近来 GPT-3 等基于 Transformer 的深度学习模型在机器学习领域受到了很多关注。这些模型擅长理解语义关系,为大幅改进微软 Bing 搜索引擎的体验做出了贡献,并在 SuperGLUE 学术基准上超越了人类的表现。但是,这些模型可能无法捕获超出纯语义的查询和文档术语之间更细微的关系。
来自微软的研究者提出了一种大规模稀疏模型「Make Every feature Binary(MEB)」,它改进了微软的生产型 Transformer 模型,以提升微软客户使用大规模 AI 时的搜索相关性。为了使搜索更加准确和动态,MEB 更好地利用了大数据的力量,并允许输入特征空间具有超过 2000 亿个二值化特征,这些特征反映了搜索查询和文档之间的微妙关系。
为什么要用「二值化每个特征」的方法来改进搜索?
MEB 能够为基于 Transformer 的深度学习模型提升搜索相关性,其中一个重要的原因是它可以将单个事实映射为特征,从而使 MEB 能够更细致地理解单个事实。例如,许多深度神经网络 (DNN) 语言模型在填写一句话的空白时可能会过度泛化:「(blank) can fly」。由于大多数 DNN 训练样本的结果是「birds can fly」,因此 DNN 语言模型可能会用「birds」这个词来填补空白。
MEB 通过将每个事实分配给一个特征来避免这种情况,例如借助分配权重来区分飞行能力,它可以针对使鸟等任何实体的每个特征执行此操作。MEB 与 Transformer 模型搭配使用,可以将模型提升到另一个分类级别,例如模型产生的结果将不是「鸟类会飞」,而是「鸟类会飞,但鸵鸟、企鹅等鸟类除外」。
随着规模的增加,还有一个元素可以更有效地改进使用数据的方法。Bing 搜索后的网页结果排序是一个机器学习问题,它受益于对大量用户数据的学习。用户点击数据的传统利用方法是为每个印象深刻的查询 / 文档对提取数千个手工构建的数值特征,并训练梯度提升决策树 (GBDT) 模型。
然而,由于特征表示和模型容量有限,即使是 SOTA GBDT 训练器 LightGBM 也要在数亿行数据后才能收敛。此外,这些手工构建的数值特征本质上往往非常粗糙。例如,他们可以捕获查询中给定位置的术语在文档中出现的次数,但有关特定术语是什么的信息在这种表征中丢失了。此外,该方法中的特征并不总是能准确地说明搜索查询中的词序等内容。
为了释放海量数据的力量,并启用能够更好反映查询与文档之间关系的特征表征,MEB 在 Bing 搜索三年中超过 5000 亿个查询 / 文档对上进行训练。输入特征空间有超过 2000 亿个二值化特征。使用 FTRL 的最新版本是具有 90 亿个特征和超过 1350 亿个参数的稀疏神经网络模型。
