8月5日,深信服首席算法技术专家章博在信服云《云集技术学社》系列直播课上进行了《数据库概念、分类和未来》的分享,对数据库基础概念、常见数据库种类和使用场景进行介绍,详细解释不同数据架构的优劣,破除常见误区。
看点一:数据库是什么?
数据库定义
大家可能对数据库这个词都不陌生,我们最常说的数据库,也就是Database这个词,原则上它指的是按照一定格式存储数据的文件的组合,也就是说硬盘上的数据库的文件和数据,要按照某种特定的格式去组织,这个就是所谓的数据库。
为了去使用数据库,我们一般需要一整套的数据库管理系统,也就是Database Management System (DBMS),即科学的对数据库文件进行组织、索引、查询、修改的一套管理软件,常见的数据库管理系统有MySQL、Oracle、SQL Server、DB2等。
但是仅仅DBMS本身并不能提供各种各样的能力,我们还需要围绕DBMS去构造由硬件操作系统、数据库管理系统,乃至包括数据库管理员以及相关的机制配套组成的一整套数据库系统,才能顺利的执行工作。这一套系统一般称之为Database System。
与常见的数据管理软件Excel相比,数据库会管理一些更大量的数据,比如说千万行以上的甚至亿万行以上的数据。一般Excel是单人使用的,数据库是很多的用户同时使用,而且可以进行高并发的访问。此外,数据库也有更丰富更复杂的数据处理能力,在安全机制的保障上,Excel作为一个办公软件只能提供密码的基础管理能力,而数据库能够提供完整的安全机制,比如说像是权限的校验(表级别的、行级别的、列级别的权限控制),以及我们可以做一些数据备份来更好的保证数据的安全,这就是数据库管理系统一个主要的好处。
数据库的四个重要概念
(1)索引
数据库经常有上百/千万条记录,单条查询会很慢,而索引的功能就像新华字典的前几页“索引”目录靠拼音或偏旁排序来查询字词,能大幅度提高查询速度。
(2)事务
数据库提供了一种机制,就是一件事,必须做完,如果中间出了差错,他会清理掉一切痕迹,回到最初状态,这对于保持数据的一致性和完整性有功不可没的作用。
(3)联合查询
一份数据通常解决不了实际问题。比如有两份数据,一份是《员工基本信息》,另一份是《工资表》,这个时候,要查询某某员工的工资,就要结合起来做“联合查询”。
(4)SQL
SQL就是用来操作数据库里数据的工具,类似吃饭时使用“筷子”获取食物。
看点二:数据库的分类
数据库可以分为三个维度来分类:第一个维度是按照模型分类,可以分为关系型和非关系型的数据库。第二个维度是根据数据库的使用场景进行分类,主要分为事务性OLTP和分析型OLAP两类。第三种是从数据库架构进行分类,可以分为单点数据库和数据库集群。
按模型分类
按照模型划分,一般把数据库分成关系型和非关系型两个类型。关系型模型由于其优秀的表达能力、严格的数学定义和良好的执行效率被广泛采用,而采用关系型模型组织数据的数据库就被称之为关系型数据库,如 Oracle,MySQL 等。关系型数据库也成为了现在最主流的数据库模型。
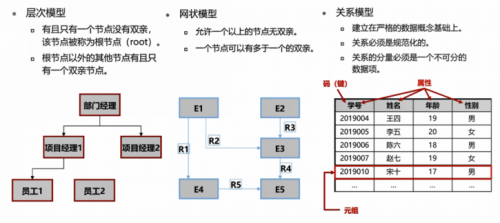
