本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
在超越人类这件事上,AI 又拿下一分。
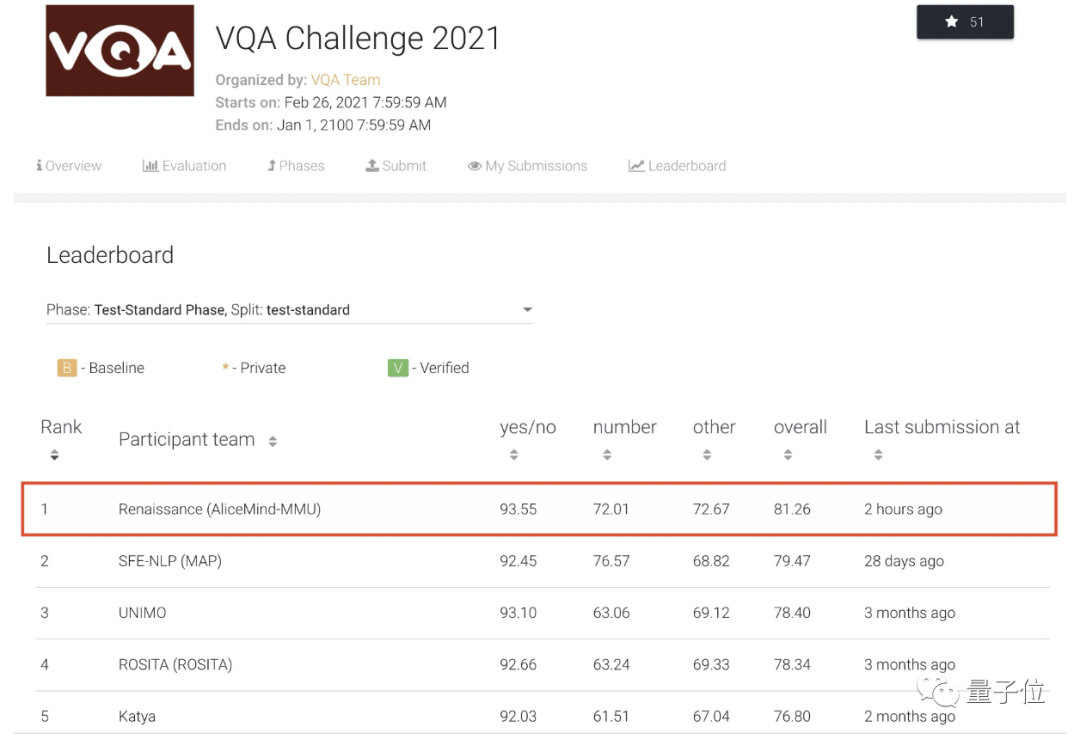
就在最近,国际权威机器视觉问答榜单VQA Leaderboard,更新了一项数据:
AI在“读图会意”任务中,准确率达到了81.26%。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">要知道,我们人类在这个任务中的基准线,也才80.83%。
而解锁这一成就的,是来自阿里巴巴达摩院团队的AliceMind-MMU。
而此举也就意味着,AI 于2015年、2018年分别在视觉识别和文本理解超越人类之后,在多模态技术方面也取得了突破!
AI比你更会看图
这个AI有多会看图?
来看下面几个例子就知道了。
当你问AI:“这些玩具用来做什么的?”
它就会根据小熊穿的礼服,回答道:
婚礼。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">给AI再提一个问题:“男人的橄榄球帽代表哪只球队?”
它会根据帽子中的“B”字母回答:
波士顿球队。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">加大挑战难度再来一个。
“图中玩具人的IP出自哪部电影?”
这时候,AI 就会根据图中的玩具,还有战斗场景等信息,做一个推理。
不过最后还是精准的给出了答案:
星球大战。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">再例如下面这些例子中,AI都会捕捉图片中的细节信息,来精准回答提出的问题。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">嗯,可以说是细致入微了。
怎么做到的?
可能上面的这些案例,对于人类来说并不是很困难。
但对于AI来说,可不是件容易的事情。
一个核心难点就是:
需要在单模态精准理解的基础上,整合多模态的信息进行联合推理认知,最终实现跨模态理解。
怎么破?
