Stream 在 Node.js 中是一个被广泛应用的模块,流的两端可读流、可写流之间通过管道链接,通常写入磁盘速度是低于读取磁盘速度的,这样管道的两端就会产生压力差,就需要一种平衡的机制,使得平滑顺畅的从一个端流向另一个端。
背压是一个术语,表示向流中写入数据的速度超过了它所能处理的最大能力限制。例如,基于 Stream 写一个文件时,当写入端处理不过来时,会通知到读取端,你可以先等等,我这里忙不过来了...,等到一定时机后再次读取写入。
问题来源
“数据是以流的形式从可读流流向可写流的,不会全部读入内存,我想说的是上游流速过快下游来不及消费造成数据积压 即“背压” 问题会怎样” 这个问题来自于「Nodejs技术栈-交流群」一位朋友的疑问,当时没有给出答案,没有做过类似的实际数据测试,出现这种情况一般都会导致数据流两端不平衡,另一端数据不断积压,持续消耗系统内存,其它服务也必然受到影响。
本文,通过修改编译 Node.js 源码,在禁用掉 “背压” 之后,做了一些测试,可以明显看到两者之间的一个效果对比。
流数据读取->写入示例
先构造一个大文件,我在本地创建了一个 2.2GB 大小的文件,通过大文件能够显著看到处理积压与不处理积压之间的差别。
下面例子实现的功能是读取文件、经过 gzip 压缩处理之后写入到一个新的目标文件,也可写成 readable.pipe(gzip).pipe(writable) 不过这样没有任何的错误处理机制,可借助一些工具 https://github.com/mafintosh/pump 处理。
对于处理这样的任务,Stream 模块还提供了一个实用的方法 pipeline,管道中可以处理不同的数据流,当其中某个数据流发生错误,它会自动处理并释放掉相应的资源。
- // stream-back-pressure-test.js
- const gzip = require('zlib').createGzip();
- const fs = require('fs');
- const { pipeline } = require('stream/promises');
- const readable = fs.createReadStream('2.2GB-file.zip');
- const writable = fs.createWriteStream('2.2GB-file.zip.gz');
- (async () => {
- try {
- await pipeline(
- readable,
- gzip,
- writable
- );
- console.log('Pipeline succeeded.');
- } catch (err) {
- console.error('Pipeline failed.', err);
- }
- })();
write() 源码修改与编译
write(chunk) 方法介绍
可写流对象的 write(chunk) 方法接收一些数据写入流,当内部缓冲区小于创建可写流对象时配置的 highWaterMark 则返回 true,否则返回 false 表示内部缓冲区已满或溢出,此时就是背压的一种表现。
向流写入数据的速度已超出了其能处理的能力,若此时还是不断调用 write() 方法,可以想象内部的缓冲区也会不断增加,当前进程占用的系统内存就会不断增加。
当使用 pipe() 或 pipeline 在内部处理时,还是调用的 stream.write(chunk) 方法。
- stream.write(chunk)
如果要测试数据积压带来的一些消耗问题,我们需要修改 Node.js 源码,将 stream.write(chunk) 方法的返回值改为 true 禁止积压处理。
源码修改
我直接拉取的 Master 代码,刚开始忘记切换 Node.js 版本...,各版本大同小异,大致差不多,主要是找到 Writable.prototype.write() 方法,该方法最终的返回值是一个布尔值,找到 return ret && !state.errored && !state.destroyed 直接改为 return true; 禁用掉背压处理。
- // https://github.com/nodejs/node/blob/master/lib/internal/streams/writable.js#L334
- Writable.prototype.write = function(chunk, encoding, cb) {
- return _write(this, chunk, encoding, cb) === true;
- };
- // https://github.com/nodejs/node/blob/master/lib/internal/streams/writable.js#L396
- // If we're already writing something, then just put this
- // in the queue, and wait our turn. Otherwise, call _write
- // If we return false, then we need a drain event, so set that flag.
- function writeOrBuffer(stream, state, chunk, encoding, callback) {
- ...
- // stream._write resets state.length
- const ret = state.length < state.highWaterMark;
- ...
- // Return false if errored or destroyed in order to break
- // any synchronous while(stream.write(data)) loops.
