Transformer是一种自注意力模型架构,2017年之后在NLP领域取得了很大的成功。2020年,谷歌提出pure transformer结构ViT,在ImageNet分类任务上取得了和CNN可比的性能。之后大量ViT衍生的Pure Transformer架构(下文中简称为Transformer架构/模型)在ImageNet上都取得了成功。此外,在检测、跟踪、分割等下游视觉任务上,pure transformer的架构也不断取得和CNN可比的性能,但是在更加细粒度的图像检索任务上目前还没有将成功的工作。

- TransReID论文地址:https://arxiv.org/pdf/2102.04378
- TransReID代码:https://github.com/heshuting555/TransReID
在这篇论文中,阿里达摩院的研究团队首次成功将pure transformer架构应用于目标重识别(ReID)任务,提出了TransReID框架,在6个数据集上都取得了超过SOTA CNN方法的性能。
研究背景
纵观整个CNN-based ReID方法的发展,我们发现很多工作都关注两个重要的点:
1)挖掘图片中的全局性信息。CNN网络由于卷积核堆叠的原因,所以感受野存在一个高斯核的衰减。例如图1所示,标准CNN的模型通常会关注于图片中某一两个比较有判别性的局部区域,而会忽视一些全局信息。为了解决这个问题,大量方法通过引入注意力机制来扩大模型的有效感受野,从而得到更好的全局性。但是注意力机制仅仅只是缓解了CNN的这个问题,并不能彻底解决有效感受野高斯衰减的问题。但是Transformer中的自注意力模块会使得每一个patch都和图片中的patch都计算一个attention score,所以相比CNN模型在挖掘全局信息上有天然的优势,并且multi-head也可以挖掘多个判别性区域。可以看到,图1中Transformer-based的方法能够挖掘多个具有判别性的局部区域。
