由于 MySQL 的整个体系太过于庞大,文章的篇幅有限,不能够完全的覆盖所有的方面。所以我会尽可能的从更加贴进我们日常使用的方式来进行解释。
小白眼中的 MySQL
首先,对于我们来说,MySQL 是个啥?我们从一个最简单的例子来回顾一下。
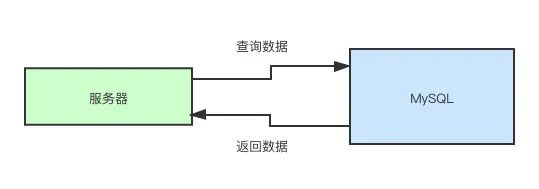
这可能就是最开始大家认知中的 MySQL。那 MySQL 中是怎么处理这个查询语句的呢?换句话说,它是如何感知到这串字符串是一个查询语句的?它是如何感知到该去哪张表中取数据?它是如何感知到该如何取数据?
到目前为止,都不知道。接下来我们一步一补来进行解析。
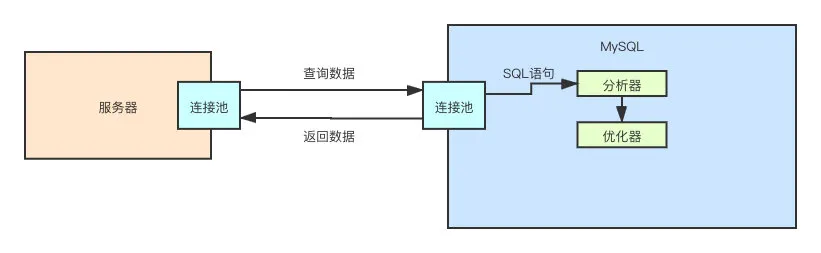
连接池
首先,要去 MySQL 执行命令,肯定是需要连接上 MySQL 服务器的,就像我们通过「用户名」和「密码」登陆网站一样。所以,我们首先要认识的就是连接池。
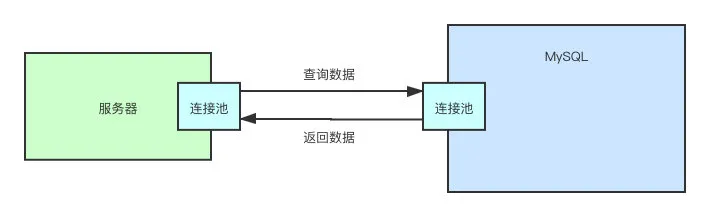
这种池化技术的作用很明显,复用连接,避免频繁的销毁、创建线程所带来的开销。除此之外,在这一层还可以根据你的账号密码对用户的合法性、用户的权限进行校验。
每一个连接都对应一个线程,「服务器」 和 「MySQL」 都一样,服务器的一个线程从服务器的连接池中取出一个连接,发起查询语句。MySQL 服务器的线程从连接池中取出一个线程,继续后续的流程。
那么后面的流程是啥呢?当然是分析 SQL 语句了。
分析器
很明显,MySQL 肯定得知道这个 SQL 是不是个合法的 SQL 语句,以及 SQL 语句到底要干啥?
就好像有个哥们疯狂的敲你家门,门打开了,下一步是干嘛?肯定得问他是谁?来干嘛?
所以,下一步就是要将 SQL 进行解析。解析完成之后,我们就知道当前的 SQL 是否符合语法,它到底要干嘛,是要查询数据?还是要更新数据?还是要删除数据?
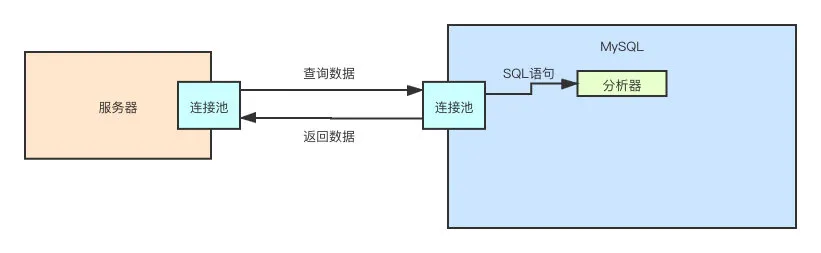
很简单,我们肉眼能能明显看出来一条 SQL 语句是要干嘛。但电脑不是人脑,我们得让电脑也能看懂这条 SQL 语句,才能帮我们去做后面的事。
知道了这个 SQL 语言要干嘛之后,是不是就可以开始执行操作了呢?