使用 MEB 能够发现隐藏的关系
MEB 正用于生产中所有区域和语言的 100% 的 Bing 搜索。它是微软提供的最大通用模型,具备一种出色的能力——能够记住这些二值化特征所代表的事实,同时以连续的方式从大量数据中进行可靠的学习。
微软的研究者通过实验发现,对大量数据进行训练是大型稀疏神经网络的独特能力。将相同的 Bing 日志输入 LightGBM 模型并使用传统数值特征(例如 BM25 等查询与文档匹配特征)进行训练时,使用一个月的数据后模型质量不再提高。这表明模型容量不足以从大量数据中受益。相比之下,MEB 是在三年的数据上训练的,研究者发现它在添加更多数据的情况下能够继续学习,这表明模型容量能够随着新数据的增加而增加。
与基于 Transformer 的深度学习模型相比,MEB 模型还展示了超越语义关系的学习能力。在查看 MEB 学习的主要特征时,研究者发现它可以学习查询和文档之间的隐藏关系。
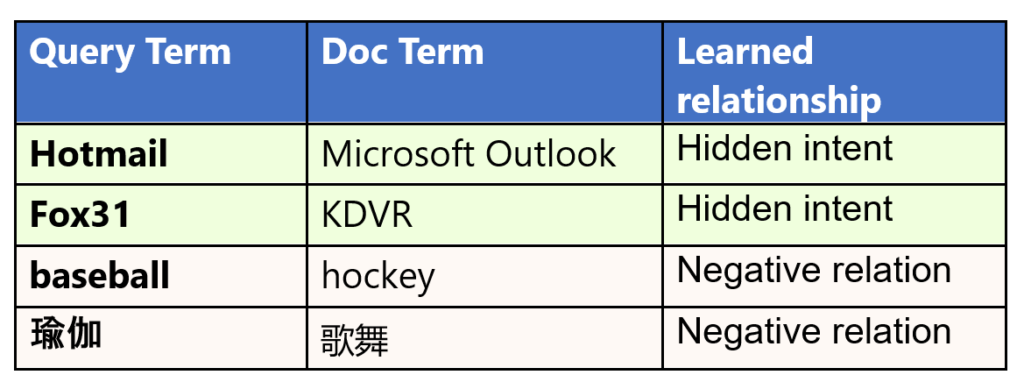
表 1:MEB 模型学习的示例。
例如,MEB 了解到「Hotmail」与「Microsoft Outlook」密切相关,即使它们在语义上并不接近。但 MEB 发现了这些词之间微妙的关系:Hotmail 是一种免费的基于 Web 的电子邮件服务,由 Microsoft 提供,后来更名为 Microsoft Outlook。同样,它了解到「Fox31」和「KDVR」之间有很强的联系,其中 KDVR 是位于科罗拉多州丹佛市的电视频道的呼号,该频道以 Fox31 品牌运营,而表面上看这两个词之间并没有明显的语义联系。
更有趣的是,MEB 可以识别单词或短语之间的负面关系,揭示用户不希望在查询中看到的内容。例如,搜索「棒球」的用户通常不会点击谈论「曲棍球」的页面,即使它们都是流行运动。了解这些负面关系有助于忽略不相关的搜索结果。
MEB 学习的这些关系与基于 Transformer 的 DNN 模型学习的关系非常互补,搜索相关性和用户体验得到了很好的提升。微软在生产型 Transformer 模型的基础上引入 MEB 带来了以下结果:
- 页面中最顶端搜索结果的点击率 (CTR) 增加了近 2%。这些结果在页面折叠上方,无需向下滚动即可找到所需结果。
- 手动查询重构减少了 1% 以上。用户需要手动重新制定查询意味着他们不喜欢他们在原始查询中搜索到的结果,因此该比重减少说明了模型性能的提升。
- 「下一页」等分页点击量减少了 1.5% 以上。用户需要点击「下一页」按钮意味着他们没有在第一页找到他们想要的东西。