而在一个关系型的数据模型上,提供的查询语言就是结构化查询语言(Structured Query Language)。这样的语言是整个数据库现在能蓬勃发展的一个关键所在,因为它是高级的非过程化的编程语言,比如常见的C语言或者Python编程语言,它都是所谓的过程化编程语言,当需要它做什么的时候,需要一步一步把过程的每一个阶段全部编写好,才能够顺利的进行。但SQL是一个高级的非过程化语言,只需要用户描述需要取得什么样的数据,具体的执行流程就由优化器由甚至系统自动去完成了。所以整个SQL语言的学习和使用非常简单,用户不需要了解具体的数据组织和处理的细节,也不需要去了解如何能让它高效的执行,所有的事情全部都是自动的。
非关系型数据库是通过关系型以外的数据模型对数据进行组织的数据库,通常在特定场景下具有较高的性能和可扩展性。典型 NoSQL 数据库有:(1)键指数据库:Redis、Memcache ——常用于缓存;(2)列族数据库:HBase,Cassandra——常用于 Schema 频繁变更的大宽表数据;(3)文档数据库:MongoDB —— 常用于存储JSON文件;(4)图数据库:Neo4j——常用于知识图谱等图数据组织。
按场景分类
数据库还可以按照不同场景进行分类,主要的两个场景是OLTP和OLAP。OLTP是比较常见的业务系统,比如银行的交易系统、零售交易系统、企业中的ERP系统、医疗的CASE系统等。这些数据库系统里面的数据基本上都是OLTP类型的,支持实时交易数据的存储、更新、共享。
这类系统下,数据不断发生,不断更新,可能有很多人在同时去访问,因此需要的并发也比较高,每次更新都希望反馈的延迟非常低,比如说毫秒级的场景,就是OLTP的场景。
OLAP与我们主要做数据分析和现在的所谓的大数据,也有很多的相似之处,比如BI系统或者说建设数据仓库,会把很多的历史数据汇聚过来,然后做一些综合的分析,希望从中提取一些数据规律,或者做一些数据挖掘。这一类的需求基本上对数据没有很大频繁的修改,但是一次要访问的数据量非常的大,所以不太看重系统的延期,但很看重数据库的吞吐。这样的场景其实就是OLAP场景下常见的数据库。
按架构分类
数据库也可以按照不同架构进行分类。常见的数据库是单节点的数据库,因为单节点可能有一些单点故障的问题。如果有更大的数据量的需求,单节点的数据库没有办法承载,或者需要更大的并发,而此时单点数据库也没有办法承载。这个时候在单节点基础上就发展了一系列的数据库集群架构。

数据库集群架构主要分成三类模式,第一个需要更高的可用性,比如基于组成复制的数据库集群架构或者基于一致性协议的多活数据库集群。基于复制的数据库集群是最常用的多节点数据库架构,它能够消除单点故障,同时通过读写分离提升性能。基于一致性协议的多活数据库集群则是无需第三方仲裁,自维护的多活集群架构,它可以在多数派存活条件下可提供服务。
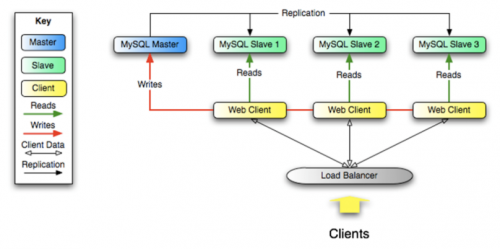
