网上关于分布式事务讲理论的多,讲实战的少,今天我想通过一个案例,来让小伙伴们感受一把分布式事务,咱们今天尽量少谈点理论。咱们今天的主角是 Seata!
分布式事务涉及到很多理论,如 CAP,BASE 等,很多小伙伴刚看到这些理论就被劝退了,所以我们今天不讲理论,咱们就看个 Demo,通过代码快速体验一把什么是分布式事务。
1. 什么是 Seata?
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata 支持的事务模式有四种分别是:
-
Seata AT 模式
-
Seata TCC 模式
-
Seata Saga 模式
-
Seata XA 模式
Seata 中有三个核心概念:
-
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器:定义全局事务的范围,开始全局事务、提交或回滚全局事务。
-
RM ( Resource Manager ) - 资源管理器:管理分支事务处理的资源( Resource ),与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
这些概念小伙伴们作为一个了解即可,不了解也能用 Seata,了解了更能理解 Seata 的工作原理。
2. 搭建 Seata 服务端
我们先来把 Seata 服务端搭建起来。
Seata 下载地址:
-
https://github.com/seata/seata/releases
目前最新版本是 1.4.2,我们就使用最新版本来做。
这个工具在 Windows 或者 Linux 上部署差别不大,所以我这里就直接部署在 Windows 上了,方便一些。
我们首先下载 1.4.2 版本的 zip 压缩包,下载之后解压,然后在 conf 目录中配置两个地方:
1. 首先配置 file.conf 文件
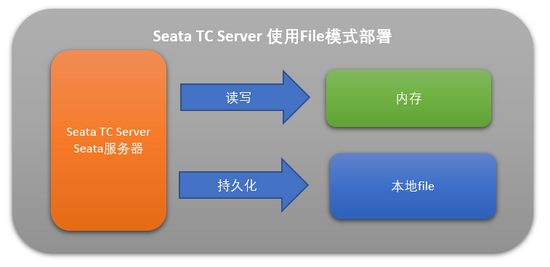
file.conf 中配置 TC 的存储模式,TC 的存储模式有三种:
-
file:适合单机模式,全局事务会话信息在内存中读写,并持久化本地文件 root.data,性能较高。
-
db:适合集群模式,全局事务会话信息通过 db 共享,相对性能差点。
-
redis:适合集群模式,全局事务会话信息通过 redis 共享,相对性能好点,但是要注意,redis 模式在 Seata-Server 1.3 及以上版本支持,性能较高,不过存在事务信息丢失的风险,所以需要开发者提前配置适合当前场景的 redis 持久化配置。
这里我们为了省事,配置为 file 模式,这样事务会话信息读写在内存中完成,持久化则写到本地 file,如下图:
如果配置 db 或者 redis 模式,大家记得填一下下面的相关信息。具体如下图:
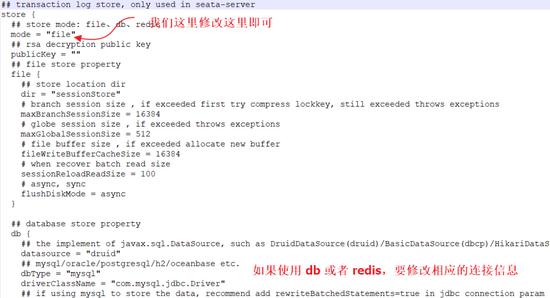
另外还需要注意的是自己的数据库版本信息,改数据库连接的时候按照实际情况修改,Seata 针对 MySQL5.x 和 MySQL8.x 都提供了对应的数据库驱动(在 lib 目录下),我们只需要把驱动改好就行了。
2. 再配置 registry.conf 文件
registry.conf 主要配置 Seata 的注册中心,我们这里采用大家比较熟悉的 Eureka,配置如下:
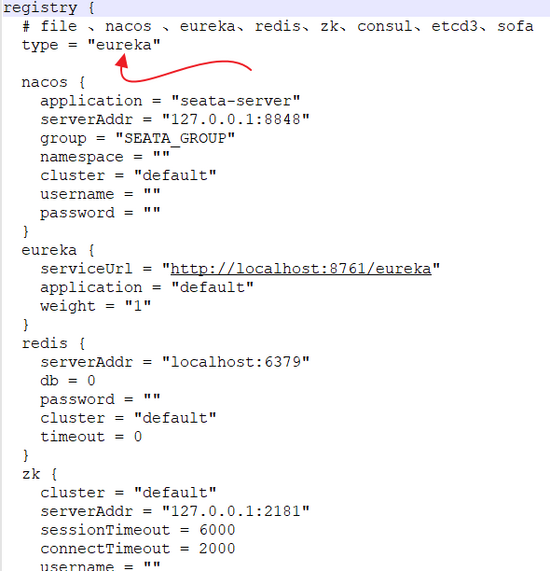
可以看到,支持的配置中心比较多,我们选择 Eureka,选好配置中心之后,记得修改配置中心相关的信息。
OK,现在就配置完成了,但是先别启动,还差一个 Eureka 注册中心。
3. 项目配置
接下来我们配置项目。
Seata 官方提供了一个非常经典的 Demo,我们直接来看这个 Demo。
官方案例下载地址:https://github.com/seata/seata-samples