MEB 如何在大型数据集上训练和提供特征
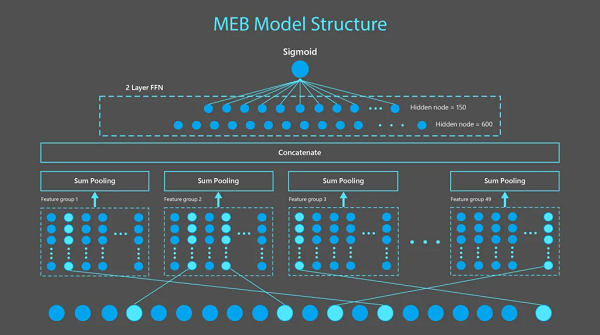
模型结构
如下图 1 所示,MEB 模型是由 1 个二值化特征输入层、1 个特征嵌入层、1 个池化层和 2 个密集层组成。输入层包含从 49 个特征组生成的 90 亿个特征,每个二值化特征被编码为一个 15 维嵌入向量。在每组 sum-pooling 和拼接(concatenation)之后,向量通过 2 个密集层来产生点击概率估计。
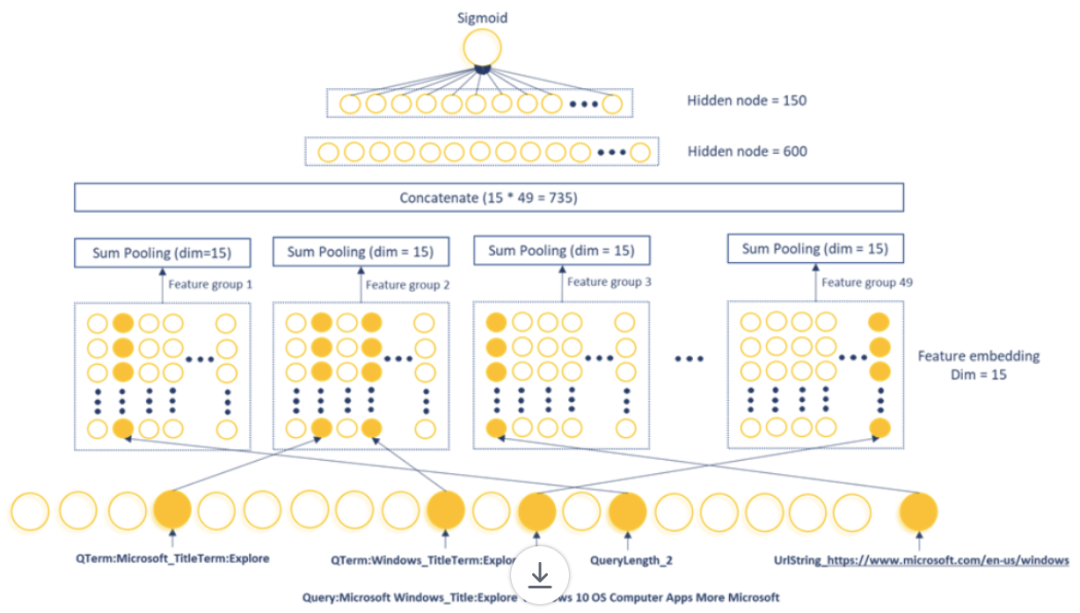
图 1:MEB 是一个稀疏神经网络模型,由一个接受二值化特征的输入层、一个将每个二值化特征转换为 15 维向量的特征嵌入层、一个应用于 49 个特征组中每个特征组并拼接以产生一个 735 维向量的 sum pooling 层,然后通过两个密集层来产生一个点击概率。如下图 2 所示,上图 1 中显示的功能是从样例查询「Microsoft Windows」和链接:https://www.microsoft.com/en-us/windows 中的文档中生成的。
训练数据和将特征二值化
MEB 使用来自 Bing 的三年搜索日志作为训练数据。对于每次 Bing 搜索的结果,该研究使用启发式方法来确定用户是否对他们点击的文档感到满意。研究者将「令人满意」的文档标记为正样本。同一搜索结果中的其他文档被标记为负样本。对于每个查询和文档对,从查询文本、文档 URL、标题和正文文本中提取二值化特征。这些特征被输入到一个稀疏神经网络模型中,以最小化模型预测的点击概率和实际点击标签之间的交叉熵损失。
特征设计和大规模训练是 MEB 成功的关键。MEB 特征是在查询和文档之间非常具体的术语级别(term–level)或 N-gram–level(N-grams 是含有 N 个术语的序列)关系上定义的,传统的数值特征无法捕获这些特征,传统的数值特征只关心查询和文档之间的匹配计数。
为了充分释放这个大规模训练平台的力量,所有的特征都被设计为二值化特征,可以很容易地以一致的方式覆盖手工构建的数值特征和直接从原始文本中提取的特征。这样做可以让 MEB 在一条路径上进行端到端的优化。当前的生产模型使用三种主要类型的特征,包括:
查询与文档的 N-gram 对特征
N-gram 对特征是基于 Bing 搜索日志中查询和文档域的 N-gram 组合生成的。如下图 2 所示,来自查询文本的 N-gram 将与来自文档 URL、标题和正文文本的 N-gram 结合形成 N-gram 对特征。更长的 N-gram(N 值更大)能够捕捉更丰富和更细微的概念。然而,随着 N 的增加,处理它们的成本呈指数级增长。在该研究的生产模型中,N 设置为 1 和 2(分别为 unigrams 和 bigrams)。
