又到了人们喜闻乐见的显卡对决时间。
虽然如今人们用来训练深度学习的 GPU 大多出自英伟达,但它旗下的产品经常会让人在购买时难以抉择。
去年 12 月,英伟达将专业图形加速显卡产品线更新至安培架构,其中最高端的 RTX A6000 是最被人关注的一款。
在基本规格上,A6000 基于完整的 GA102 GPU 核心打造,内建 10752 个 CUDA 核心和第三代 Tensor Core,单精度浮点性能达到了 38.7 TFLOPs。它的显存容量达到 48GB,类型是 GDDR6(16Gbps,GDDR6X 因为单芯片容量低而未使用),支持 ECC 校验。
A6000 采用了传统涡轮直吹风扇设计,可搭建 96GB 显存的双卡系统,PCIe 4.0 x16 插槽,提供 4 个 DP 1.4 接口(没有 HDMI),额定功耗 300W。这款显卡的定价为 5500 美元(约合 3.6 万元)。
而更早推出的旗舰消费级显卡 RTX 3090 无论是从性能还是能效都达到了前代产品的两倍,在开始出售的一段时间因为芯片产能受限等问题而一卡难求。
作为游戏玩家和深度学习从业者眼中目前最强大的显卡,3090 拥有 10496 个 CUDA 核心,FP32 浮点性能为 35.6 TFLOPs。它的显存容量为 24GB,材质也是最贵的 GDDR6X,又因为支持 HDMI 2.1 而可以实现 4k 高刷新率或 8k 游戏,额定功耗 350W。RTX 3090 的售价是 1500 美元(国行公版 11999 元)。
对这两款显卡进行评测的 Lambda 是一家构建深度学习服务器的公司,他们提供专用的 AI 训练计算机,也经常发布深度学习硬件的测评。在这次评测中,人们对这些顶级 GPU 在深度学习框架 PyTorch 上的模型训练速度进行了对比。
A6000 对 3090,这是英伟达两条产品线上最强显卡的对决,身处深度学习实验室的你当然希望知道它们孰优孰劣。不过讲道理,看到这个标题第一反应还是买不起:
听君一席话如同听君一席话,总之还是买不起。
从评测结果上来看,买 RTX A6000 花上三倍的钱并不能让你在深度学习的任务上获得多少优势:
- 使用 PyTorch 训练图像分类卷积神经网络时,在 32-bit 精确度上,一块 RTX A6000 的速度是 RTX 3090 的 0.92 倍;如果使用混合精度则是 1.01 倍。