不过这里是很多案例混在一起的,可能看起来会比较乱,而且由于要下载的依赖比较多,所以极有可能依赖下载失败,因此大家也可以在公众号后台回复 seata-demo 获取松哥整理好的案例,直接导入即可,如下图:
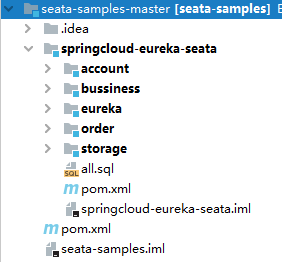
这是一个商品下单的案例,我来和大家稍微解释下:
-
eureka:这是服务注册中心。
-
account:这是账户服务,可以查询/修改用户的账户信息(主要是账户余额)。
-
order:这是订单服务,可以下订单。
-
storage:这是一个仓储服务,可以查询/修改商品的库存数量。
-
bussiness:这是业务,用户下单操作将在这里完成。
这个案例讲了一个什么事呢?
当用户想要下单的时候,调用了 bussiness 中的接口,bussiness 中的接口又调用了它自己的 service,在 service 中,首先开启了全局分布式事务,然后通过 feign 调用 storage 中的接口去扣库存,然后再通过 feign 调用 order 中的接口去创建订单(order 在创建订单的时候,不仅会创建订单,还会扣除用户账户的余额),在扣除库存并完成订单创建之后,接下来会去检查用户的余额和库存数量是否正确,如果用户余额为负数或者库存数量为负数,则会进行事务回滚,否则提交事务。
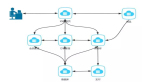
本案例具体架构如下图:
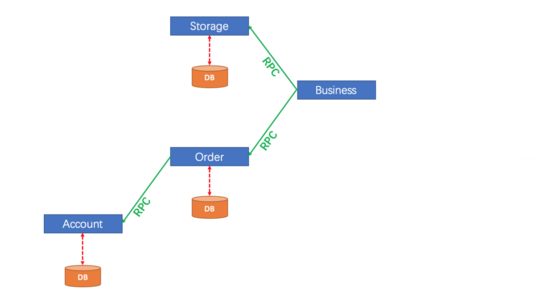
这个案例就是一个典型的分布式事务问题,storage 和 order 中的事务分属于不同的微服务,但是我们希望他们同时成功或者同时失败。
现在大家明白了这个案例是干嘛的,我们就来把它跑起来。
首先创建一个名为 seata 的数据库,然后执行上面代码中的 all.sql 数据脚本。
接下来用 idea 打开上面这个项目,在每一个项目的 application.properties 文件中(Eureka 不用改),修改数据的连接信息,如下图:

除了 Eureka 之外,另外四个都要改哦。
OK,配置结束。
4. 启动测试
首先启动 Eureka。
接下来先别记着启动其他服务,先启动 Seata Server,也就是我们第二小节配置的那个服务,在它的 bin 目录下,Windows 下双击/Linux 下执行启动脚本。

最后再分别启动剩下的四个服务,启动完成后,我们可以在 Eureka 中查看相关信息:
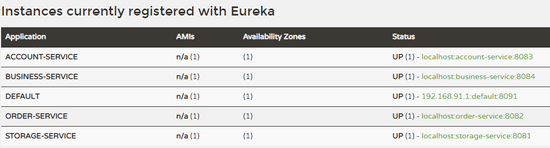
可以看到,各个服务都注册上来了。
接下来我们访问 bussiness 中提供的两个测试接口。
第一个测试接口是:
http://127.0.0.1:8084/purchase/commit
这个接口对应的代码是: io.seata.sample.controller.BusinessController#purchaseCommit ,这个地方是模拟 U100000 用户购买了 30 个 C100000 商品,每个商品的价格是 100 ,商品库存是 200 ,用户账户余额是 10000 ,所以购买之后,商品库存变为 170 ,用户账户余额变为 7000 。这是正常购买的情况。
- @RequestMapping(value = "/purchase/commit", produces = "application/json")
- public String purchaseCommit() {
- try {
- businessService.purchase("U100000", "C100000", 30);
- } catch (Exception exx) {
- return exx.getMessage();
- }