分桶数值特征的 one-hot 编码
数值特征首先通过分桶操作,然后应用 one-hot 编码将其二值化。在图 2 所示的示例中,数值特征「QueryLength」可以采用 1 到 MaxQueryLength 之间的任何整数值。研究者为此特征定义了 MaxQueryLength 存储桶,以便查询「Microsoft Windows」查询具有等于 1 的二值化特征 QueryLength_2。
分类特征的 one-hot 编码
分类特征可以通过 one-hot 编码以一种直接的方式转换为二值化特征。例如,UrlString 是一个分类特征,每个唯一的 URL 字符串文本都可以作为一个不同的类别。

图 2:MEB 特征示例。左侧展示了一个查询文档对,其中查询文本、文档标题、URL 和片段作为特征提取的输入。右侧展示了 MEB 产生的一些典型特征。
用持续训练支撑万亿查询 / 文档对(每日刷新)
为了实现具有如此巨大特征空间的训练,该研究利用由 Microsoft Advertising 团队构建的内部大型训练平台 Woodblock,它是一种用于训练大型稀疏模型的分布式、大规模、高性能的解决方案。Woodblock 建立在 TensorFlow 之上,填补了通用深度学习框架与数十亿稀疏特征的行业需求之间的空白。通过对 I/O 和数据处理的深度优化,Woodblock 可以使用 CPU 和 GPU 集群在数小时内训练数千亿个特征。
但即使使用 Woodblock pipeline,用包含近一万亿个查询 / 文档对的三年 Bing 搜索日志训练 MEB 也很难一次性完成。因此该研究使用了一种持续训练的方法,先前已在已有数据上训练的模型,会在每个月的新数据上进行持续训练。
更重要的是,即使在 Bing 中实现以后,模型也会通过使用最新的每日点击数据持续训练而每天刷新,如图 3 所示。为了避免过时特征的负面影响,自动过期策略会检查每个特征的时间戳,并删除过去 500 天内未出现的特征。经过不断的训练,更新模型的日常部署完全自动化。
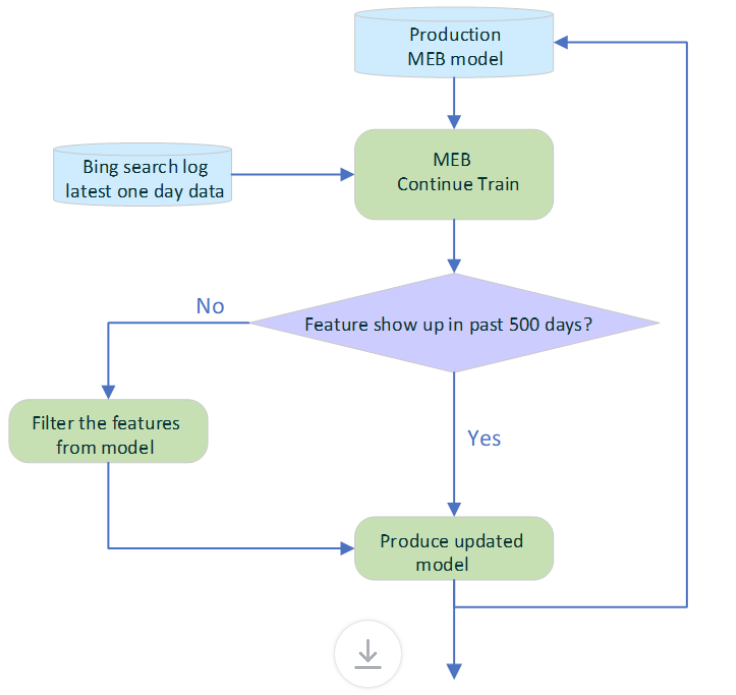
图 3:MEB 每天的刷新流程。生产型 MEB 模型每天都使用最新的单日 Bing 搜索日志数据进行持续训练。在部署新模型并在线提供服务之前,会从模型中删除过去 500 天内未出现的陈旧特征。这可以保持特征的新鲜度并确保有效利用模型容量。
