7月8日,深信服大数据负责人Letian在信服云《云集技术学社》系列直播课上进行了《大数据技术原理和发展趋势解析》的分享,对Hadoop、流处理、内存计算、检索、消息队列、大数据OLAP等技术进行了详细分析。以下是他的分享内容简要,想要了解更多可以点击http://sangfor.bizconf.cn/live/watch/technology/?id=mn1x3enl观看直播回放。
看点一:什么是Hadoop?经典的Hadoop技术能做什么?
Hadoop是大数据的经典技术,是一个开源的可运行于大规模集群上的分布式文件系统和运行处理框架。Hadoop擅长于在廉价机器搭建的集群上进行海量数据(结构化与半结构化)的存储与离线处理。
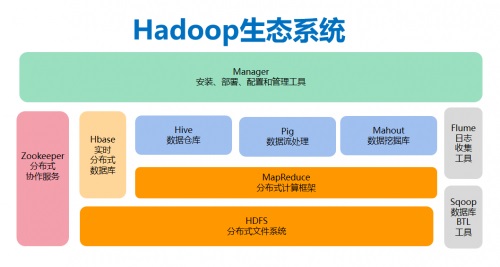
Hadoop的核心是HDFS、Mapreduce和YARN
(1)HDFS
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过主从式的数据存储方式,为分析程序提供高吞吐量的数据访问能力,适合带有大型数据集的分析应用。
(2)MapReduce
MapReduce是一种计算模型,分为"Map(映射)"和"Reduce(归约)"两个部分。基于MapReduce和HDFS,Hadoop的生态生长出了HIVE和Hbase。其中,HIVE定义了一种类似SQL的查询语言(HQL),将SQL“转化为”MapReduce的任务执行。HIVE的特点是非常稳定,极大的数据量都能计算出结果,例如,长达几个小时甚至几天的离线分析就很适合采用HIVE。
(3)Hbase
Hbase是一种基于HDFS的NOSQL,它有稀疏表存储、LSM、二级索引等功能特点,更适合高并发读写访问、实时读写访问,例如推荐画像的标签存储与访问、时空数据(如行车轨迹)、消息/订单(话费详单查询)等场景,很适合运用Hbase。
(4)YARN
YARN是一个资源管理和调度工具,当大数据生态中越来越多类型的计算组件和计算任务类型出现,YARN通过双层调度机制,可以帮助系统管理多种类型组件的计算任务,从而把集群中的计算资源都管理起来,提升资源利用率。比如,在用户提交一个mapreduce计算job之后,多个Map和Reduce的任务就是分别运行在YARN分配的资源容器中。
看点二:近年来常用的大数据生态技术有哪些?
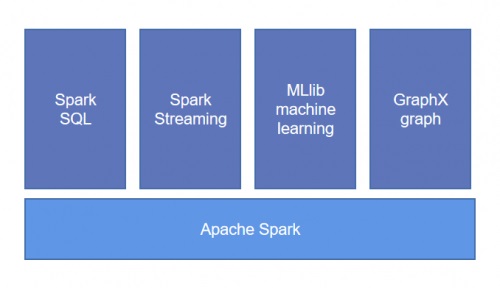
(1)Spark
Spark是基于RDD实现的分布式计算框架,输出和结果保存在内存中,不需要频繁读写HDFS,因此比mapreduce的数据处理效率高。Spark扩展了Mapreduce的原语,除了map和reduce类型的任务之外,还有groupby、union等原语任务。Spark因为是内存计算,适用于“相对近线的或离线”的数据查询(通过sparksql或者原生接口)和实时监控场景(通过SparkStreaming)。另外,内存计算的特点也特别适合迭代计算的场景,例如图计算、机器学习场景。
(2)Flink
Flink是开源流处理框架,与SparkStreaming的区别在于,Spark是微批(一小批)地处理数据,而Flink则可以一条一条地处理数据。在运行时,Flink对实时数据的处理也被分为原语任务(map、keyby等),并将所有的原语任务分布到不同节点上进行并行处理。Flink适用于完全实时的数据分析与机器学习应用场景,例如医疗集成平台的CDC、反欺诈、异常检测、基于规则的报警、业务流程监控等等。
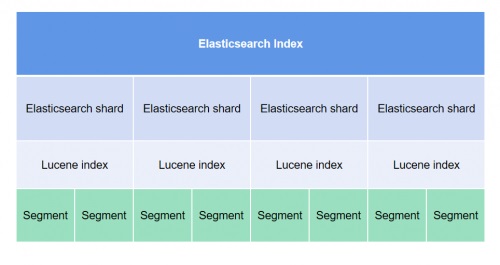
(3)ElasticSearch(ES)
ES是一个基于Lucene的搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。ES实现了Lucene的分布式化:可以扩展到上百台服务器,处理PB级数据。当下不少商品搜索、APP搜索、知识库搜索、日志检索、地理位置查询等,都是使用ES实现的。
(4)Kafka
Kafka是一个分布式、高吞吐量、高扩展性的消息队列系统。在数据需要“总线”来分发给不同的消费者,或者数据产生很快,如果数据消费不够快,需要暂存的场景下,可以提升系统的效率。
看点三:超火的大数据数据仓库与OLAP有哪些关键组件及特性?