并不是
优化器
MySQL 除了要知道这条 SQL 要干嘛,在执行之前,还得决定怎么干,怎么干是最优解。
还是刚刚那个例子,隔壁的哥们敲开了你家的门,说哥们儿,我家里这停水了,想找你施(白)舍(漂) 24 瓶矿泉水。我们暂且不去讨论,他为什么需要 24 瓶矿泉水。
我们要讨论的是,我们要怎么把这 24 瓶矿泉水拿给他。因为你刚刚想起来,矿泉水在之前被你一顿操作全扔柜子了。
你是要每次拿个 4 瓶,跑 6 趟呢?还是找个箱子,把 24 瓶装满再搬出去给他。
这差不多就是优化器要做的事情,优化器会分析你的 SQL,找出最优解。
再举个正经的例子,假设 SELECTnameFROMstudentwhereid= 1 语句执行时,数据库里有 1W 条数据,此时有两种方案:
- 查出所有列的 name 值,然后再遍历对比,找到 id=1 的 name 值
- 直接找到 id=1 的数据,然后再取 name 的值
用屁股想想都知道应该选方案2.
找到了怎么做之后,接下来就需要落实到行动上了。所以,接下来执行器闪亮登场。
执行器
执行器会掉用底层存储引擎的接口,来真正的执行 SQL 语句,在这里的例子就是查询操作。
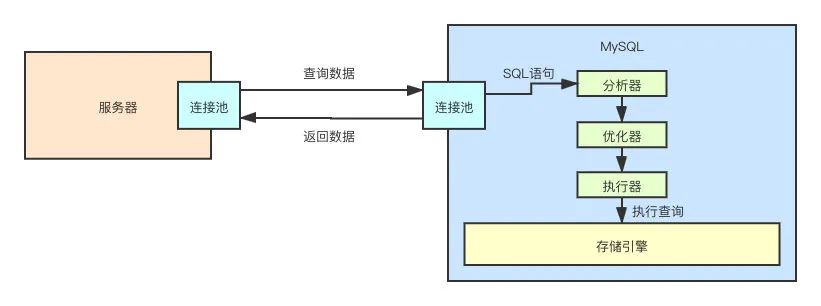
至此,MySQL 这个黑盒子已经被我们一步一步的揭开了面纱。但是在揭开最后一片面纱的时候,我们又发现了新的黑盒子。那就是存储引擎。
我们到目前为止,就只知道它的名字,至于其如何存储数据,如何查询数据,一概不知。
存储引擎
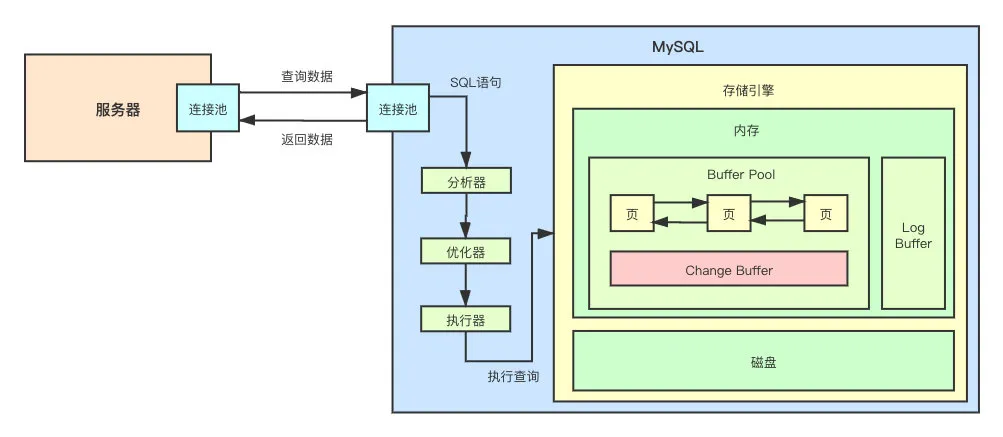
MySQL 的存储引擎有很多的种类,分别适用于不同的场景。大家可以这么理解,存储引擎就是一个执行数据操作的接口(Interface),而底层的具体实现有很多类。