- // return ret && !state.errored && !state.destroyed;
- return true;
- }
编译
源码编译对电脑的环境有一些要求,参考 Node.js 给出的这份文档 Building Node.js。
先执行 ./configure 生成当前环境编译需要的默认配置,然后执行 make 命令编译,第一次编译时间有点略长,差不多够吃个饭了...
- $ ./configure
- $ make -j4
之后每次修改后也还需要重新编译,为了方便起见,在当前目录下创建一个 shell 脚本文件。
- 创建脚本文件 vim compile.sh 输入以下内容。
- 使脚本具有可执行权限 chmod +x ./test.sh。
- 运行脚本编译 sh compile.sh。
- #!/bin/bash
- ./configure --debug
- make -j4
- echo "Compiled successfully"
编译成功后,最后几行日志输出如下所示,当前目录下会生成一个 node 的可执行命令,或者 out/Release/node 也可执行。
- if [ ! -r node ] || [ ! -L node ]; then \
- ln -fs out/Release/node node; fi
现在可以在当前目录下创建一个测试文件,用刚刚编译好的 node 运行。
- ./node ./test.js
内存消耗测试
再推荐一个 Linux 命令 /usr/bin/time,能够测量命令的使用时间并给出系统资源的消耗情况。可以参考这篇文章介绍 http://c.biancheng.net/linux/time.html。
没有处理积压的测试结果
运行命令 sudo /usr/bin/time -lp ./node ./stream-back-pressure-test.js 测试没有积压处理的情况。
980713472 是执行程序所占用内存的最大值,大约消耗 0.9GB。
- real 188.25
- user 179.72
- sys 28.77
- 980713472 maximum resident set size
- 0 average shared memory size
- 0 average unshared data size
- 0 average unshared stack size
- 3348430 page reclaims
- 3864 page faults
- 0 swaps
- 0 block input operations
- 3 block output operations
- 0 messages sent
- 0 messages received
- 0 signals received
- 21341 voluntary context switches
- 2934500 involuntary context switches
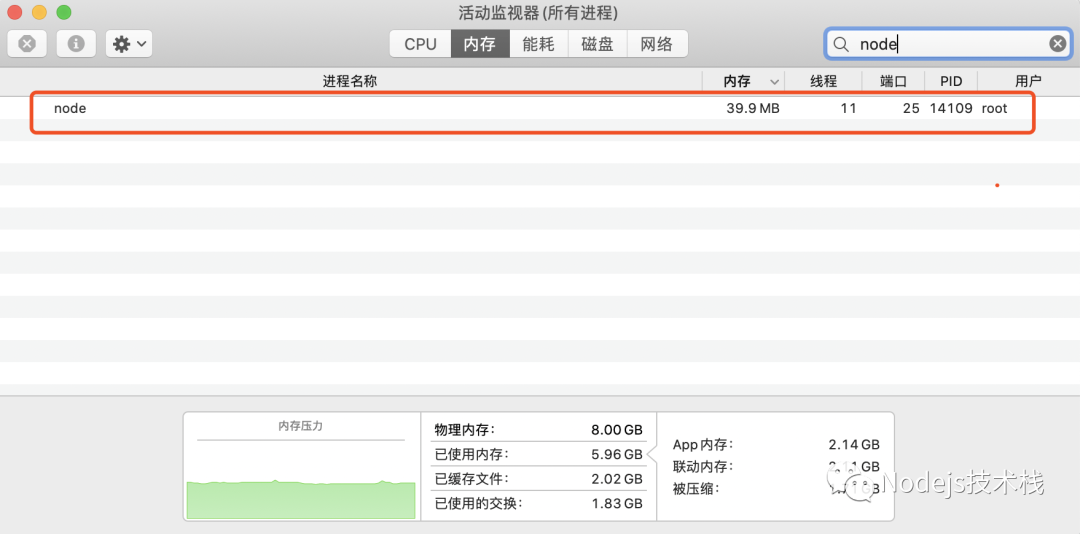