大数据数据仓库的主要功能是对大量的数据做系统的分析整理,以便于各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)能够顺利进行,并进而支持如决策支持系统(DSS)、实时分析和查询系统等。
(1)Presto
HDFS、S3、HIVE、KUDU、cassandra、mongoDB、ES、Mysql...越来越多的存储架构,而且各有特点,难以舍弃,那我们能不能用一个引擎统一做查询计算,而不用使用不同的API呢?多源异构分析引擎Presto/Trino就可以解决这个问题。Presto是一款内存计算型的引擎,适用于交互式分析场景,同时其开源社区的良好集成,支持底层数据来自多种异构数据源的交互式分析场景,比如工程师的交互式查询分析、业务人员的交互式查询分析、ETL等。在很多时候,Presto只连接HDFS,那么它就变成了一个OLAP引擎,在这个场景下,Presto最大特点是性能均衡。Presto单表查询仅次于clickhouse,多表join查询性能也很突出。但值得注意的是,Presto虽然比HIVE快,但到了PB级数据时,Presto没办法把所有数据放在内存中处理。所以,需要边读数据、边计算、边清内存。join的时候,可能产生大量的临时数据,反而比HIVE慢。
(2)ClickHouse(CK)
ClickHouse(CK)是一个真正的列式数据库管理系统,主要解决的是“大宽表”的多维分析问题。在很多数据仓库的分析中,报表、交互式分析针对的目标表常常是一个大宽表(列很多),那是否能够把大宽表的性能做极致呢?CK因此应运而生。CK的存储模型MergeTree是最基础的表引擎,提供主键索引、数据分区和数据采样等所有的基本能力。其他能力,比如replace、sum等构建在之上。目前,CK主要应用于BI报表、用户行为分析系统、监控系统、A/Btest等场景下。
(3)kylin
kylin是一个开源的、分布式的分析型数据仓库。查询分析有一些是常用的指标,那能不能将这些指标结果提前计算好,这样一来,交互式查询分析时只查询预先计算好的结果,以此来达到亚秒级响应呢?预计算技术kylin就能实现。但需要注意,预计算计算技术可能会引发维度爆炸。如果一个表有N个维度的话,那么可能会产生2的N次方个预计算结果(类似2的N次方个物化视图),如果计算方式很多的话,那会更多,导致严重膨胀,这时候需要从源头上解决爆炸问题,比较好的方法是分析用户行为,进而只对有必要的结果进行预计算。
看点四:大数据生态中,计算和存储模型的总结!
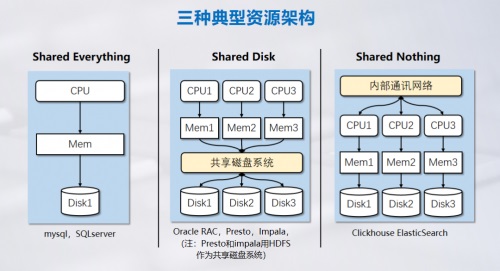
本期直播也总结了不同的计算模型的优劣势,包括从计算视角的scatter/gather、mapreduce、MPP模型分类,从资源共享视角的share everthing、share disk、share nothing的存储计算模型分类。