InnoDB、MyISAM、Memory、CSV、Archive、Blackhole、Merge、Federated、Example
用的最广泛的,就是 InnoDB 了。打从 MySQL 5.5 之后,InnoDB 就是 MySQL 默认的存储引擎了。
所以,存储引擎其实并不是什么高大上的东西,跟什么大学拿去交作业的图书馆管理系统区别,就差了亿点而已。
或者,我再举个例子。我们往我们电脑上的文件中写入数据,此时由于 OS 的优化,数据并不会直接写入磁盘,因为 I/O 操作相当的昂贵。数据会先进入到 OS 的 Cache 中,由 OS 之后刷入磁盘。而 MySQL 在整个的逻辑结构上,跟计算机写文件差不多。
从上面的例子看出,存储引擎可以分为两部分:
- 内存
- 磁盘
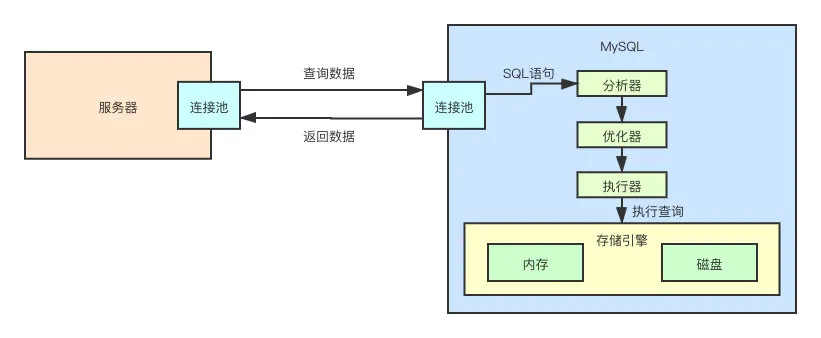
所以,从宏观上来说,MySQL 就是把数据在缓存在内存中,鼓捣鼓捣,然后在某些时候刷入磁盘中去,就这么回事。
接下来,就让我们深入存储引擎 InnoDB 的底层原理中相当重要的一部分——内存架构。
简单来说,InnoDB 的内存由以下两部分组成:
- Buffer Pool
- Log Buffer
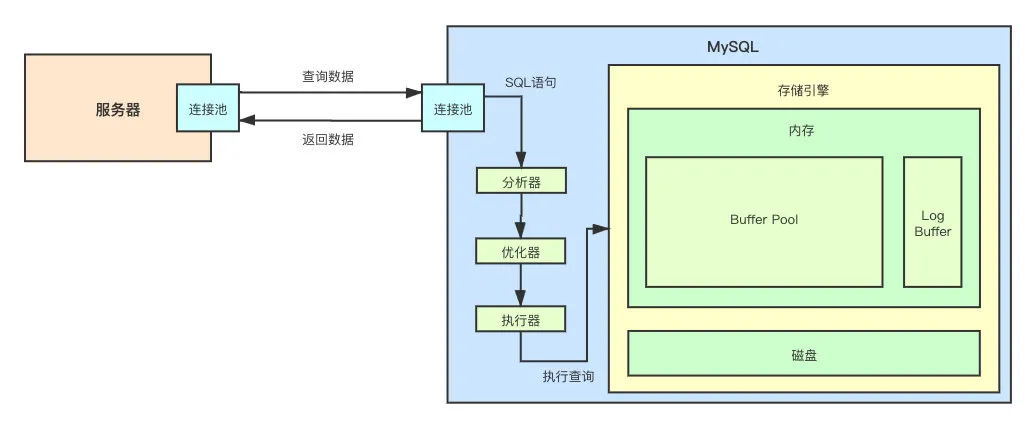
从上面画的图就能够看出,Buffer Pool 是 InnoDB 中非常重要的一部分,MySQL 之所以这么快其中一个重要的原因就是其数据都存在内存中,而这个内存就是 Buffer Pool。
Buffer Pool
一般来说,宿主机的 80% 的内存都会分配给 Buffer Pool。这个很好理解,内存越大,就能够存下更多的数据。这样一来更多的数据将可以直接在内存中读取,可以大大的提升操作效率。
那 Buffer Pool 中到底是如何存储数据的呢?如果其底层的数据存储不进行特殊的设计、优化,那么 InnoDB 在取数据的时候除了整个遍历之外,没有其他的捷径。而如果那样做,MySQL 也不会获得今天这样的地位。