2) 学习细节信息丰富的细粒度特征。CNN网络里面存在下采样操作来获得平移不变性和扩大感受野,但是同时也降低特征图的分辨率,这会丢失图像的一些细节信息。如图2中的这对负样本对(CNN识别错误,Transformer识别正确),两张图片的外观特征是非常相似的,但是从书包的细节可以看出,左边书包侧面有一个杯子,而右边书包侧面则没有杯子,因此可以判断是两个ID。但是因此CNN的下采样操作,在网络最后输出的特征图上已经看不清杯子这个细节了。但是Transformer没有下采样操作,因此特征图能够比较好地保留细节信息,从而识别目标。

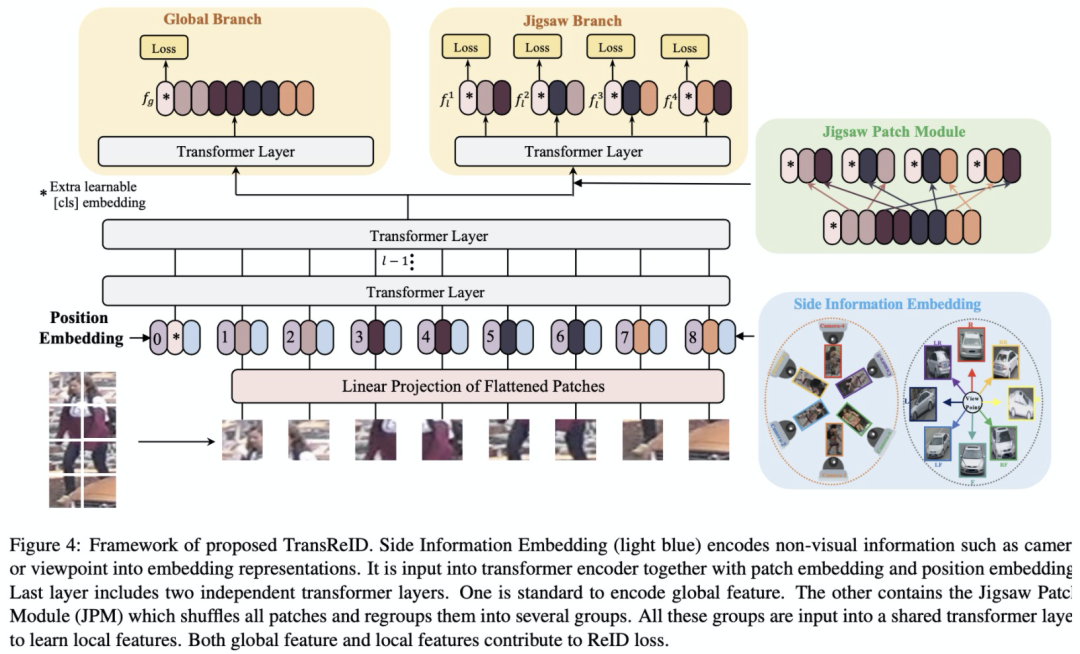
综上所述,Transformer结构是非常适合ReID任务的,但是仅仅用Transformer替换掉CNN backbone并没有充分利用Transformer的特性。本文提出了首个pure transformer的ReID框架TransReID,包含JPM和SIE两个新的模块。之前的ReID工作显示将图片进行切块得到若干个part,然后对每个part提取local特征能够提升性能。我们借鉴了这个设计,将Transformer中的patch embedding分成若干个group,但是这个操作没有充分利用Transformer的全局依赖性。因此我们设计了Jigsaw Patch Module (JPM),将patch embedding随机打乱之后再切分group。Transformer非常擅长encode不同模态的信息,而之前的ReID工作显示相机和姿态信息是有利于ID的识别的,因此我们设计了Side Information Module (SIE) 来利用这些有益的信息。
TransReID
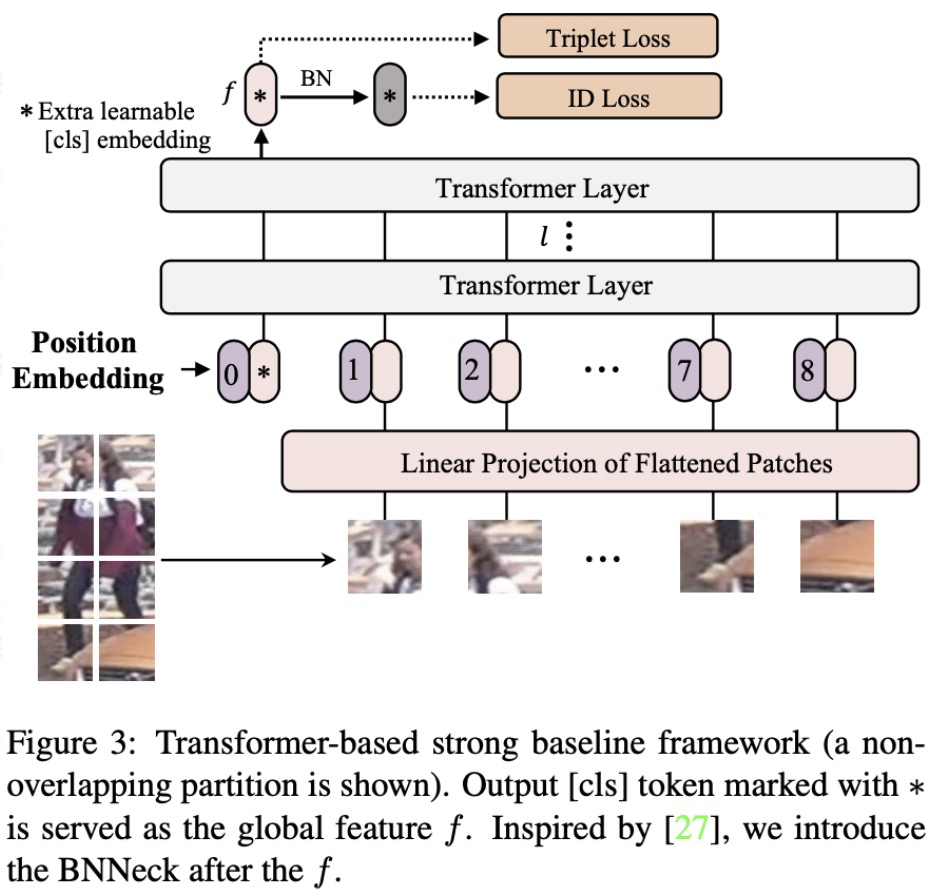
1、Transformer-based strong baseline
我们首先参考CNN的baseline BoT 设计Transformer-based strong baseline。如图图3所示,我们参考ViT将图片分成N个patch,并引入一个额外的cls token共N+1个embedding。经过Transformer layers之后,我们将cls token作为图像的全局特征,之后经过一个BNNeck结构计算triplet loss和分类ID loss。