- return "全局事务提交";
- }
当我们调完这个接口之后,就可以去数据库查看相应的数据。
第二个测试的接口是:
http://127.0.0.1:8084/purchase/rollback
这个接口对应的代码是: io.seata.sample.controller.BusinessController#purchaseRollback ,这次是模拟用户购买 99999 个商品,无论是用户账户余额还是商品库存数量,都无法支撑这次购买行为,因此这个接口的调用最终会回滚,数据库中的数据会保持原样。
- @RequestMapping("/purchase/rollback")
- public String purchaseRollback() {
- try {
- businessService.purchase("U100000", "C100000", 99999);
- } catch (Exception exx) {
- return exx.getMessage();
- }
- return "全局事务提交";
- }
这就是一个分布式事务案例。
小伙伴们感兴趣也可以研究一下官方这个案例,我们会发现这里的东西非常简单,单纯是如下方法上多了一个注解而已( io.seata.sample.service.BusinessService#purchase ):
- @GlobalTransactional
- public void purchase(String userId, String commodityCode, int orderCount) {
- storageFeignClient.deduct(commodityCode, orderCount);
- orderFeignClient.create(userId, commodityCode, orderCount);
- if (!validData()) {
- throw new RuntimeException("账户或库存不足,执行回滚");
- }
- }
purchase 方法用 @GlobalTransactional 注解标记了下,就开启了全局事务了,里边的两个调用都是 feign 的调用,对应了不同的服务,最后再做一个数据校验,校验失败就抛出异常,一旦该方法抛出异常,上面已经执行的代码就会回滚。
这个项目其余的代码都是微服务中的常规代码,就不赘述了。
5. 实现原理
我们稍微来说下 Seata 中这个分布式事务的原理,先来看一张图:
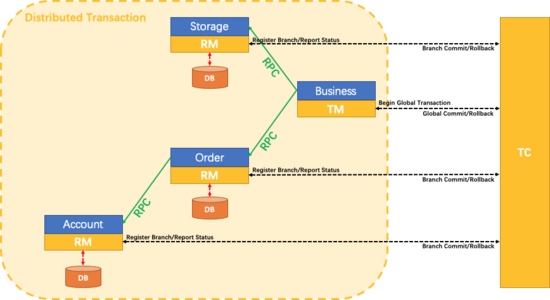
这张图非常清晰的描述了上面的案例,大致流程如下:
-
有三个概念:TM、RM、TC,这些我们在第一小节已经介绍过了,这里就不再赘述。
-
首先由 Business 开启全局事务。
-
接下来 Business 在调用 Storage 和 Order 的时候,这两个在数据库操作之前都会向 TC 注册一个分支事务并提交。
-
分支事务在操作时,都会向 undo_log 表中提交一条记录,当全局事务提交的时候会清空 undo_log 表中的记录,否则将以该表中的记录为依据进行反向补偿(将数据恢复原样)。
具体到上面的案例,事务提交分两个阶段,过程如下:
一阶段:
-
首先 Business 开启全局事务,这个过程中会向 TC 注册,然后会拿到一个 xid,这是一个全局事务 id。
-
接下来在 Business 中调用 Storage 微服务。
-
来解析 SQL:得到 SQL 的类型(UPDATE),表(storage_tbl),条件(where commodity_code = 'C100000')等相关的信息。
-
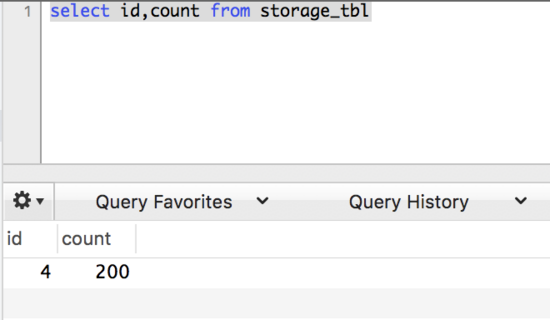
查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
