写在前面
cgroup 作为容器底层技术的半壁江山,很多文章已经介绍并总结得很好了,关于 cgroup 是什么、有什么用以及一些相关概念,这些内容并不是本文的重点所以也将不再赘述。大家如有兴趣,可以搜索各路技术文章了解或直接参考官方文档 [1]。
友情提醒:以下内容默认读者已经初步了解 task、cgroup、subsys、hierarchy 是什么及它们之间的关系。
我们为啥关注 cgroup 控制平面性能?
云原生目前是云计算领域的重点发展方向,其中的函数计算场景中,函数执行的速度是重要的性能指标,要求能够快速、高并发地创建和销毁实例。在此场景下的隔离特性普遍都会涉及到大量 cgroup 的相关操作,而现有的cgroup框架设计并发性很差,或许在设计之初并未考虑到大规模的控制平面操作(例如:创建和销毁)。而随着技术的演进,大规模的控制平面操作场景逐渐增多,也促使我们开始更加关注控制平面的性能。
本文的阐述是基于4.19版本的内核源代码,旨在分析cgroup提供给用户的接口背后的实现原理,并基于实现原理给出一些用户态使用cgroup的建议,最后在文章的结尾分享了一些内核态优化的思路。
原理分析
图一
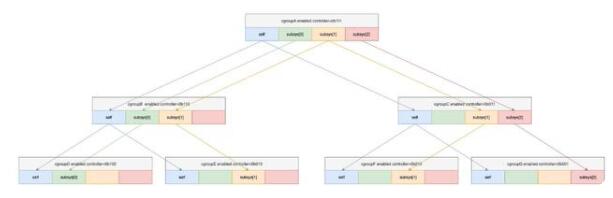
图二
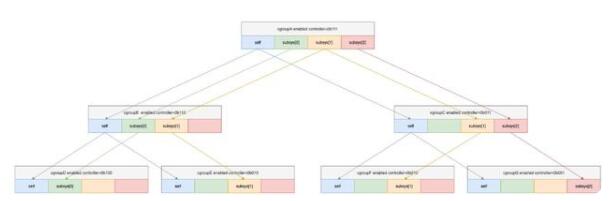
以上两张图,是4.19版本的内核中cgroup中最主要的几个数据结构之间的连接关系和cgroup层次结构的连接关系。
cgroup:字面意思
cgroup_root:hierarchy
cgroup_subsys: 子系统,缩写的变量一般为ss
cgroup_subsys_state: 当指向某个subsys时,代表该subsys在某个cgroup中一个实体
css_set、cset_cgrp_link:用于建立task_struct和cgroup之间多对多的关系
这些数据结构抽象之后是这张图:
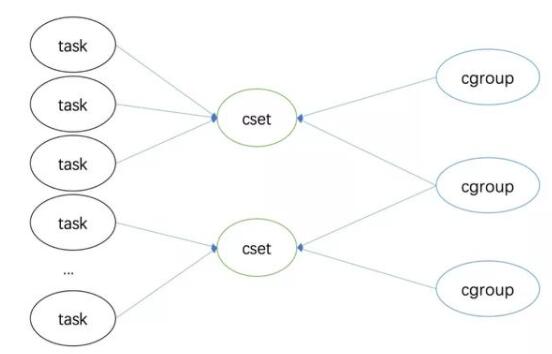
图三
其实也很好理解,本质上cgroup框架要解决的是:一个cgroup管哪些task,一个task归哪些cgroup管的问题,在实现上可通过cset作为中介来建立这层关系。相比于task和cgroup直连,这种做法可以简化复杂的关系。这是因为在实际使用的场景中,task基本都以组为单位进行管理,对某一组task的资源管控方案都大概率是一致的。
对于cgroup的各类操作围绕着这三类实体展开:
创建:在图二所示的树形结构中增加一个叶节点
绑定:本质上是迁移,子进程被fork出来时连接父进程指向的cset,绑定即是从一个cset(如果不再有task指向则删除)迁移到了另一个cset(如果指向的是新的cgroup集合则新创建)
删除:在图二所示的树形结构中删除一个不管控任何task的叶节点
对于cgroup的各类操作的访问控制也围绕这三类实体的展开:
task: cgroup_threadgroup_rwsem锁
cset: css_set_lock锁
cgroup: cgroup_mutex锁
具体的这三类锁有什么作用,将在优化思路里进行分析。
优化方案
问题出在哪?