由于ImageNet预训练的ViT是使用224*224的图像分辨率,而ReID通常使用的分辨率不会是224*224,这造成了position embedding的维度不一样。因此,我们将position embedding按照空间位置进行插值来加载预训练的position embedding参数。
此外,还有一个涨点的tricks是对图像进行patch分块的时候可以让相邻的patch之间有一定的overlap。当然这个操作会使得patch数目增加从而使得模型训练的资源消耗增加,但是性能也会有比较稳定提升。
2、Jigsaw Patch Module
ReID任务经常会遇到遮挡、不对齐这些问题,一般我们会采用细粒度的局部特征来处理这些问题,水平切块就是非常常用的一种局部特征方法。JPM模块借鉴水平切块思想,将最后一层的patch embedding分成k个group (k=4),然后对于每个group进行transformer encode得到N个cls token,每个cls token就相当于PCB中的striped feature,计算一个loss。但是这么做有一个缺点:每个group只包含了图片中一个局部区域的信息,而transformer的特性是能够挖掘全局关联性。为了扩大每个group的「视野」,我们将所有的patch embedding按照一定规则进行打乱,然后再进行分组。这样每个group就可能包含来自图片不同区域的patch,近似等效于每个group都有比较全局的「视野」。此外,打乱操作也可以看做是给网络增加了一些扰动,使得网络能够学习到更加鲁棒的特征。
具体打乱操作分为两步:(1)将最后一层输出的patch embedding去除0号位置的cls token可以得到N个patch embedding,之后将它们进行循环平移m步;(2)第二步参照shuffle的group shuffle操作将N个patch的顺序打乱得到新顺序的N各patch embedding,之后将它们按照新顺序分为k个group,每个group都学习一个cls token,最终concat所有cls token作为最终的feature。