页
如果我们能想象一下,InnoDB 会如何组织内存的数据。想象一下,图书馆的书是直接一本一本的摊在地上好找,还是按照类目、名称进行分类、放到对应的书架上、再进行编号好找?结论自然不言而喻。Buffer Pool 也采用了同样的数据整合措施。
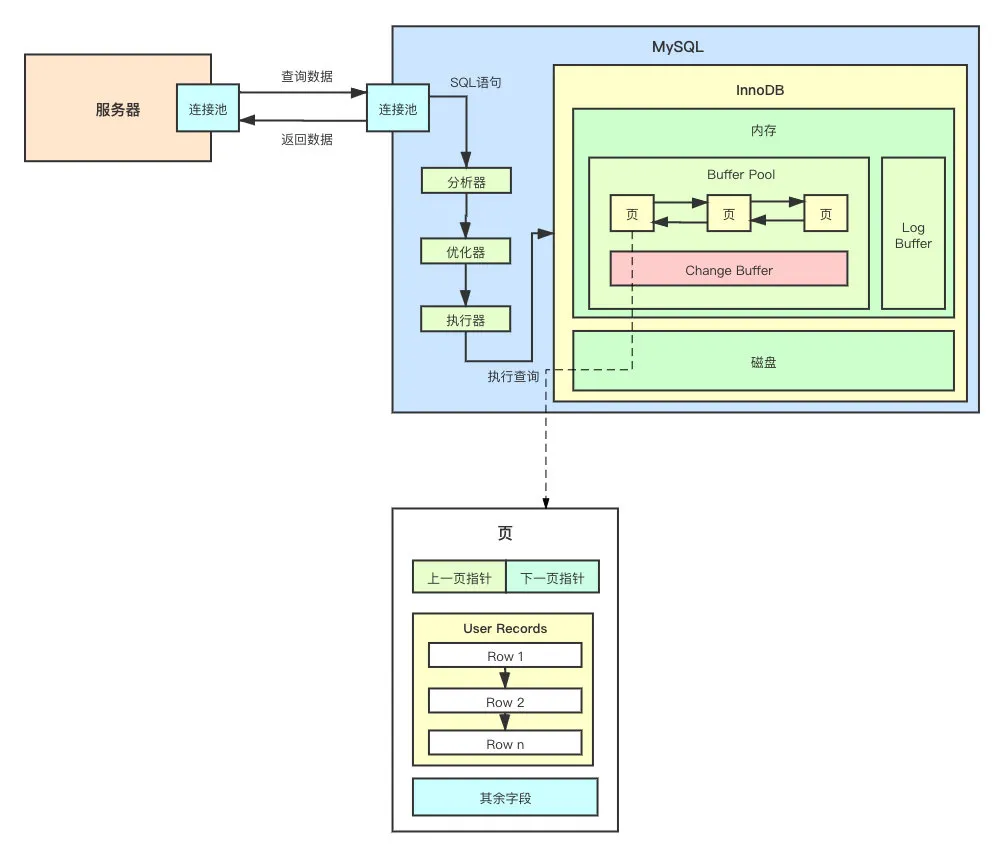
InnoDB 将 Buffer Pool 分成了一张一张的页(Pages),同时还有个 Change Buffer(后面会详细讲,这里先知道就行)。分成一页一页的数据就能够提升查询效率吗?那这个页里面到底是个啥呢?
可以从上图看到,页和页之间,实际上是有关联的,他们通过双向链表进行连接,可以方便的从某一页跳到下一页。
那数据在页中具体是如何存储的呢?
User Records
当然,光跳来跳去的并不能说明任何问题,我们还是揭开页(Pages)这个黑盒的面纱吧。

可以看到,主要就分为
- 上一页指针
- 下一页指针
- User Records
- 其余字段
为了方便理解,其余字段我后续会补充
上一页指针、下一页指针就不多赘述,就是一个指针。重点我们需要了解 User Records。
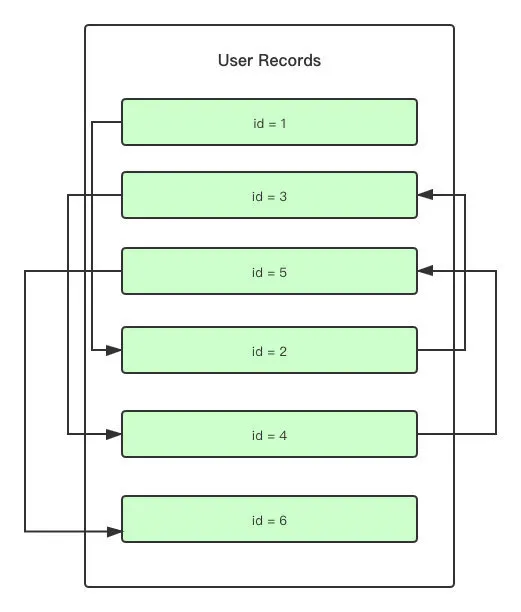
User Records 就是一行一行的数据**(Rows)最终存储的地方,其中,行与行之间形成了单向链表**。
看了这个单向链表不知道你有没有一个疑问。
我们知道,在聚簇索引中,Key 实际上会按照 Primary Key 的顺序来进行排列。那在 User Records 中也会这样吗?我们插入一条新的数据到 User Records 中时,是否也会按照 Primary Key 的顺序来对已有的数据重排序?
