Transformer和CNN在处理视觉表征方面都有着各自的优势以及一些不可避免的问题。因此,国科大、鹏城实验室和华为研究人员首次将二者进行了融合并提出全新的Conformer模型,其可以在不显著增加计算量的前提下显著提升了基网表征能力。论文已被ICCV 2021接收。
卷积运算善于提取局部特征,却不具备提取全局表征的能力。
为了感受图像全局信息,CNN必须依靠堆叠卷积层,采用池化操作来扩大感受野。
Visual Transformer的提出则打破了CNN在视觉表征方面的垄断。
得益于自注意力机制,Visual Transformer (ViT、Deit)具备了全局、动态感受野的能力,在图像识别任务上取得了更好的结果。
但是受限于计算复杂度,Transformer需要减小输入分辨率、增大下采样步长,这造成切分patch阶段损失图像细节信息。
因此,中国科学院大学联合鹏城实验室和华为提出了Conformer基网模型,将Transformer与CNN进行了融合。
Conformer模型可以在不显著增加计算量的前提下显著提升了基网表征能力。目前,论文已被ICCV 2021接收。

论文地址:https://arxiv.org/abs/2105.03889
项目地址:https://github.com/pengzhiliang/Conformer
此外,Conformer中含有并行的CNN分支和Transformer分支,通过特征耦合模块融合局部与全局特征,目的在于不损失图像细节的同时捕捉图像全局信息。

特征图可视化
对一张背景相对复杂的图片的特征进行可视化,以此来说明Conformer捕捉局部和全局信息的能力:
- 浅层Transformer(DeiT)特征图(c列)相比于ResNet(a列)丢失很多细节信息,而Conformer的Transformer分支特征图(d列)更好保留了局部特征;
- 从深层的特征图来看,DeiT特征图(g列)相比于ResNet(e列)会保留全局的特征信息,但是噪声会更大一点;
- 得益于Transformer分支提供的全局特征,Conformer的CNN分支特征图(f列)会保留更加完整的特征(相比于e列);
- Transformer分支特征图(h列)相比于DeiT(g列)则是保留了更多细节信息,且抑制了噪声。
网络结构
Conformer是一个并行双体网结构,其中CNN分支采用了ResNet结构,Transformer分支则是采用了ViT结构。
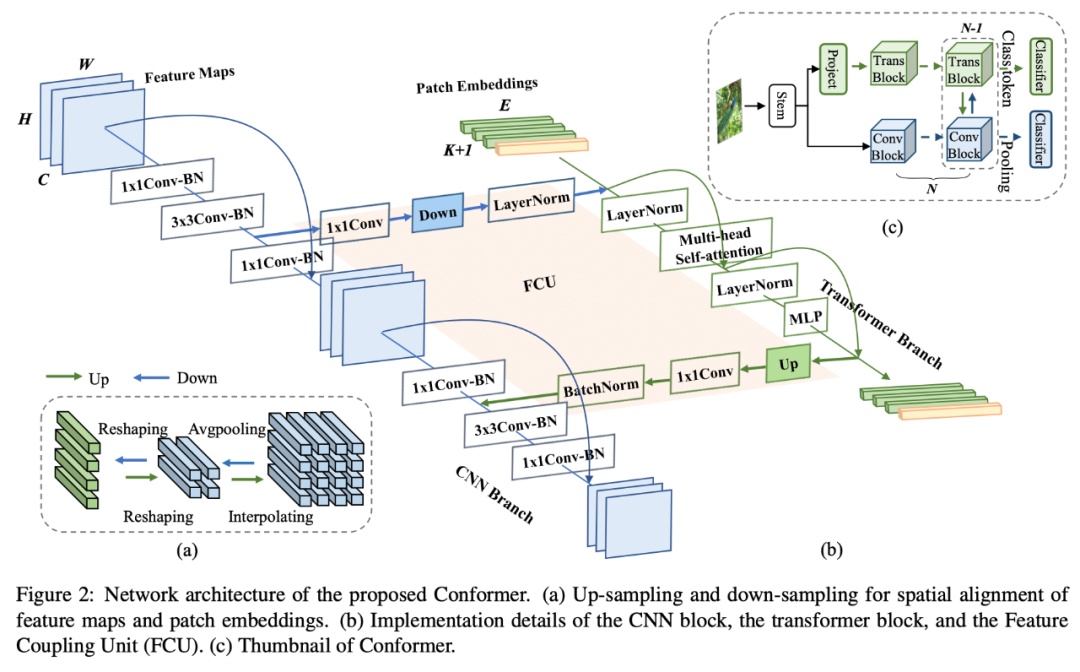
网络结构图
(c)展示了Conformer的缩略图:一个标准的ResNet stem结构,两条并行分支,两个分类器。