问题在于三个锁上:cgroup_mutex、cgroup_threadgroup_rwsem、css_set_lock。
cgroup_mutex保护cgroup的整个层级结构。cgroup的层级结构是一个森林,我们需要用这个一个锁来保护整个森林。改变层级结构比如常见的mount、mkdir、rmdir就不必多说了,肯定是需要持有这个锁的;除此之外对cgroup的任何一个其他的操作也需要持有这个锁,比如attach task、以及其他的读或写cgroup提供的接口。同时,因为rmdir的操作是随时都有可能发生的,任何操作都需要与rmdir都互斥。
css_set_lock保护和css_set相关的一切操作。任意进程随时都有可能exit,导致某个css_set释放,从而影响css_set的哈希表。除此之外,对cgroup的绝大多数的操作也会涉及到css_set_lock,这是因为对cgroup的绝大多数的操作(创建除外)都会引起css_set的变化。
cgroup_threadgroup_rwsem保护和cgroup相关的线程组操作,现实中随时都有可能的fork和exit操作导致线程组发生变化。这里用读写锁的原因是,进程自身的行为可能包括改变线程组的组成和持有读锁,这是可以并行的;当进程attach的时候,需要一个稳定的线程组视图,此时如果进程在fork或者exit的话会导致线程组的改变,而attach又是可以以线程组为单位的,不可并行。这里用读写锁并不是说是真的在读什么或写什么,只是恰好符合读者并行,写者需与其他写者互斥这个特性而已。也就是说,fork、exec、exit之间可以并行,类似于读者;attach与其他的都互斥,类似于写者。
这三个锁会受到进程fork和exit的影响,并且也会导致对cgroup的任何操作之间几乎不可并行。笔者在对cgroup进行深入的研究前,觉得是最开始的设计者偷懒,使用如此大粒度的锁,直到把cgroup的框架摸索明白后才发现,临界区就是有这么大,各种会异步发生的事件都需要操作这些数据,所以这些锁被设计成这样也很合理。
这里试着对问题进行抽象,思考一下问题的本质在哪。
对于cgroup_mutex,问题本质是树形(节点是cgroup)结构的并发访问。
对于css_set_lock,问题其实是二部图(一边是css_set,一边是cgroup)结构的并发访问。
对于cgroup_threadgroup_rwsem,问题其实是集合(线程组作为集合的元素)结构的并发访问。
问题的定义已经清楚了,怎么解决呢?以我目前的能力,我没法解。
是的,分析了这么多给的结论是此题无解,或者说暂时无解,可以有的解法也会对cgroup的框架造成刮骨疗毒式的改动。这背后的风险、稳定性的影响、投入产出比的痛能不能承受的住,我给不出一个确定的结论。如果读者有什么想法,欢迎在留言区提出,一起交流。
虽然治本难治,但治标还是可以有点想法的。
用户态优化:减少cgroup操作
这个方案很好理解,提前把cgroup创建和配置好,等需要用的时候直接取就行。这个方案效果极好,简直是降维打击。这里贴一下实验数据,这里的测试模拟袋鼠容器启动时的创建与读写——
这个方案达到了90%以上的优化率,将本来需要创建配置后attach进程最后删除的情况变成了只需要attach,工作量少了,自然也就变快了。
但这个方案存在一些弊端。一方面,池子里不用的cgroup对于系统来讲依然是可见的,需要进行管理,因此会存在一定的负载;另一方面是数据残留问题,并不是所有的subsys都提供类似于clear的操作接口,如果对监控数据有要求的话cgroup就是用一次就废,需要对池子进行补充,增加控制逻辑的同时又出现了竞争,效果会打折扣。最后便是需要明确cgroup的层次结构,毕竟要提前创建和配置,如果对运行时的层次结构无法掌控的话,池子都没法建立。
减少cgroup数量
systemd在默认情况下会把大多数subsys都挂在独立的一个hierarchy下,如果业务的进程都需要受同一些subsys管控的话,可以把这些subsys都挂载在同一个hierarchy下,比如把cpu、memory、blkio挂载在一起。
这时候可能有同学要问了,原本在cpu、memory、blkio下各创建一个cgroup,和在cpu_memory_blkio下创建一个cgroup能有多少区别?该有的逻辑都得有,一个都跑不了,最多就是少了几个cgroup自身这个结构体,能有多少区别?