如果每次插入数据都需要对 User Records 中的数据进行重排序,那么 MySQL 的江湖地位将再次不保。
虽然在图中看起来是按照「主键」的顺序存储的,但实际上是按照数据的插入顺序来存储的,先到的数据会在前面,后到的数据会在后面,只是每个 User Records 数据的指针指向的不是物理上的下一个,而是逻辑上的下一个。
用图来表示,大概如下:
可以理解为数组和链表的区别。
看到这,那么问题来了,说好的不遍历呢?这不是打脸吗?因为从上图可以看出,我要找查找某个数据是否存在于当前的页(Pages)中,只能从头开始遍历这个单向链表。
就这?还敢号称高性能?当然,InnoDB 肯定不是这么搞的。这下就需要从「其余字段」中取出一部分字段了来解释了。
Infimum 和 Supremum
分别代表当前页(Pages)中的最大和最小的记录。
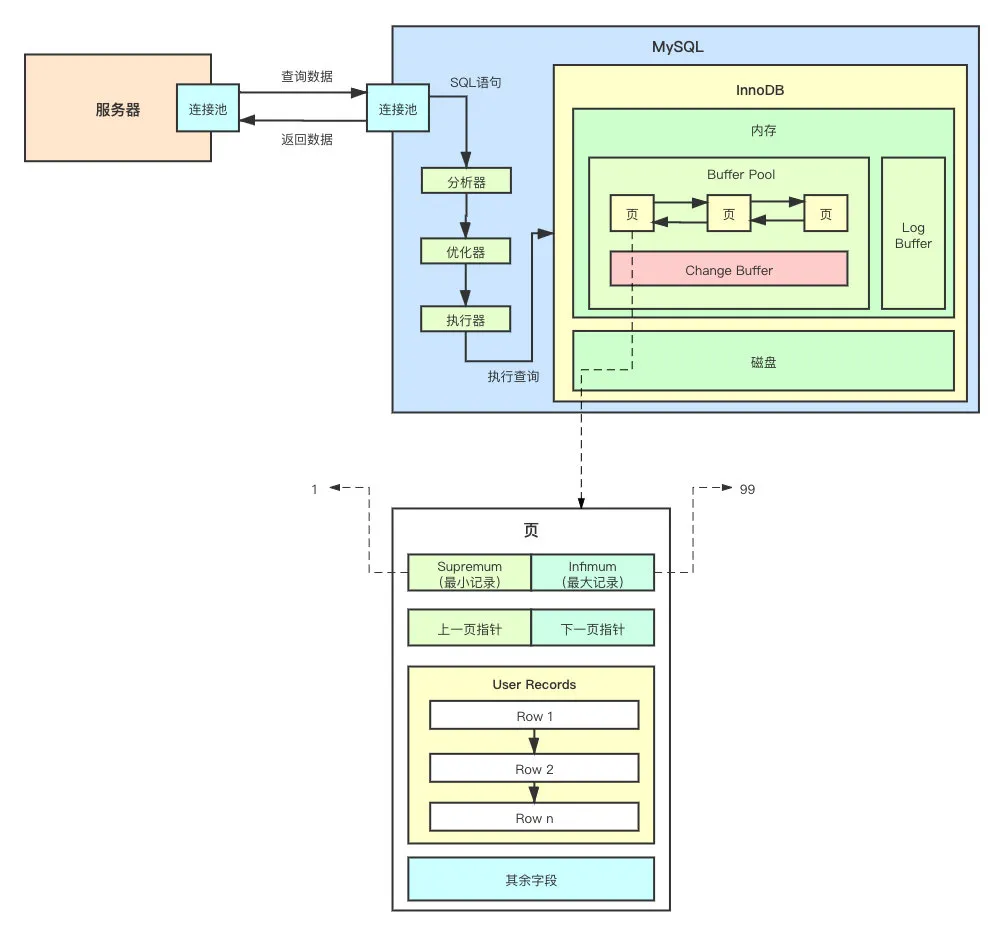
可以看到,有了 Infimum 和 Supremum,我们不需要再去遍历 User Records 就能够知道,要找的数据是否在当前的页中,大大的提升了效率。
但其实还是有问题,比如我需要查询的数据不在当前页中还好,那如果在呢?那是不是还是逃不了 O(N) 的链表遍历呢?算不算治标不治本?