(b)展示了每个block中Trans和Conv的连接关系:以2个bottleneck为例,经过第一个bottleneck 3x3卷积后的局部特征经过特征耦合模块(FCU)传给Transformer block。
Transformer block将此局部特征与前一个Trans block的全局特征相加通过当前的trans block,运算结束后再将结果通过FCU模块反传给Conv block。
Conv block的最后一个bottleneck将其与经过1x1卷积后的局部特征相加,一起输入3x3卷积。
之所以将Transformer block夹在两个3x3卷积之间的原因有两个:
- bottleneck中3x3卷积的channel比较少,使得FCU的fc层参数不会很大;
- 3x3卷积具有很强的位置先验信息,保证去掉位置编码后的性能。
实验结果
Conformer网络在ImageNet上做了分类实验,并做为预训练模型在MSCOCO上做了目标检测和实例分割实验。
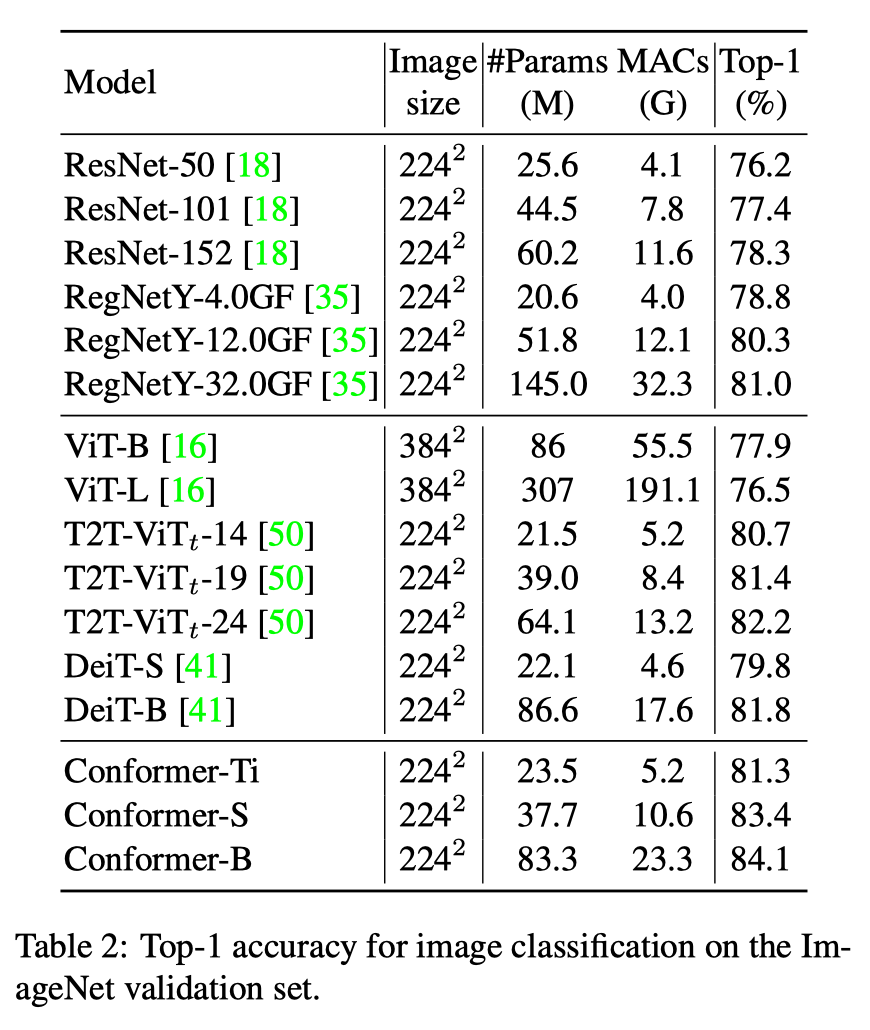
分类准确率对比
参数量为37.7M,计算量为10.6GFlops的Conformer-S超过了参数量为86.6M,计算量为17.6GFlops的DeiT-B 约1.6%的准确率。
当Conformer-S增大参数量到83.3M,准确率则是达到84.1%。
