([use1,use2])
- db.session.commit()
- return use1.__repr__()+'\n'+use2.__repr__()
3).多对一
就是将反射应用在子表上,与父表同时进行关联。
- class father(db.Model):
- __tablename__='Father'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- # 表示另一端是son这个模型
- son_fa=db.relationship('son', back_populates="fath")
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
- class son(db.Model):
- __tablename__='Son'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- f_id=db.Column(db.Integer,db.ForeignKey('Father.id')) # 建立外键关联
- # 表示另一端是father这个模型
- fa_son=db.relationship('father',back_populates="so")
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
4).多对多
设置一个关联表来对两个表同时进行管理。
- # 设置关联表
- gl=db.Table('glb',
- db.Column('id',db.Integer,primary_key=True,autoincrement=True),
- db.Column('son_id',db.Integer,db.ForeignKey('Son.id')),
- db.Column('father_id',db.Integer,db.ForeignKey('Father.id'))
- )
- # 父表
- class father(db.Model):
- __tablename__='Father'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- # 设置关联表 动态加载
- son_fa=db.relationship('son',secondary=gl,backref="fas",lazy="dynamic")
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
- # 子表
- class son(db.Model):
- __tablename__='Son'
- id=db.Column(db.Integer, primary_key=True,autoincrement=True)
- name= db.Column(db.String(100),nullable=False)
- age= db.Column(db.Integer,nullable=False)
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __repr__(self):
- return '%s is %r'%(self.__class__.__name__,self.name)
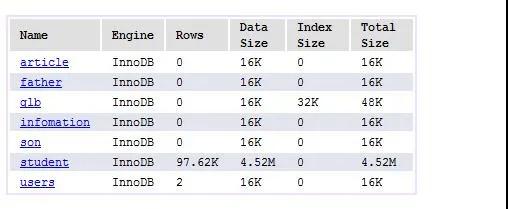
可以看出我们已经创建出了一张关联表,名字就是我们设置的“glb”。
4.查看数据
1).查看全部数据(all)
- father.query.all()
2).精准查询(filter_by)
- father.query.filter_by(name='hw').all() # 查找所有名字为hw的记录
3).模糊查询(filter)
- father.query.filter(father.name.startswith('h').all() # 查找所有名字首字母为h的记录
4).主键查询(get)
- father.query.get(1) # 查看id为1的记录
5).取反操作(not_)
- from sqlalchemy import not_
- father.query.filter(not_(father.name=='hw')).all() # 查找所有除了名字不是hw的记录
6).与操作(and_)
- from sqlalchemy import and_
- # 查找名字末尾是h并且年龄等于50的记录
- father.query.filter(and_(father.name.endswith('h'),father.age==50)).all()
7).或操作(or_)
- from sqlalchemy import or_
- # 查找名字末尾是h或者年龄等于50的记录
- father.query.filter(or_(father.name.endswith('h'),father.age==50)).all()
8).一对多正向查询
- son.query.filter_by(f_id=2).all()
9).一对多反向查询
- son.query.filter_by(fa=use1).all()
10).查询第一个出现的数据
- son.query.filter(son.age==10).first()
- son.query.filter(son.age==10)[0]
11).查询对象并返回指定数量的结果
- son.query.filter(son.age==10).limit(10).all() # 返回十个查找到的对象
12).查询时指定偏移量
- son.query.filter(son.age==10).offset(2).all() # 返回偏移了2的对象
13).查找对象并排序
- son.query.filter(son.age==10).order_by(son.create_time.desc()).all() # 返回按降序排序的记录
14).查找对象返回分组结果
- son.query.filter(son.age==10).group_by(son.name).all() # 返回age为10的名字对象分组
15).返回查询结果的数量
- son.query.filter(son.age==10).count() # son的年龄为10的数量
16).返回切片结果
- son.query(son).slice(10,40).all() # son从10到40的记录
- son.query(son)[10:40]
17).分页获取数据
- p=request.args.get('p')
- # 从请求的查询字符串中获取当前页面,返回一个每页显示3条记录的分页对象
- paginate=son.query.paginate(p=int(p),per_page=3)
- paginate 属性:
- pages # 总共生成页面数量
- page # 当前页数
- has_next # 判断是否有下一页
- has_prev # 判断是否有上一页
- next_num # 获取下一页的页码数
- prev_num # 获取上一页的页码数
- items # 获取当前页的记录
- total # 查询返回的记录总数
18).查询仅显示一条记录
- son.query(son).one()
5.更新数据
- ss=son.query.get(1)
- ss.name='fasd' # 更改name的值来达到更新的目的
- db.session.commit()
6.删除数据
- ss=son.query.get(1)
- db.session.delete(ss)
- db.session.commit()
三、总结
Sqlalchemy支持很多表的建立和操作,通过对它的了解,我们可以很方便的操作数据库的数据从而与前端页面交互达到可视化的效果,通过这篇文章的学习,相信你可以独立开发一个小网站了。
本文转载自微信公众号「Python爬虫与数据挖掘」,可以通过以下二维码关注。转载本文请联系Python爬虫与数据挖掘公众号。