合作应用
使用 Bing ObjectStore 平台为超大模型提供服务
MEB 稀疏神经网络模型的内存占用约为 720 GB。在流量高峰期,系统需要维持每秒 3500 万次特征查找,因此无法在一台机器上为 MEB 提供服务。研究者利用 Bing 的 ObjectStore 服务来支撑 MEB 模型。
ObjectStore 是一种多租户(multi-tenant)的分布式键值存储系统,能够存储数据和计算托管。MEB 的特征嵌入层在 ObjectStore 中实现为表的查找操作,每个二值化特征哈希被用作键,来检索训练时产生的嵌入。池化层和密集层部分的计算量更大,并且在承载用户定义函数的 ObjectStore Coproc(一个 near-data 计算单元)中执行。MEB 将计算和数据服务分离到不同的分片中。每个计算分片占用一部分用于神经网络处理的生产流量,每个数据分片托管一部分模型数据,如下图 4 所示。
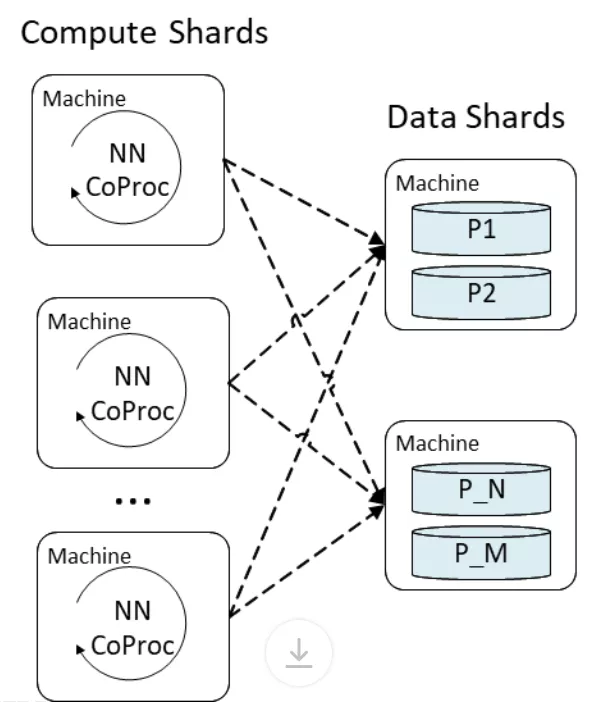
图 4:计算分片中的 ObjectStore Coproc 与数据分片之间进行会进行交互,以检索特征嵌入并运行神经网络。数据分片存储特征嵌入表并支持来自每个 Coproc 调用的查找请求。
由于在 ObjectStore 上运行的大多数工作负载都专门进行存储查找,因此将 MEB 计算分片和内存中数据分片放在一起可以最大限度地利用多租户集群中 ObjectStore 的计算和内存资源。分片分布在多台机器上的设计还能够精细控制每台机器上的负载,以便让 MEB 的服务延迟降低到几毫秒内。
支持更快的搜索,更好地理解内容
研究者发现像 MEB 这样非常大的稀疏神经网络可以学习与基于 Transformer 的神经网络互补的细微关系。这种对搜索语言理解的改进为整个搜索生态系统带来了显著的好处:
- 由于改进了搜索相关性,Bing 用户能够更快地找到内容和完成搜索任务,减少重新手动制定查询或点击下一页的操作;
- 因为 MEB 能够更好地理解内容,发布商和网站管理员可以获得更多访问其资源的流量,并且他们可以专注于满足客户,而不是花时间寻找有助于排名更高的关键字。一个具体的例子是产品品牌重塑,MEB 模型可能能够自动学习新旧名称之间的关系,就像「Hotmail」和「Microsoft Outlook」那样。
如果用户要使用 DNN 为业务提供动力,微软的研究者建议尝试使用大型稀疏神经网络来补充这些模型。特别地,如果拥有大量用户交互历史流并且可以轻松构建简单的二值化特征,则尤其应该使用这种方法。同时他们还建议用户确保模型尽可能接近实时地更新。