- 使用 PyTorch 训练语言模型 transformer 时,在 32-bit 精确度上,一块 RTX A6000 的速度是 RTX 3090 的 1.34 倍;使用混合精度也是 1.34 倍。
- 在并联多卡时,使用 PyTorch 训练图像分类卷积神经网络,在 32-bit 精确度上,八块 RTX A6000 的速度是八块 RTX 3090 的 1.13 倍;如果使用混合精度则是 1.14 倍。
- 使用 PyTorch 框架训练语言模型 transformer,在 32-bit 精确度上,八块 RTX A6000 的速度是八块 RTX 3090 的 1.36 倍;如果使用混合精度则是 1.33 倍。
所以,看来如果想在深度学习任务上展现 A6000 的能力,还需要多买几块 GPU。
3090 和 A6000 在 PyTorch 卷积神经网络训练上的能力对比
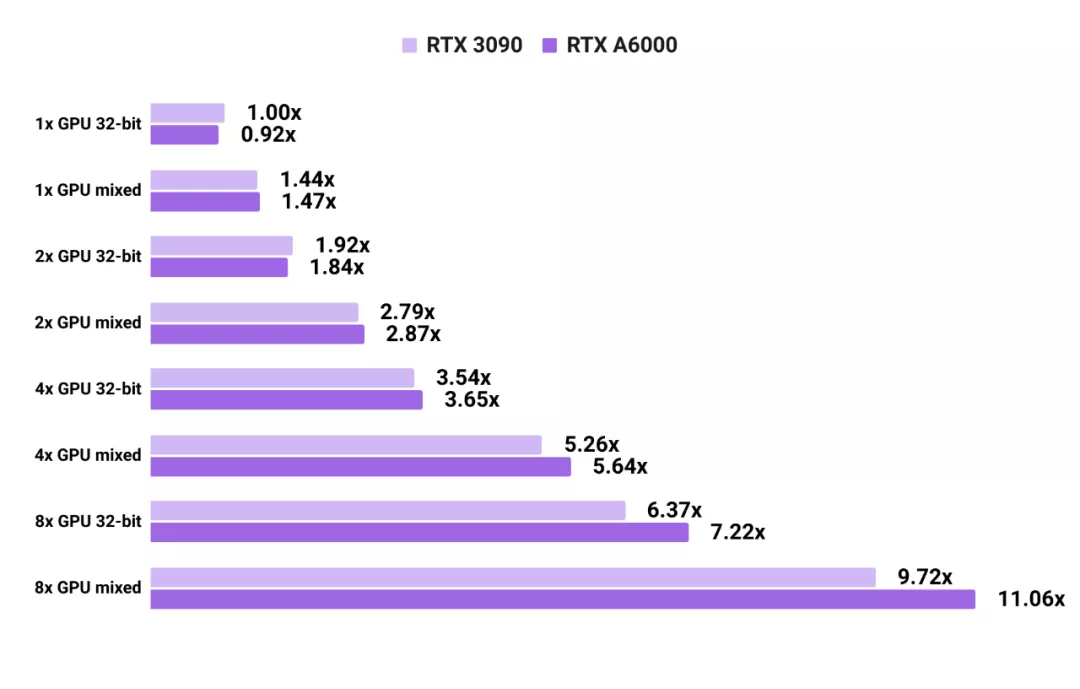
如图所示,使用单块 RTX A6000 进行图像模型的 32 位训练时要比使用单块 RTX 3090 稍慢。但由于 GPU 之间的通信速度更快,显卡越多则 A6000 优势越明显。视觉模型的测试成绩是在 SSD、ResNet-50 和 Mask RCNN 上取平均值得出的。
3090 和 A6000 在 PyTorch 框架上训练语言模型的能力对比
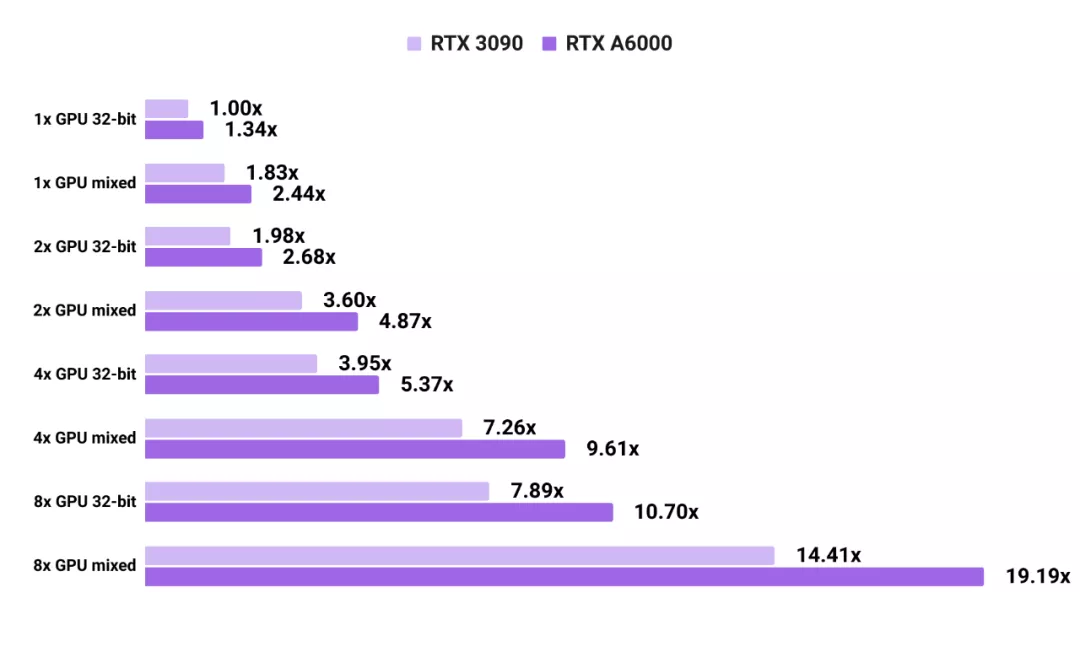
与图像模型不同,对于测试的语言模型,RTX A6000 始终比 RTX 3090 快 1.3 倍以上。这可能是由于语言模型对于显存的需求更高了。与 RTX 3090 相比,RTX A6000 的显存速度更慢,但容量更大。语言模型的测试结果是 Transformer-XL base 和 Transformer-XL large 的平均值。
请注意,在这里 GPU 的并联都使用了 NVLink 而不是 SLI。不过根据硬件本身的机制,如果使用 SLI 性能损失会更大,所以并没有理由使用后者。
Lambda 开放了此次测评的代码:https://github.com/lambdal/deeplearning-benchmark
看到这里,你应该能找到自己的 GPU 选择了。未来,这家公司还将计划使用和本次测试同样的内容,研究 3080Ti 的深度学习能力。