阿里达摩院的做法是,对AI视觉-文本推理体系进行了系统性的设计,融合了大量的创新算法。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
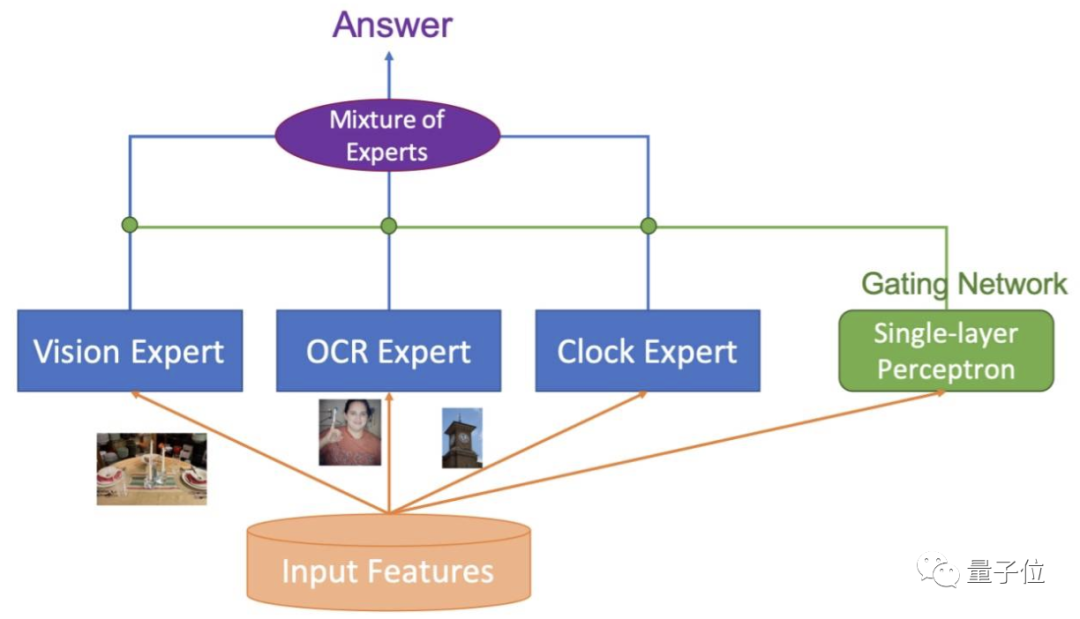
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">具体来看,大致可以分为四个内容:
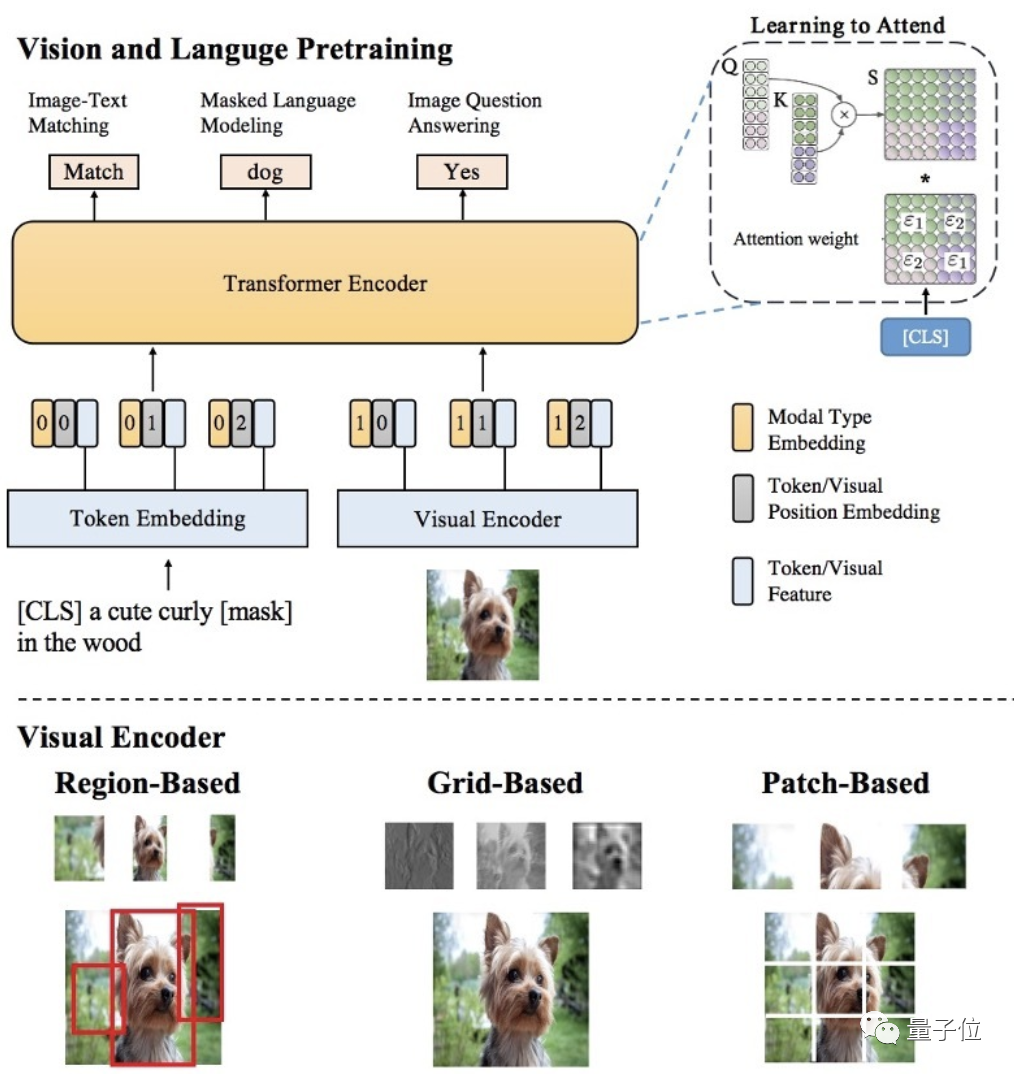
- 多样性的视觉特征表示:从各方面刻画图片的局部和全局语义信息,同时使用Region,Grid,Patch等视觉特征表示,可以更精准地进行单模态理解;
- 基于海量图文数据和多粒度视觉特征的多模态预训练:用于更好地进行多模态信息融合和语义映射,提出了SemVLP、Grid-VLP、E2E-VLP和Fusion-VLP等预训练模型。
- 自适应的跨模态语义融合和对齐技术:在多模态预训练模型中加入Learning to Attend机制,来进行跨模态信息地高效深度融合。
- Mixture of Experts (MOE)技术:进行知识驱动的多技能AI集成。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">据了解,模型中涉及技术还得到了专业的认可。