这个时候,我们又需要从「其余字段」中抽一个概念出来了。
Page Directory
顾名思义,这玩意儿是个「目录」,可以看下图。
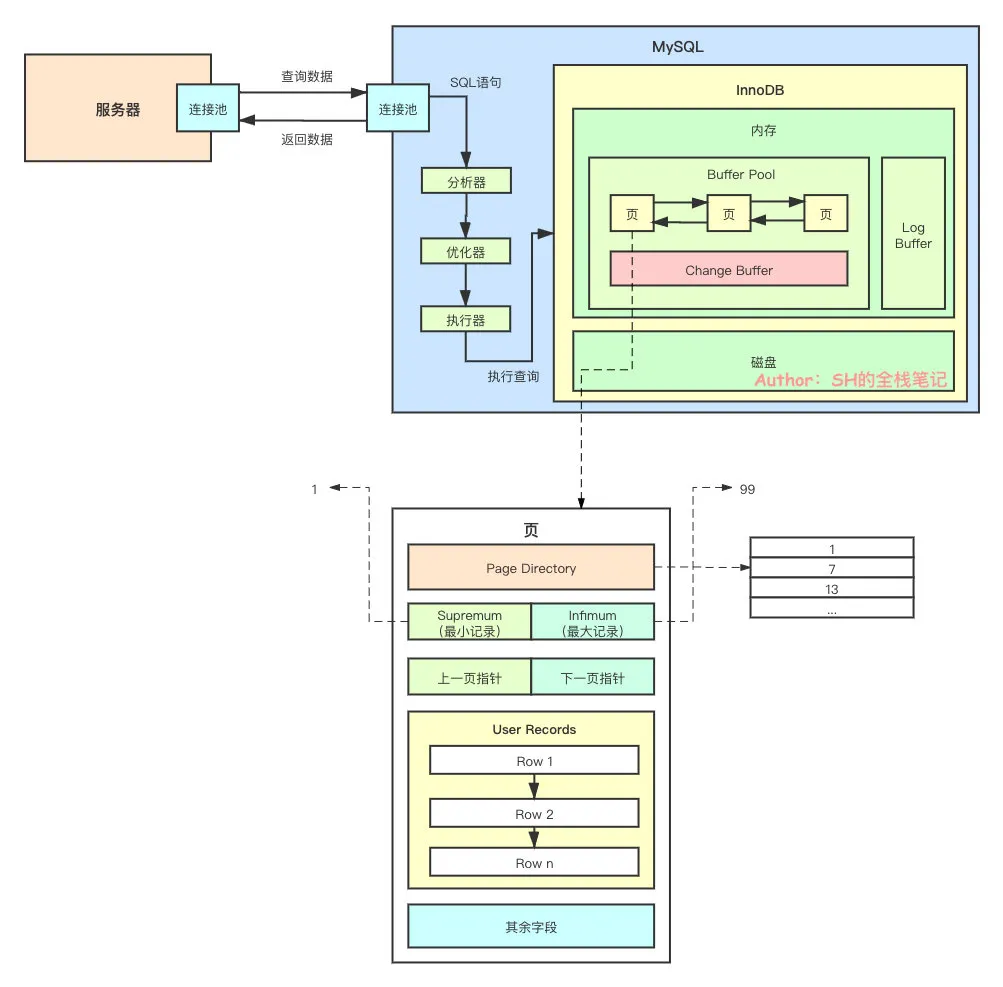
可以看到,每隔一段记录就会在 Page Directory 中有个记录,这个记录是一个指向 User Records 中记录的一个指针。
不知道这个设计有没有让你想起跳表(Skip List)。那这个 Page Directory 中的目录拿来干嘛呢?
有了 Page Directory,就可以对一页中的数据进行类似于跳表的中的查询。在 Page Directory 中找到对应的「位置」之后,再根据指针跳到对应的 User Records 上的单链表,进行查询。如此一来就避免了遍历全部的数据。
上面提到的「位置」,其实有个专业的名词叫「槽位(Slots)」。每一个槽位的数据都是一个指向了 User Records 某条记录的指针。
当我们新增每条数据的时候,就会同步的对 Page Directory 中的槽位进行维护。InnoDB 规定每隔 6 条记录就会创建一个 Slot。
了解到这里之后,关于如何高效地在 MySQL 查询数据就已经了解的差不多了。
想了解「其余字段」还有哪些、以及「页」的完整面貌的,可以去看看我之前写的页的文章 MySQL 页完全指南——浅入深出页的原理,再次就不再赘述。
索引
了解完页之后,索引是什么就一目了然了。InnoDB 底层的存储使用的数据结构为 B+树,B树的变种。MySQL 中有两种索引,分别是聚簇索引和非聚簇索引,听着很高大上。
其实了解完「页」的底层原理,要区分它们就变成的很简单了。
- 聚簇索引的叶子结点上,存储的是「页」
- **非聚簇索引(二级索引)**的叶子结点上,存储的是「主键ID」。很多时候,我们都需要通过非聚簇索引拿到主键,再根据这个主键去「聚簇索引」中拿完整的数据,这个过程还有一个很有意思的名字叫「回表」。
至于为什么底层数据结构要用 B+树 和 B树,大概是因为以下三点:
- B+树能够减少 I/O 的次数
- 查询效率更加的稳定
- 能够更好的支持范围查询
详细的原因可以参考之前写的 浅入浅出 MySQL 索引
更新数据
为什么下一步就是要看如何更新数据呢?因为上述的「页」的原理主要都是基于「查询」的前提在讲,看完了之后对查询的过程应该了然于胸了。接下来我们就来看看更新的时候会发生什么。
首先,如果我们插入了某条 id=100 的数据,然后再去更新的话,这条数据是一定的在 Buffer Pool 的。这句话看似是废话(我都写到数据库了那肯定存在啊)
那我换个说法,更新的时候,id=100 这条数据可能不在 Buffer Pool 中。为什么之前写入了 Buffer Pool,之后再来更新 Buffer Pool 中又没有呢?