3、Side Information Embeddings
ReID任务中相机、视角的差异会给图像带来一些外观上的差异,所以不少工作关注怎么抑制这些bias。对于CNN框架,通常需要专门设计结构来处理这个问题,例如设计loss、对数据进行先验处理、改变模型结构等等。这些设计通常比较定制化且比较复杂,推广性并不强。而transformer则比较擅长融合不同模态的信息,因此我们提出了SIE模块来利用相机ID、视角等辅助信息。
与可学习的position embedding类似,我们使用了可学习的embedding来编码相机ID和方向ID这些Side information,这个模块成为Side Information Embedding (SIE)。假设总共有Nc个相机ID和Nv个方向ID,某张图片的相机ID和方向ID分别是r和q,则他们最终的SIE编码为:
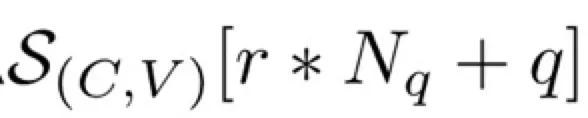
最终,backbone的输入为patch embeding、position embedding和SIE \mathcal{S}_{(C,V)}的加权之和。图4展示了TransReID的完整框架,在ViT的基础上增加了JPM和SIE模块。
实验结果
1、不同Backbone的对比
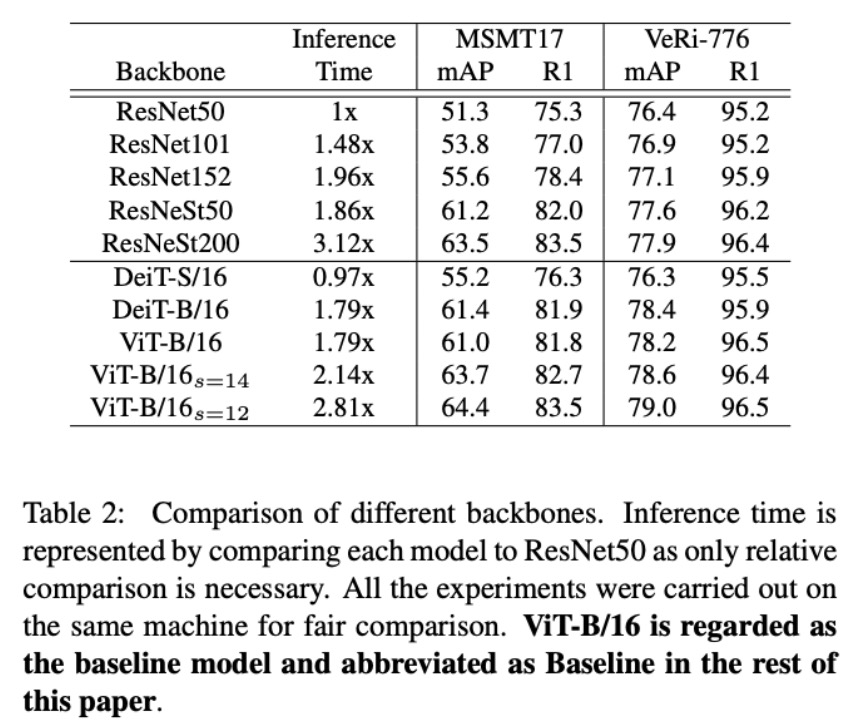
Table 2给出了不同Backbone的准确度和推理时间的对比,我们将ResNet50作为baseline,同时我们给出了ViT和DeiT的结果。可以看到,DeiT-S/16在速度上与ResNet50是接近的,在准确度上同样也有可比的性能。当我们使用更深的DeiT-B/16和DeiT-V/16时,同样和ResNest50取得了相似的速度和准确度。当我们在pre-patch环节缩小conv的stride时,patch的数目增加,速度下降,但是准确度也会收获稳定的提升。