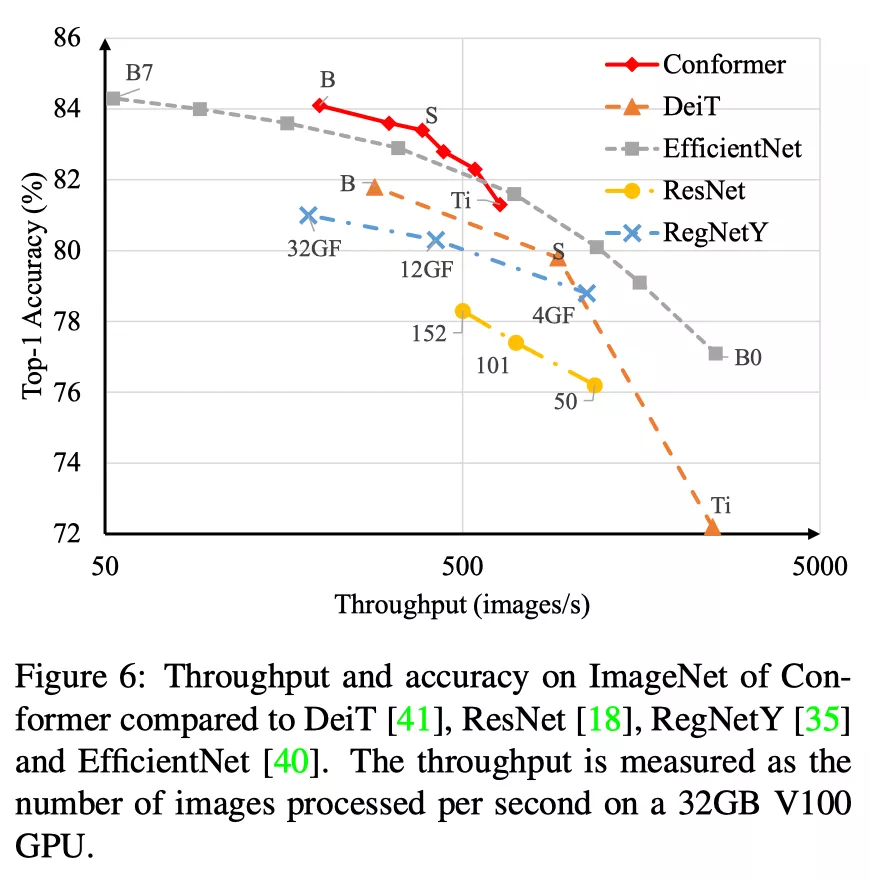
不同基网在分类速度和准确率上的对比:
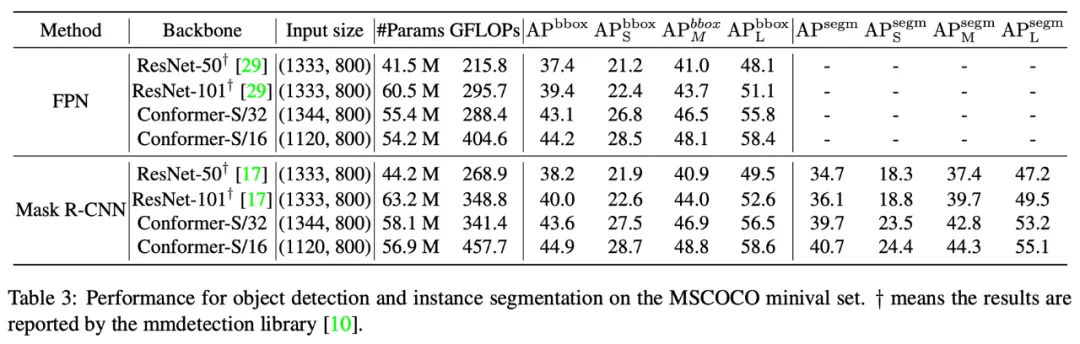
目标检测和实例分割结果的对比
运行帧率为:
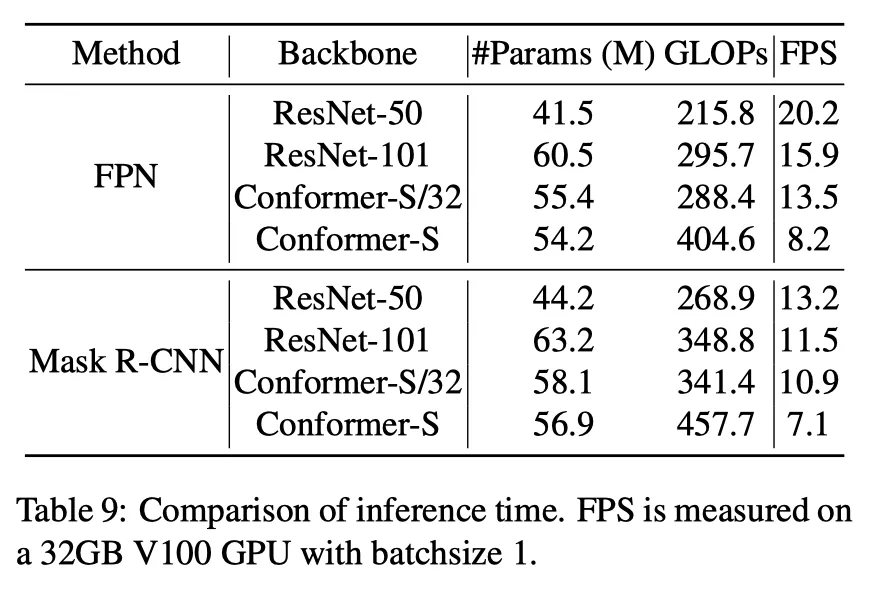
目标检测和实例分割帧率对比
在使用FPN+Faster Mask R-CNN框架时,Conformer-S/32在帧率/参数/计算量可比的情况下,目标检测精度超过Faster RCNN 3.7%,实例分割超过Mask R-CNN 3.6%。
分析总结
Conformer是第一个并行的CNN和Transformer混合网络,通过提出的特征耦合模块FCU在每个阶段的局部特征和全局特征都会进行交互,使得Conformer兼具两者的优势。
在分类上,能够以更小的参数和计算量取得更高的准确率,在目标和实例分割上也能一致地取得大幅度的提升。
目前Conformer只是在ImageNet1K数据集合上训练,其结合更大预训练数据(如ImageNet21K)集合以后将成为一种很有潜力的基网结构。
作者介绍
彭智亮、黄玮,中国科学院大学在读硕士生
顾善植,鹏城实验室工程师
王耀威,鹏城实验室研究员
谢凌曦,华为公司研究员
焦建彬、叶齐祥,中国科学院大学教授