













你好,我是强壮的病猫,在这里分享面经。这不,最近又面了一家公司,又是被虐,有几道题猫哥一时语塞,今天分享给你,以后碰到这类问题时可以试试反虐。
首先,得说下,无论哪一次面试,猫哥必然会被问到两个问题:
2-5 分钟的自我介绍。如果是外企或跨国企业或大厂,如果你能用英文流畅的自我介绍,必然是加分项,朋友们,离开校园后,英语的学习可别放弃。
你印象最深刻的一次问题解决经历,或者说你最有成就感的一次经历。这个通过你的描述,看看你对技术的兴趣,看看你解决问题的方法论,当然还有口语表达能力。
这两个问题还没有哪次面试不遇到的,要面试的同学,可要好好准备,多排练下,人生如戏,全靠演技。
然后,说下这次遇到的几个问题:
1. uWSGI 生产环境的配置有两种方式一种是 socket,一种是 http,两种方式有什么区别?为什么你用 socket 而不用 http?
我当时直接说这个不太清楚为什么 socket 更好。一脸懵逼,懊恼自己当时只顾着这样用却不多想一下为什么要这样用。
参考回答:
通常情况下,Nginx 与 uWSGI 一起工作,Nginx 处理静态文件,将动态的接口请求转发给 uWSGI。这就是涉及 Nginx 与 uWSGI 以何种协议进行通信,Nginx 的 uwsgi_pass 选项告诉它使用特殊的 uWSGI 协议,而这种协议就是 uWSGI 的套接字使用的默认协议。
uwsgi.ini 示例:
- [uwsgi]
- master = true
- chdir= /root/KeJiTuan/rearEnd
- socket = :8000
- #http = :8000
- socket = %(chdir)/uwsgi.socket
- wsgi-file = rearEnd/wsgi.py
- processes = 1
- threads = 4
- virtualenv = /root/KeJiTuan/env
- static-map = /static=/root/KeJiTuan/frontEnd/dist/static
- stats = %(chdir)/uwsgi.status
- pidfile = %(chdir)/uwsgi.pid
- daemonize = %(chdir)/uwsgi.log%
如果你使用 http 选项配置 uWSGI,这样 uWSGI 本身就可以对外提供 http 服务,不会做任何有用的事情,这样的话,就需要将 NGINX 配置为使用 HTTP 与 uWSGI 对话,并且 NGINX 将不得不重写标头以表示它正在代理,并且最终会做更多的工作,因此性能不如 socket 方式。
也就是说,配置为 socket 其实用的就是 TCP 协议,配置为 http 用的就是 HTTP 协议,TCP 是传输层协议,更底层,程序处理的报文更小,性能更快,而 HTTP 是建立在 TCP 之上的应用层协议,需要处理更多的报文封装与解码。
因此生产环境 uWSGI 首选 socket 配置。
2. redis 是单线程,是怎么解决高并发问题的?
这个我当时是这样回答的:单线程想高并发,就是用到了类似 nginx 的事件循环之类的技术。
参考回答:
redis 是基于内存的,内存的读写速度非常快(纯内存); 数据存在内存中,数据结构用 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1)。
redis是单线程的,省去了很多上下文切换线程的时间(避免线程切换的资源消耗)。
redis 使用 I/O 多路复用技术,可以处理高并发的连接(非阻塞I/O)。(如果你懂 I/O 多路复用,可以展开讲一讲,展示你钻研的深度)
写到这里,猫哥自己也产生了疑问,什么是事件循环,什么是 I/O 多路复用,两者有什么关系?于是找了找学习资料,整理如下,如有反对意见,请文末留言讨论。
事件循环是一种编程范式,通常,我们写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;(2)每收到一个请求,创建一个新的线程,来处理该请求;(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞 I/O 方式来处理请求;
第三种,就是事件驱动的方式,比如 Python 中的 协程就是事件循环,也大多数网络服务器采用的方式比如 Nginx。
比如说 javascript 吧,一大特点就是单线程,那为什你没有觉得浏览器中的 javascript 慢呢?肯定没有,对吧,因为 javascript 在处理 DOM 时也用到了事件循环。
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。但是如果任务是计算型任务,CPU 忙不过来,等就等了,如果是 I/O 型任务,主线程完全可以不管 I/O 设备,而是挂起处于等待中的任务,先运行排在后面的任务。等到 I/O 设备返回了结果,把挂起的任务继续执行下去。
也就是说主线程之外,有一个任务队列,只要异步任务(异步 I/O)有了结果,就在任务队列中放置一个事件,主线程中任务执行完就会去任务队列取出有结果的异步任务执行,具体过程如下图所示:
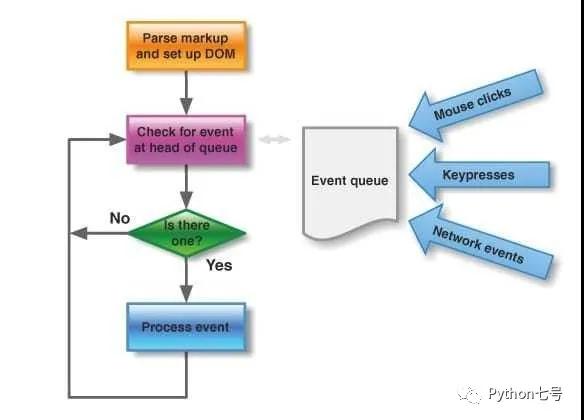
因为整个过程是不断循环的,这种运行机制又称事件循环。到这里,相信你已经对事件循环有一个比较清晰的印象了。
那什么是 I/O 多路复用?这里借用下知乎的高赞回答:
作者:柴小喵 链接:https://www.zhihu.com/question/28594409/answer/52835876 来源:知乎。
下面举一个例子,模拟一个 tcp 服务器处理 30 个客户 socket。假设你是一个老师,让 30 个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:1. 第一种选择:按顺序逐个检查,先检查 A,然后是 B,之后是 C、D。。。这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理 socket,根本不具有并发能力。2. 第二种选择:你创建 30 个分身,每个分身检查一个学生的答案是否正确。这种类似于为每一个用户创建一个进程或者线程处理连接。3. 第三种选择,你站在讲台上等,谁解答完谁举手。这时 C、D 举手,表示他们解答问题完毕,你下去依次检查 C、D 的答案,然后继续回到讲台上等。此时 E、A 又举手,然后去处理 E 和 A。。。这种就是 I/O 复用模型,Linux 下的 select、poll 和 epoll 就是干这个的。将用户 socket 对应的 fd 注册进 epoll,然后 epoll 帮你监听哪些 socket 上有消息到达,这样就避免了大量的无用操作。此时的 socket 应该采用非阻塞模式。这样,整个过程只在调用 select、poll、epoll 这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动。
也就是说 select、poll、epoll 都是 I/O 多路复用的机制,区别如下
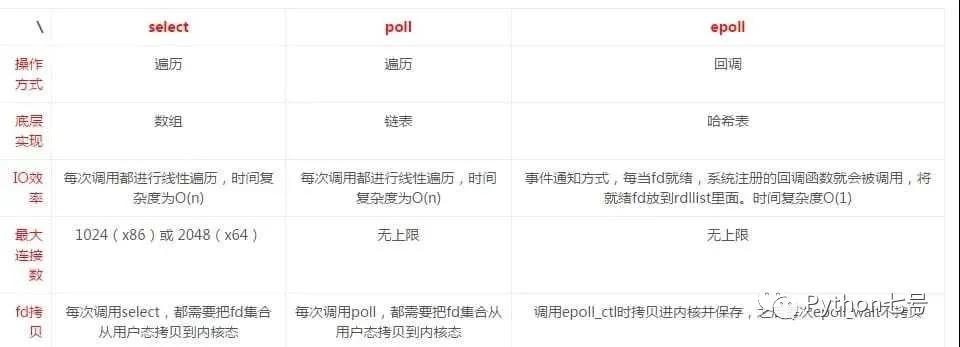
说到这里,你应该明白了,事件循环是一种编程范式,很多场景都可以这样来设计代码,而 I/O 多路复用是一种 I/O 模型,是操作系统提供的一种机制,与进程、线程的概念是等价的,也就是说现代操作系统提供三种并发机制:
- 多进程
- 多线程
- I/O 多路复用
而 I/O 多路复用中的 epoll 用到了事件驱动,使得连接没有上限,提升了并发性能。
3. HTTP 中的 Keep-Alive 起什么作用,是怎么实现的?
参考回答:
HTTP 是建立在 TCP 之上的,每次建立连接,都要经历三次握手,每次断开链接都要四次挥手,建立和断开连接的成本都很高。
Keep-Alive 是一个通用消息头,允许消息发送者暗示连接的状态,还可以用来设置超时时长和最大请求数。
- HTTP/1.1 200 OK
- Connection: keep-alive
- Content-Encoding: gzip
- Content-Type: text/html; charset=utf-8
- Date: Thu, 11 Aug 2016 15:23:13 GMT
- Keep-Alive: timeout=5, max=1000
- Last-Modified: Mon, 25 Jul 2016 04:32:39 GMT
- Server: Apache
Keep-Alive 使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。现在的 Web 服务器,基本上都支持 HTTP Keep-Alive,Keep-Alive 带来以下优势:
- 较少的CPU和内存的使用(由于同时打开的连接的减少了)
- 允许请求和应答的 HTTP 流水线
- 降低拥塞控制 (TCP连接减少了)
- 减少了后续请求的延迟(无需再进行握手)
- 报告错误无需关闭 TCP 连接
劣势:
保持连接会让某些不必要的连接也占用服务器的资源,比如单个文件被不断请求的服务(例如图片存放网站),Keep-Alive 可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
HTTP Keep-Alive 是怎么实现的?
客户端发送 connection:Keep-Alive 头给服务端,且服务端也接受这个Keep-Alive 的话,两边对上暗号,这个连接就可以复用了,一个 HTTP 处理完之后,另外一个 HTTP 数据直接从这个连接走了。
当要断开连接时可以加入 Connection: close 关闭连接,当然也可以设置Keep-Alive 模式的属性,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持 5 秒,max=100,表示这个长连接最多接收 100 次请求就断开。
但是如果开启了 Keep-Alive模式,那么客户端如何知道某一次的响应结束了呢?
以下有两个方法:
如果是静态的响应数据,可以通过判断响应头部中的 Content-Length 字段,判断数据达到这个大小就知道数据传输结束了。
但是返回的数据是动态变化的,服务器不能第一时间知道数据长度,这样就没有 Content-Length 关键字了。这种情况下,服务器是分块传输数据的,Transfer-Encoding:chunk,这时候就要根据传输的数据块 chunk 来判断,数据传输结束的时候,最后的一个数据块 chunk 的长度是 0。
最后的话
面完后,猫哥就把自己回答的不是很好的问题记下来,然后去搜索一番,总结出来希望能帮到你,猫哥后续会不定期分享面试经验,如果有收获,不妨关注、在看、点赞支持一波。
本文转载自微信公众号「Python七号」,可以通过以下二维码关注。转载本文请联系Python七号公众号。






