例如多模态预训练模型E2E-VLP,已经被国际顶级会议ACL2021接受。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">关于VQA
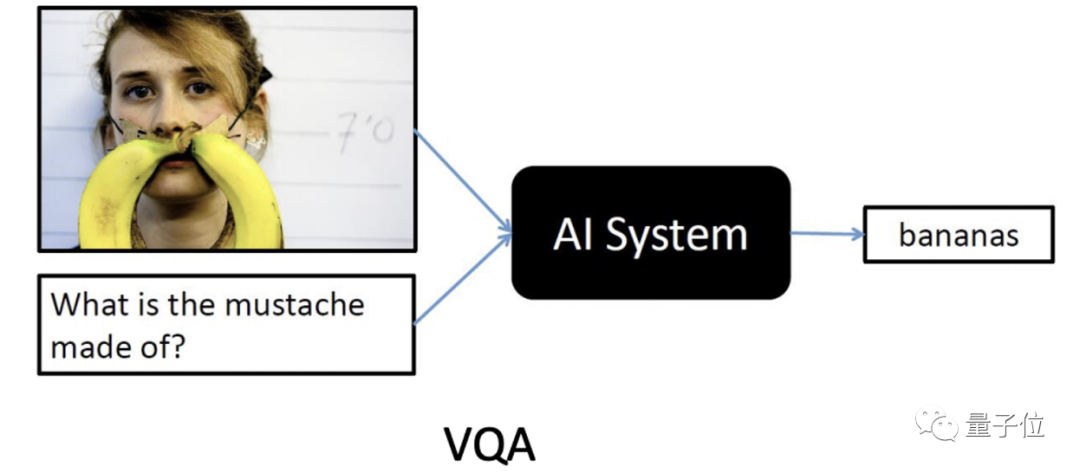
VQA,可以说是AI领域难度最高的挑战之一。
而对于单一AI模型来说,VQA考卷难度堪称“变态”。
在测试中,AI需要根据给定图片及自然语言问题,生成正确的自然语言回答。
这意味着单个AI模型,需要融合复杂的计算机视觉及自然语言技术:
- 首先对所有图像信息进行扫描。
- 再结合对文本问题的理解,利用多模态技术学习图文的关联性、精准定位相关图像信息。
- 最后根据常识及推理回答问题。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">但解决VQA的挑战,对研发通用人工智能具有重要意义。
因此,全球计算机视觉顶会CVPR从2015年起连续6年举办VQA挑战赛。
吸引了包括微软、Facebook、斯坦福大学、阿里巴巴、百度等众多顶尖机构参与。
同时,也形成了国际上规模最大、认可度最高的VQA数据集,其包含超20万张真实照片、110万道考题。