答案是内存是有限的,我们不可能无限的向 Buffer Pool 中插入数据。熟悉 Redis 的知道,Redis 在运行时会有「过期策略」,有以下三种:
- 定时过期
- 惰性过期
- 定期过期
而 Buffer Pool 同样也是基于内存,同样也需要一个「过期策略」来清理掉一些不常被访问的数据,来为新的数据、热点数据腾出空间。
当然,这里的清理掉,并不是删除,而是将它们刷入磁盘
更新数据时,如果发现对应的数据不存在,就会将那个数据所在的页加载到 Buffer Pool 中来。注意,这里并不是只加载 id=100 这一行,而是其所在的一整「页」数据。
加载到 Buffer Pool 中之后,再对 Buffer Pool 中的数据进行更新。当然,这个情况对我们开发人员来说,是针对聚簇索引的。
还有另一种情况是针对「 非聚簇索引」 的。
Change Buffer
很简单,当我们更新了某些字段之后,假设这些字段是组成非聚簇索引的字段,就会涉及到非聚簇索引的更新,但不巧的是该非聚簇索引所在的页不在 Buffer Pool 中。按照之前的说法,需要将对应的页(Pages)加载到 Buffer Pool 中来。
但是这里有一个很大的问题,这个二级索引可能之后**根本不会被用到,**那这样一来,刚刚昂贵的 I/O 操作就被浪费掉了。积少成多,如果每次涉及到更新二级索引发现在 Buffer Pool 中不存在,都去做 I/O 操作,那也是一个相当大的开销。
所以,InnoDB 才设计了 Change Buffer。Change Buffer 就是专门用来存储当「非聚簇索引」所在的页不在 Buffer Pool 时的更改的。
换句话说,当对应的非聚簇索引被修改并且对应的页(Pages)不在 Buffer Pool 中时,会将其改动暂存在 Change Buffer,等到其对应的页被其他的请求加载进 Buffer Pool 时,就会将 Change Buffer 中暂存的数据 和 Buffer Pool 中的数据进行合并。
当然,Change Buffer 这个设计也不是没有缺点。当 Change Buffer 中有很多的数据时,全部合并到Buffer Pool可能会花上几个小时的时间,并且在合并的期间,磁盘的 I/O 操作会比较频繁,从而导致部分的CPU资源被占用,对 MySQL 整体的性能是有影响的。
那你可能会问,难道只有被缓存的页加载到了 Buffer Pool 才会触发合并操作吗?那要是它一直没有被加载进来,Change Buffer 不就被撑爆了?很显然,InnoDB 在设计的时候考虑到了这个点。除了对应的页加载,提交事务、服务停机、服务重启都会触发合并。
Adaptive Hash
自适应哈希索引(Adaptive Hash Index)是配合 Buffer Pool 工作的一个功能。自适应哈希索引使得MySQL的性能更加接近于内存服务器。
如果要启用自适应哈希索引,可以通过更改配置innodb_adaptive_hash_index来开启。如果不想启用,也可以在启动的时候,通过命令行参数--skip-innodb-adaptive-hash-index来关闭。
自适应哈希索引是根据索引 Key 的前缀来构建的,InnoDB 有自己的监控索引的机制,当其检测到为当前某个索引页建立哈希索引能够提升效率时,就会创建对应的哈希索引。如果某张表数据量很少,其数据全部都在 Buffer Pool 中,那么此时自适应哈希索引就会变成我们所熟悉的指针这样一个角色。
当然,创建、维护自适应哈希索引是会带来一定的开销的,但是比起其带来的性能上的提升,这点开销可以直接忽略不计。但是,是否要开启自适应哈希索引还是需要看具体的业务情况的,例如当我们的业务特征是有大量的并发 Join 查询,此时访问自适应哈希索引就会产生竞争。
并且如果业务还使用了 LIKE 或者 % 等通配符,根本就不会用到哈希索引,那么此时自适应哈希索引反而变成了系统的负担。
所以,为了尽可能的减少并发情况下带来的竞争,InnoDB 对自适应哈希索引进行了分区,每个索引都被绑定到了一个特定的分区,而每个分区都由单独的锁进行保护。
其实通俗点理解,就是降低了锁的粒度。分区的数量我们可以通过配置innodb_adaptive_hash_index_parts来改变,其可配置的区间范围为[8, 512]。
过期策略
上面提到,Buffer Pool 也会有自己的过期策略,定时的将不需要的数据刷回磁盘,为后续的请求腾出空间。那么,InnoDB 是怎么知道哪些数据是不需要的呢?