第二个是很多时候在高可用的情况下,遇到面临单节点的数据库性能不够、并发不够的问题,这个时候就需要横向扩展技术。最经典的横向扩展技术就是基于 Shared Disk 的数据库集群,它是基于Shared Disk的共享存储,然后上面可能会有多个节点来共同执行数据库操作的Oracle RAC 的经典架构。它的特点是存储计算分离,通过高速网络和分布式存储替换传统阵列来提升性能。
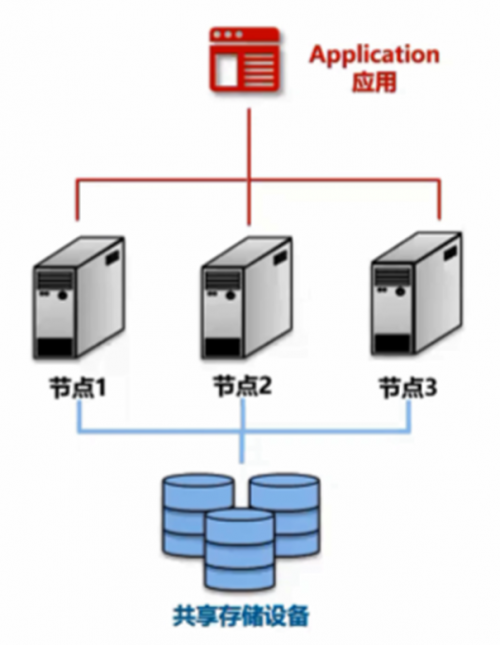
但基于Shared Disk的数据库集群的扩展能力存在限制,难以扩展到百节点以上的超大规模集群,因此就有了基于Share-Nothing的数据库集群。它的每个节点独立,具有最强的扩展能力,可扩展至数百甚至数千节点规模。能支持超大规模并发的基于Share-Nothing数据库集群一般以更高和更不稳定的时延为代价,但是由于和Shared Disk并非完全互斥关系,Share-Nothing集群的每一个节点本身可以是一个Shared Disk 多活集群,从而可以结合两种架构的优势。
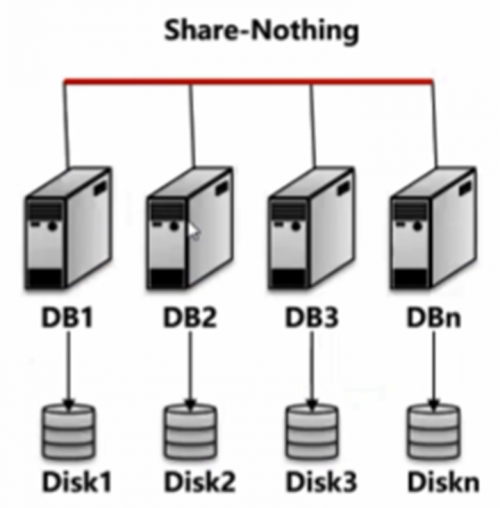
OLTP 场景下的 Share-Nothing 分布式数据库虽然数据是分布式存储和管理的但是单一 SQL 语句的执行大多还是由单一节点执行。相对的,第三类架构就是在OLAP场景下我们需要更大的吞吐时,计算也需要多个节点进行分布式处理,这一架构被称之为 MPP (Massively Parallel Processing)。
看点三:数据库发展趋势
李国良教授的《数据库发展趋势》中介绍,新一代的数据库其实有4个主要的发展方向,一是随着硬件的发展有更多的新的硬件技术被利用下来;二是随着数据模型的发展,会支撑更多的数据模型;三是Scalability进一步提升,最后还有Deployment的种类会变得更加的丰富。
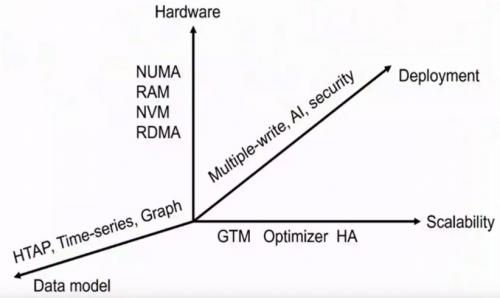
针对种类更加丰富的发展趋势,章博在此介绍了几个比较广泛认知的数据库。一个是现在常见的一个词叫做HTAP,就是既要有TP的特性,又要有AP的特性。在传统的架构下,一般通过ETL把TP的数据按照天或者周的周期去导入到一个AP的系统,用两个不同的系统去承载它,但是传统架构的时效性不足。当需要实时分析时,HTAP就派上用场了,HTAP通过复制或者在同一个引擎里同时做行列混合存储,既能支持实时的数据更新,又可以支持比较高的数据吞吐。但是HTAP系统不会用来去直接替代TP系统,一般来说它还是更偏向用于实时分析的补充。
AI也是非常火热的一个词,在数据库领域的话就有两大的分支,一个是AI4DB,就是如何使用AI技术让数据库的可维护性变得更强。另外一个是DB4AI,DB4AI就是如何对AI的数据进行管理,通过一个很完善的数据库管理系统管理AI的数据,让 AI的开发和迭代更有效。
最后,这几年新的硬件技术发展得也非常的快,对整个数据库系统的优化起着非常大的效果。一个是利用Intel SPDK将NVME SSD性能发挥到极限,另一个是支持RDMA高速网络。
本期回放链接:http://sangfor.bizconf.cn/live/watch/?id=oygey64o