 首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">
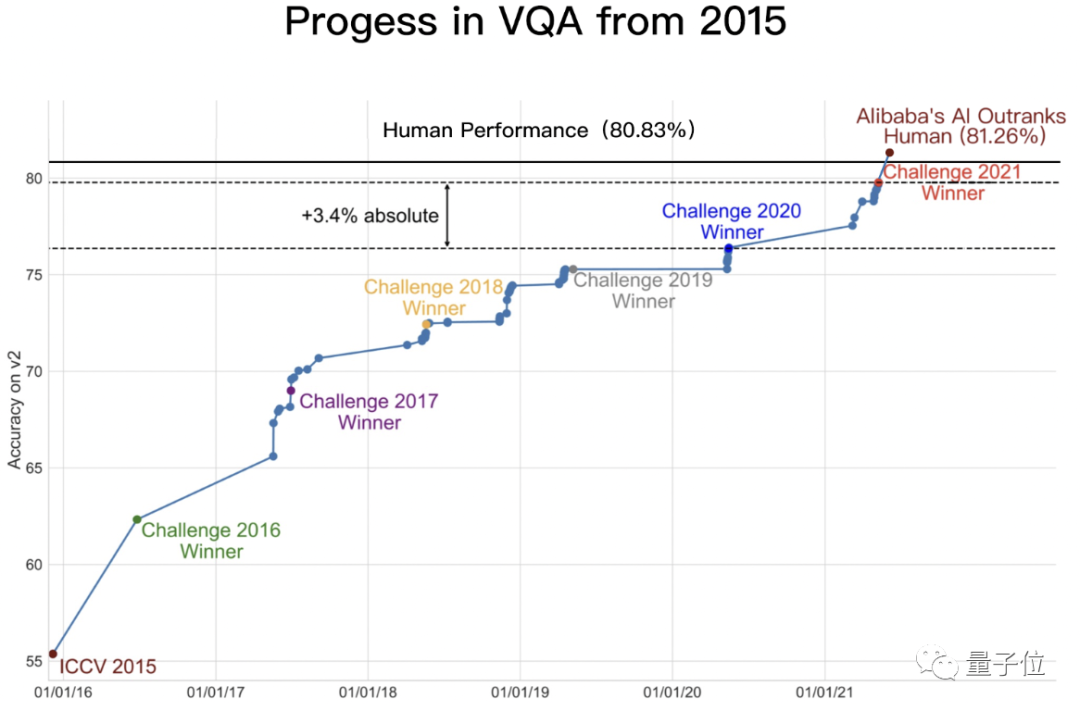
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院">据了解,今年6月,阿里达摩院在VQA 2021 Challenge的55支提交队伍中夺冠,成绩领先第二名约1个百分点、去年冠军3.4个百分点。
而仅仅在2个月后的今天,达摩院再次以81.26%的准确率创造VQA Leaderboard全球纪录。
达摩院对此评价道:
这一结果意味着,AI在封闭数据集内的VQA表现已媲美人类。
相关论文链接:
[1]https://aclanthology.org/2021.acl-long.42/
[2]https://aclanthology.org/2021.acl-long.493/
[3]https://openreview.net/forum?id=Wg2PSpLZiH
VQA示例链接:
https://nlp.aliyun.com/portal#/multi_modal
达摩院AliceMind开源链接:
https://github.com/alibaba/AliceMind