如果是 Mac 电脑,同时打开活动监视器也能看到程序处理过程中的一些内存消耗信息,可以看到内存的占用还是很高的,另外我的电脑上的其它服务也受到了影响,一些应用变得异常卡顿。
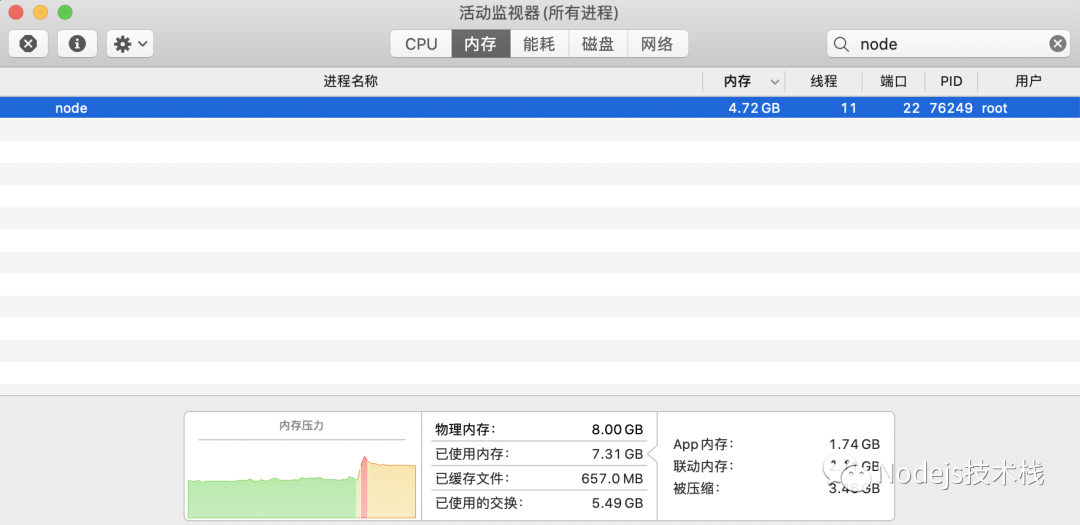
image.png
正常程序积压处理的测试结果
59215872 是执行程序所占用内存的最大值,大约消耗 56 MB。
- real 184.67
- user 176.22
- sys 20.68
- 59215872 maximum resident set size
- 0 average shared memory size
- 0 average unshared data size
- 0 average unshared stack size
- 1486628 page reclaims
- 3971 page faults
- 0 swaps
- 0 block input operations
- 0 block output operations
- 0 messages sent
- 0 messages received
- 1 signals received
- 4843 voluntary context switches
- 2551476 involuntary context switches
通过 Mac 活动监视器看到内存的占用,是没什么压力的,电脑上其它服务此时也没受到影响。
为什么背压我没听说过?
经过上面的测试,可以看到没有正确处理积压的结果和正常的经过处理的存在极大的差别,但是你可能又有疑问:“为什么我没有听说过背压?也没遇到过类似问题?”。
这是因为 Node.js 的 Stream 模块提供的一些方法 pipe()、pipeline() 已经为我们做了这些处理,使用了这些 API 方法我们是不需要自己考虑去处理 “背压” 这一问题的**。因为一旦缓冲区中的数据超过了 highWaterMark 限制,可写流的 write() 方法就会返回 false,处理数据积压的这一机制也会被触发。
如果你直接使用的 write() 方法写入数据,而没有正确的处理背压,就要小心了,如果有攻击者多次发起请求,也会导致你的进程不断的消耗服务器系统内存,从而会拖垮服务器上的其它应用。
总结
可写流在消费数据时,内部有一个缓冲区,一旦缓冲区的数据满了之后,也没做任何 “背压” 处理,会导致缓冲区数据溢出,后面来不及消费的数据不得不驻留在内存中,直到程序处理完毕,才会被清除。整个数据积压的过程中当前进程会不断的消耗系统内存,对其它进程任务也会产生很大的影响。
最后,留一个问题:“如何用 Node.js 实现从可读流到可写流的数据复制?类似于 pipe()”,实现过程要考虑 “背压” 处理,最好是基于 Promise 方便之后使用 Async/Await 来使用,做一点提示可以考虑结合异步迭代器实现,欢迎在留言讨论,下一节揭晓这个问题。
本文转载自微信公众号「Nodejs技术栈」,可以通过以下二维码关注。转载本文请联系Nodejs技术栈公众号。