最近,阿里云PAI团队和达摩院智能计算实验室一起发布“低碳版”巨模型M6,大幅降低万亿参数超大模型训练能耗。借助我们自研的Whale框架仅使用480卡GPU,即训练出了规模达人类神经元10倍的万亿参数多模态大模型M6,与传统海外公司实现万亿参数规模相比,能耗降低超八成、效率提升近11倍。
M6是国内首个实现商业化落地的多模态大模型。M6拥有超越传统AI的认知和创造能力,擅长绘画、写作、问答,在电商、制造业、文学艺术等诸多领域拥有广泛应用前景。
这里来为大家介绍支持万亿参数模型训练的Whale框架设计。
一、模型发展趋势和挑战
1.模型发展趋势
随着深度学习的火爆,模型的参数规模也增长迅速,OpenAI数据显示:
- 2012年以前,模型计算耗时每2年增长一倍,和摩尔定律保持一致;
- 2012年后,模型计算耗时每3.4个月翻一倍,远超硬件发展速度。
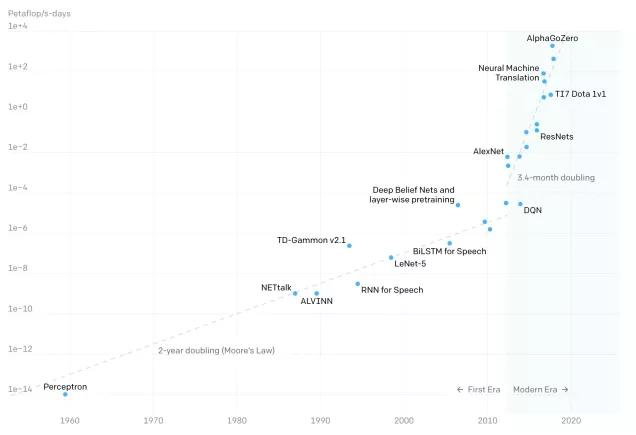
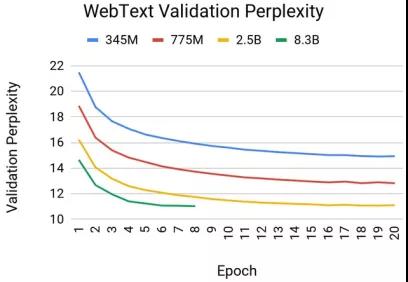
近一年模型参数规模飞速增长,谷歌、英伟达、阿里、智源研究院都发布了万亿参数模型,有大厂也发布了百亿、千亿参数模型。同时,随着模型参数规模增大,模型效果也在逐步提高,Nvidia测试Bert模型不同参数规模,发现模型困惑度随模型参数规模增加而降低。
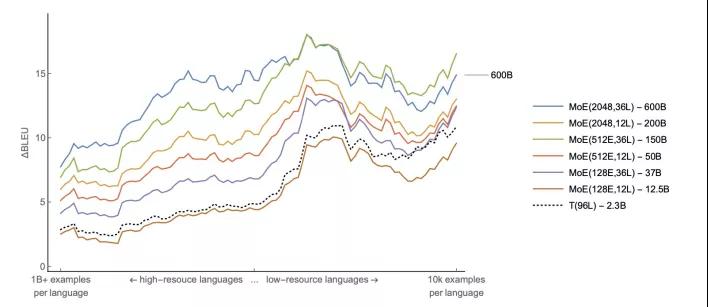
Google在GShard paper中也发现MoETransformer 模型参数规模越大,翻译质量越高。
2.大模型训练的挑战
大模型带来模型效果提升的同时,也为训练框架带来更大的挑战,例如当我们要训练一个万亿规模的模型时会面临如下挑战:
- 训练难:
- GPU显存已经不够存放模型副本,数据并行已经不能满足需求;
- 需要框架提供新的并行策略,协同多GPU能力来存放和训练模型;
- 如何给用户提供简洁、易用的接口,让用户能很容易实现分布式版模型;
- 超大规模模型对计算效率、通信效率都带来很大挑战,如何提高计算和通信效率;
- 下游任务如何对接,如何支持批量预测和在线推理需求;
- 成本高:
- 以万亿模型为例,模型参数有4TB大小、梯度也有4TB,加上optimizer states和active tensor,显存需求巨大;
- 业界训练同等规模模型需要的资源:英伟达 3072 A100、谷歌 2048 TPU v3,成本太高很难落地;
- 如何降本增效,使用更少的资源,更快的训练收敛;
当前已经有一些分布式训练框架,例如:Horovod、Tensorflow Estimator、PyTorch DDP等支持数据并行,Gpipe、PipeDream、PipeMare等支持流水并行,Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分,但这些框架还有一些不足:
- 模式单一:很多框架只支持部分并行策略,不能完全支持各种混合并行;
- 接入门槛高:用户实现模型分布式版本难度大、成本高,需要有领域专家经验才能实现高效的分布式并行策略;
- 迁移代价大:不同分布式框架并行化实现割裂,不同框架有各自定义的DSL,当用户要切换并行策略时,需要学习各种接口,重新改写模型;