这里要回归到最开始的场景,cgroup的问题出在场景是高并发,而本质上各类操作却是串行的。我们知道,衡量性能有主要的两个维度:吞吐和延迟。cgroup本质的串行无法直接提高吞吐,各个subsys独立在hierarchy下等于是被拆解成子任务,反而提高了延迟。
下面是测试数据:
内核态优化
对上述三把锁动不了,只能对临界区内的那部分内容下手了。想要缩小临界区,那就需要找出临界区内耗时的部分进行优化。
下图是各个子系统创建cgroup时各个部分的耗时:
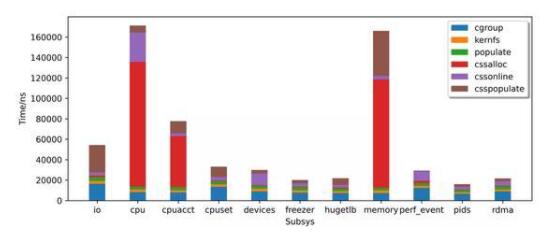
这里简单解释下各个部分做了些什么:
cgroup:创建和初始化cgroup结构体
kernfs:创建cgroup的目录
populoate:创建cgroup控制用的文件接口
cssalloc:分配css
cssonline:css在各个子系统中的online逻辑
csspopulate:创建子系统控制用的文件接口
从图中可以发现cpu、cpuacct、memory的耗时相对于其他的子系统延迟高很多,其中css alloc和css populate占大头。下面我们将研究一下这个“主要矛盾“究竟在做些什么。
通过分析我们发现,css alloc上延迟高是因为给一些percpu的成员分配内存,这一过程比较耗时。css populate上是因为部分子系统的接口文件比较多,需要依次一个个地创建从而消耗更多的时间。
分析过后发现,这些逻辑都是必须没有冗余,怎么优化?做缓存呗。percpu成员变量记录下地址不释放下次重复使用,子系统接口文件在释放时以文件夹为单位移到一个指定的地方,需要时再移回来,只涉及目录文件上一个目录项的读写,开销低且是常数。
通过这两种方式,各个创建cgroup的延时优化结果如下:
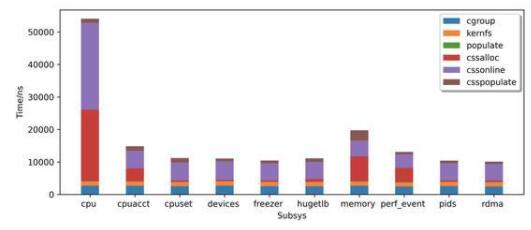
cpu子系统css alloc部分依然比较耗时的原因在于初始化操作比较多,但相比于原先的160us,延时已经降到了50us。
缩小临界区后虽然并不能对并发度有什么影响,但至少延迟降下来了,下面是测试数据。
t个线程并发,每个线程在cpu、cpuacct、cpuset、memory、blkio下创建n个cgroup:
一些假想
如果无视各种限制因素,抛弃现有的框架,不考虑向下兼容,实现一个用于管控进程资源且支持高并发的框架,可以怎么设计?
现在cgroup的机制提供了相当高的灵活性,子系统之间的关系可以随意绑定,task可以随意绑在任意一个cgroup上,如果牺牲一下这些灵活性,对问题的解释是不是就可以变得简单点,下面谈谈我的几个想法。
第一,前文提到的为了减少cgroup数量,把所有的子系统都绑定在一起的想法,是否可以固化在内核当中,或者说不提供子系统独立挂载和绑定挂载的特性?这样,进程组与cgroup变成了一一对应的关系,cset就没有了存在的意义,css_set_lock带来的问题也不攻自破。但是对应的弊端是,一个进程组内的所有进程在每个子系统上资源控制都是一致的。
第二,cgroup层级结构是否有存在的必要?现在cgroup以树形结构组织,确实在逻辑上更加符合现实。比如,在第一层给业务分配总资源,在第二层给业务的各个组件分配资源。但在操作系统分配资源的视角上,以及业务进程具体获得资源的视角上,第一层的存在并没什么作用,只是给用户提供了逻辑更清晰的运维管理。如果把cgroup v2提出的no internal process特性也应用上,可以把cgroup层级扁平化到只有一层。
cgroup只有一层的好处是,可以很方便地把cgroup_mutex粒度细化,细化到每个cgroup一把锁,不会存在好几层的树形结构——改动一个cgroup需要从祖先开始持锁的问题。锁的粒度细化后,在并发启动容器实例的时候,因为对应不同的cgroup,也就不会存在竞争的问题。
第三,cgroup的删除能否加以限制?现在是用户异步手动删除空的cgroup,如果可以在cgroup不再管理进程(exit,move)时隐藏,后续找个时机触发删除,便可以少一个竞争场景。这种方法会造成空的cgroup没法再利用,现在有对空cgroup再利用的需求吗?
最后,绑定进程能否加以限制?task绑定cgroup的本质是移动,从一个cgroup到另一个cgroup。cgroup_mutex粒度细化后会存在ABBA的死锁问题。有一个问题是,task存在绑定到一个cgroup后再绑定的需求吗?理想情况是绑定一个后顺利运行然后退出。基于这种假设就可以做一个限制,只允许task在绑定时,src与dst内必须包含default cgroup、default cgroup起一个跳板作用。
上面这些都是我一些不成熟的想法,欢迎讨论。
最后
本文中提到的一些优化技术目前集成进入 Alibaba Cloud Linux [2] 中,并已经在云原生场景中得到进一步应用。
附
[1] cgroup 相关官方文档
https://man7.org/linux/man-pages/man7/cgroups.7.html
[2] Alibaba Cloud Linux:
https://www.aliyun.com/product/alinux