答案是 LRU 算法
LRU是**(L**east Recently Used)的简称,表示最近最少使用,Redis 的内存淘汰策略中也有用到 LRU。
但是 InnoDB 所采用的 LRU 算法和传统的 LRU 算法还不太一样,InnoDB 使用的是改良版的 LRU。那为啥要改良?这就需要了解原生 LRU 在 MySQL 有啥问题了。
在实际的业务场景下,很有可能会出现全表扫描的情况,如果数据量较大,那么很有可能会将之前 Buffer Pool 中缓存的热点数据全部换出。这样一来,热点数据被再次访问时,就需要执行 I/O 操作,而这样就会导致该段时间 MySQL 性能断崖式下跌。而这种情况还有个专门的名词,叫——缓冲池污染。
这也是为什么 InnoDB 要对 LRU 算法做优化。
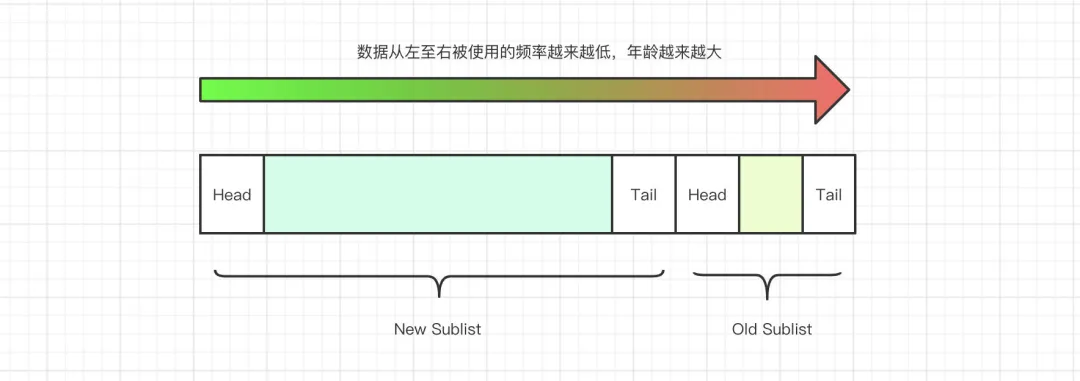
优化之后的链表被分成了两个部分,分别是 New Sublist 和 Old Sublist,其分别占用了 Buffer Pool 的 3/4 和 1/4。
链表的前 3/4,也就是 New Sublist 存放的是访问较为频繁的页。而后 1/4 也就是 Old Sublist 则是反问的不那么频繁的页。Old Sublist中的数据,会在后续 Buffer Pool 剩余空间不足、或者有新的页加入时被移除掉。
了解了链表的整体构造和组成之后,我们就以新页被加入到链表为起点,把整体流程走一遍。首先,一个新页被放入到Buffer Pool之后,会被插入到链表中 New Sublist 和 Old Sublist 相交的位置,该位置叫MidPoint。
该链表存储的数据来源有两部分,分别是:
- MySQL 的预读线程预先加载的数据
- 用户的操作,例如 Query 查询
默认情况下,由用户操作影响而进入到 Buffer Pool 中的数据,会被立即放到链表的最前端,也就是 New Sublist 的 Head 部分。但如果是 MySQL 启动时预加载的数据,则会放入MidPoint中,如果这部分数据再次被用户访问过之后,才会放到链表的最前端。
这样一来,虽然这些页数据在链表中了,但是由于没有被访问过,就会被移动到后 1/4 的 Old Sublist中去,直到被清理掉。
Log Buffer
Log Buffer 用来存储那些即将被刷入到磁盘文件中的日志,例如 Redo Log,该区域也是 InnoDB内存的重要组成部分。Log Buffer 的默认值为16M,如果我们需要进行调整的话,可以通过配置参数innodb_log_buffer_size来进行调整。
当 Log Buffer 如果较大,就可以存储更多的 Redo Log,这样一来在事务提交之前我们就不需要将 Redo Log 刷入磁盘,只需要丢到 Log Buffer 中去即可。因此较大的 Log Buffer 就可以更好的支持较大的事务运行;同理,如果有事务会大量的更新、插入或者删除行,那么适当的增大 Log Buffer 的大小,也可以有效的减少部分磁盘 I/O 操作。
至于 Log Buffer 中的数据刷入到磁盘的频率,则可以通过参数innodb_flush_log_at_trx_commit来决定。