- 性能不理想:部分框架实现未考虑集群物理环境;
为了应对当前分布式训练的挑战,我们研发了分布式训练框架Whale,主要目标是:
- 统一多种并行策略:在一个框架中支持各种并行策略以及这些策略的各种组合;
- 简洁易用的接口:用户只需添加几行annotation即可完成并行策略的配置,模型代码不需要改动;
- 高效的训练框架:结合硬件资源、网络拓扑和模型进行协同优化,打造高效分布式训练框架;
二、PAI自研Whale框架
1.Whale架构
我们推出统一多种并行策略的高性能分布式训练框架Whale,从如下角度来应对分布式训练的挑战:
- 将不同并行化策略进行统一抽象、封装,在一套分布式训练框架中支持多种并行策略;
- 基于Tensorflow设计一套分布式并行接口,完全兼容Tensorflow,用户仅仅只需添加几行annotation就可以实现丰富的分布式并行策略;
- 结合模型结构和网络拓扑进行调度和通信优化,提供高效的分布式训练能力。
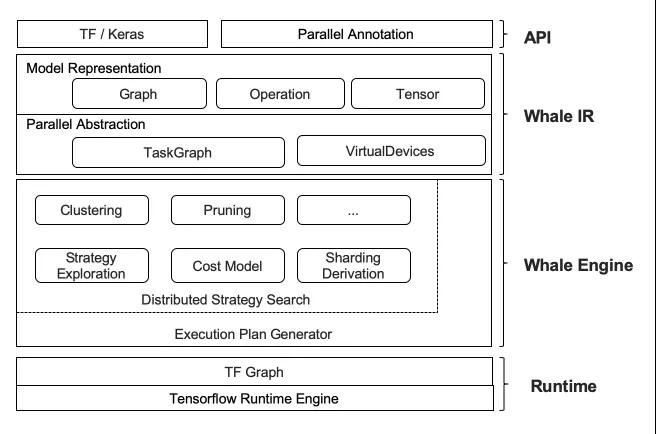
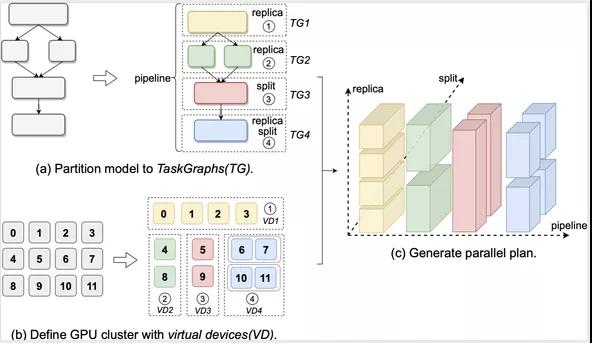
Whale框架如下图所示,主要分4个模块:
- API:提供简洁易用接口,让用户组合使用各种混合并行策略;
- Whale IR:将并行策略转成内部表达,通过TaskGraph、Multi-Dimension、VirtualDevices抽象来表达各种并行策略;
- Whale Engine:基于WhaleIR,通过图编辑工具来构建分布式执行图;
- Runtime:将分布式执行图转成TFGraph,再调用TF 的Runtime来执行;
2.Whale简介易用接口
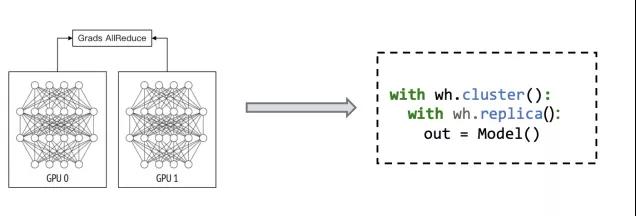
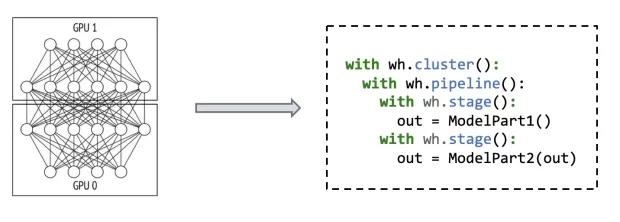
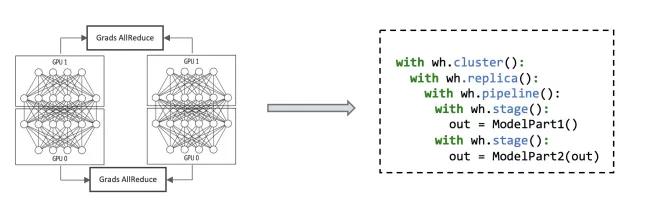
Whale提供简洁易用的接口来描述各种并行策略,主要的原语:
- cluster:配置Virtual Device的划分方法
- replica:数据并行
- stage:划分TaskGraph
- pipeline:流水并行
- split:算子拆分
用这些接口可以组合各种并行策略,例如:
- 数据并行:
- 流水并行:
流水并行+数据并行:
更多并行策略示例:

3.Whale训练流程
使用Whale进行分布式训练流程:
- 并行策略配置:
- 使用Whale API来为模型配置并行策略,只需添加几行annotation,无需修改模型代码,方法如 2.2节 所示;
- 可以将模型划分为多个TaskGraph,TaskGraph支持配置多个并行策略,每个TaskGraph可以配置不同的并行策略;
- 虚拟资源划分:
- 按并行策略来划分Virtual Device,每个TaskGraph对应一个Virtual Device;
- 按GPU资源和网络topo来为Virtual Device选择Physical Device;
- 分布式执行图:
- 基于并行策略和资源分配信息,使用图编辑工具来编辑执行图(图拷贝、拆分、插入通信节点等),生成最终的分布式执行图;
- 调用TF的runtime来执行分布式Graph;
三、万亿M6模型预训练
万亿模型的算力需求非常大,为了降低算力需求,Whale中实现了MoE(Mixture-of-Experts)结构,MoE的主要特点是稀疏激活,使用Gating(Router)来为输入选择Top k的expert进行计算(k常用取值1、2),从而大大减少算力需求。
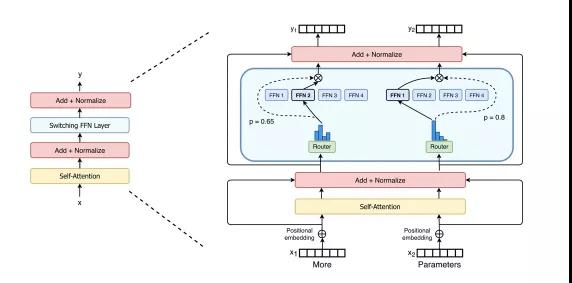
Whale中实现了MoE(Mixture-of-Experts) layer,并支持专家并行,将experts拆分到多个Devices上,降低单个Device的显存和算力需求。同时数据并行有利于提升训练的并发度,因此采用数据并行+专家并行组合的混合并行策略来训练M6模型:MoElayer采用专家并行,其他layer采用数据并行。
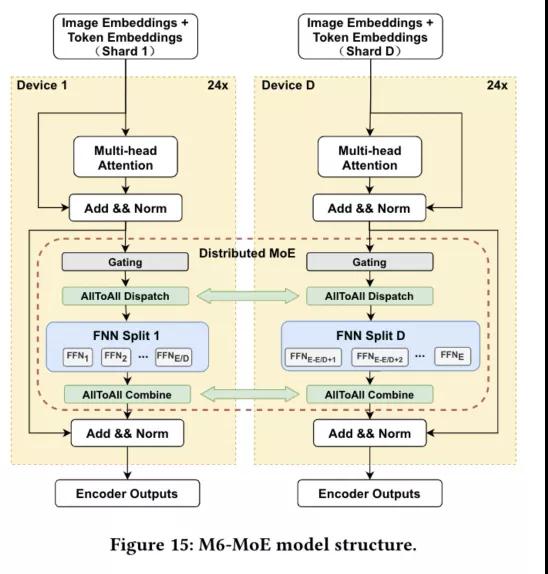
Whale中提供简洁易用的接口来进行模型的混合并行训练,只需要增加几行annotation来配置并行策略,模型本身不需要任何修改。M6模型采用数据并行+专家并行的策略,只需要增加如下图的annotation:

同时为了节约训练资源,提高训练效率,Whale中提供各种优化技术:
显存优化:
- Auto Gradient Checkpoint,自动选择最优checkpoint节点,节约activation的显存;
- Group-wise Apply,优化Optimizer Apply阶段的显存;
- CPU Offload技术,优化Optimizer status和Weight的显存;
- 通信池化,控制通信的数据块大小和并发,节约通信的显存;
计算、通信加速:
- 采用DP+EP混合并行策略,降低算力需求;
- 采用分组融合通信、半精度通信、拓扑感知的All2All通信算子等技术来提高通信效率;
- 结合混合精度、编译优化等技术提高训练效率;
- 借助Whale框架,首次在480 V100 上,3天内完成万亿M6模型的预训练。相比此前英伟达使用3072 A100 GPU实现万亿参数、谷歌使用2048 TPU实现1.6万亿参数大模型,此次达摩院仅使用480卡V100 32G GPU就实现了万亿模型M6,节省算力资源超80%,且训练效率提升近11倍。
四、结语
模型参数规模已越来越大,大模型已成为发展趋势,为解决超大模型训练的挑战,我们自研Whale框架,将不同并行化策略进行统一抽象、封装,在一套分布式训练框架中支持多种并行策略。Whale提供简洁易用的接口,用户只需添加几行annotation即可实现各种并行策略,不需要对模型本身进行修改。同时我们结合硬件资源、网络topo、模型进行软硬件协同优化,提供高效分布式训练框架。
通过Whale框架,我们用480 V100 GPU卡训练万亿规模模型,并在3天内完成模型训练收敛,为超大规模模型训练落地提供了可能,后续我们会进一步完善Whale框架,从更大规模、更快速度、更高性价比3个维度去扩展Whale框架的能力。同时也会推动Whale能力在更多业务场景落地,让技术能力到产品能力的转变。