2、Ablation Study
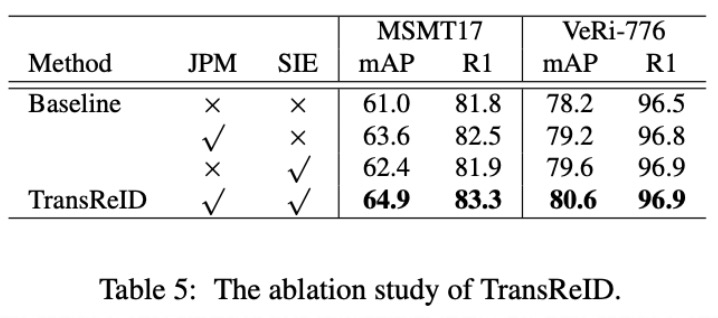
详细的消融实验可以看论文,这里只给出大模块的消融实验,我们以ViT-B/16作为baseline。从Table 5中的结果可以看出,JPM模块和SIE模块都是能稳定带来提升的,TransReID将这两个模块一起用还能进一步提升结果。
3、和SOTA对比
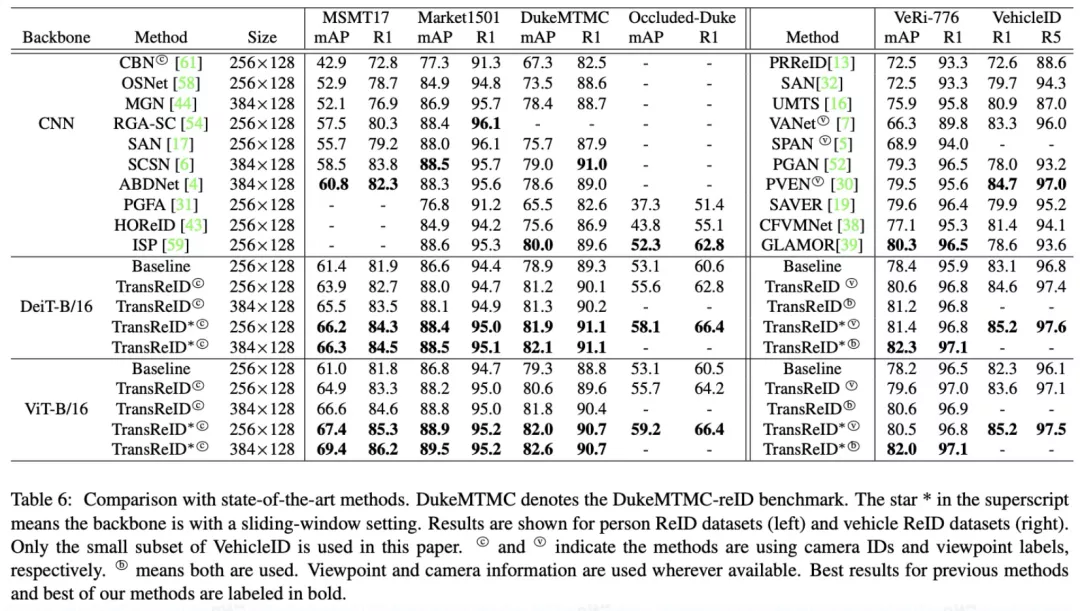
Table 6给出了和SOTA方法对比的结果。可以看到,和CNN的方法相比,TransReID在六个ReID数据集上取得了更好的准确度,这显示了pure transformer架构在图像检索任务上同样适用。
一个有意思的地方是,在ImageNet上取得更好分数的DeiT在下游的ReID任务上并没有超过ViT。这是因为ViT使用了更大的ImageNet22K做预训练,更大的预训练数据使得ViT有更好的迁移性。
4、一些可视化
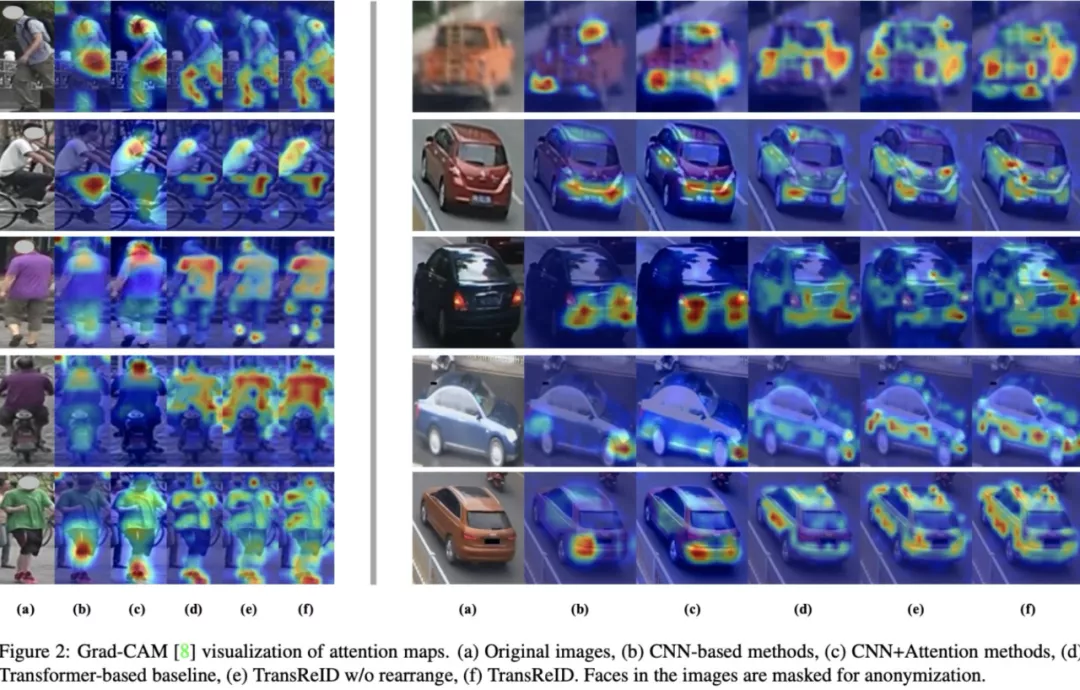
下图给出了CNN和TransReID的注意力可视化结果,可以看出TransReID可以比CNN挖掘到更多判别性区域,同时有更好的全局性特征。
本文的论文作者包括两位:
1.何淑婷,浙江大学博士生,阿里巴巴达摩院研究实习生,研究方向为目标重识别,多目标跟踪等。曾在国内外十几项竞赛中取得前三的名次,其中包括六项冠军。
2.罗浩,2020年博士毕业于浙江大学,毕业后加入阿里巴巴达摩院,从事ReID方向的研究与技术落地工作。累计发表论文20余篇,Google scholar引用累计1000+次,代表作BagTricks Baseline开源代码Star超过1.6K。曾经获得CVPR2021 AICITY Challenge、ECCV2020 VisDA Challenge, IJCAI2020 iQIYI iCartoonFace Challenge等国际比赛冠军。博士期间创立浙大AI学生协会、在B站等平台免费开放《深度学习和目标重识别》课程。