-
执行业务 SQL,也就是做真正的数据更新操作。
-
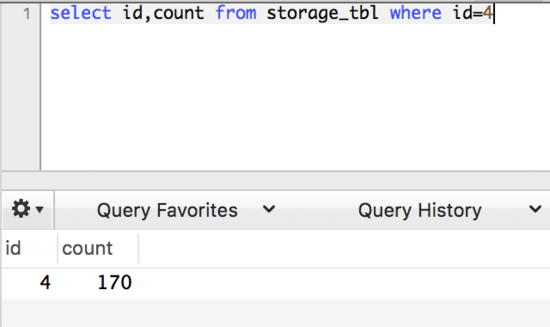
查询后镜像:根据前镜像的结果,通过 主键 定位数据。
-
插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
branch_id 和 xid 分别表示分支事务(即 Storage 自己的事务)和全局事务的 id,rollback_info 中保存着前后镜像的内容, 这个将作为反向补偿(回滚)的依据 ,这个字段的值是一个 JSON,松哥挑出来这个 JSON 中比较重要的一部分来和大家分享:
-
beforeImage:这个是修改前数据库中的数据,可以看到每个字段的值,id 为 4,count 的值为 200。
-
afterImage:这个是修改后数据库中的数据,可以看到,此时 id 为 4,count 的值为 170。


-
Storage 在提交前,会向 TC 注册分支:申请 storage_tbl 表中,主键值等于 4 的记录的全局锁。
-
本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。
-
同理,Order 和 Account 也按照上面的步骤提交数据。
以上 1-10 步就是一阶段的数据提交。
再来看二阶段:
二阶段有两种可能,提交或者回滚。
还是以上面的案例为例:
- @GlobalTransactional
- public void purchase(String userId, String commodityCode, int orderCount) {
- storageFeignClient.deduct(commodityCode, orderCount);
- orderFeignClient.create(userId, commodityCode, orderCount);
- if (!validData()) {
- throw new RuntimeException("账户或库存不足,执行回滚");
- }
- }
下单时候,扣除了库存,并且创建了订单,最后一检查,发现库存为负数或者用户账户余额为负数,说明这个订单有问题,此时就该抛异常回滚,否则就提交数据。
具体操作如下:
回滚:
-
收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
-
通过 xid 和 branch_id 去 undo_log 表中查找对应的记录。
-
数据校验:拿第二步查找到的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理。
-
第三步的比较如果相同,则根据 undo_log 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句。
-
提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
提交:
-
收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
-
异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
换句话说,事务如果正常提交了,undo_log 表中是没有记录的,如果大家想看该表中的记录,可以在事务提交之前通过 DEBUG 的方式查看。
6. 小结
讲了这么多,是不是就把 Seata 讲完了呢?NONONO!这只是 AT 模式而已!还有三种模式,松哥下篇文章再和小伙伴们分享。
好啦,这就是一个简单的分布式事务,小伙伴们先来感受一把!标题是五分钟感受一把分布式事务,因为文章里边我还和大家分享了原理,如果大家只是跑一下案例感受,五分钟应该够了,不信试试!