在机器学习领域,大家可能对 TensorFlow 和 PyTorch 已经耳熟能详,但除了这两个框架,一些新生力量也不容小觑,它就是谷歌推出的 JAX。很多研究者对其寄予厚望,希望它可以取代 TensorFlow 等众多机器学习框架。
JAX 最初由谷歌大脑团队的 Matt Johnson、Roy Frostig、Dougal Maclaurin 和 Chris Leary 等人发起。
目前,JAX 在 GitHub 上已累积 13.7K 星。
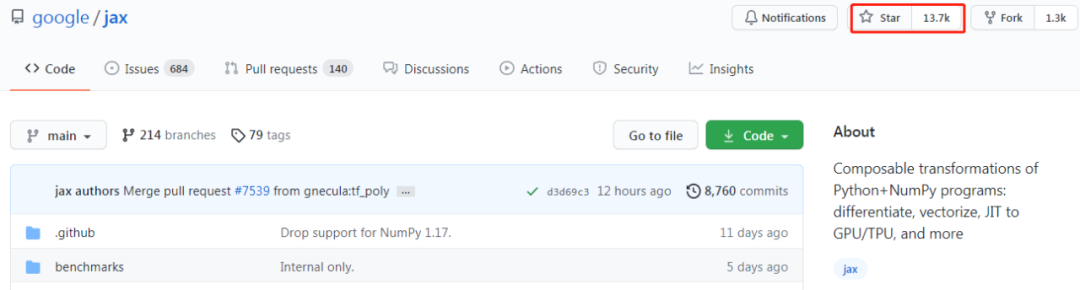
项目地址:https://github.com/google/jax
迅速发展的 JAX
JAX 的前身是 Autograd,其借助 Autograd 的更新版本,并且结合了 XLA,可对 Python 程序与 NumPy 运算执行自动微分,支持循环、分支、递归、闭包函数求导,也可以求三阶导数;依赖于 XLA,JAX 可以在 GPU 和 TPU 上编译和运行 NumPy 程序;通过 grad,可以支持自动模式反向传播和正向传播,且二者可以任意组合成任何顺序。

开发 JAX 的出发点是什么?说到这,就不得不提 NumPy。NumPy 是 Python 中的一个基础数值运算库,被广泛使用。但是 numpy 不支持 GPU 或其他硬件加速器,也没有对反向传播的内置支持,此外,Python 本身的速度限制阻碍了 NumPy 使用,所以少有研究者在生产环境下直接用 numpy 训练或部署深度学习模型。
在此情况下,出现了众多的深度学习框架,如 PyTorch、TensorFlow 等。但是 numpy 具有灵活、调试方便、API 稳定等独特的优势。而 JAX 的主要出发点就是将 numpy 的以上优势与硬件加速结合。
目前,基于 JAX 已有很多优秀的开源项目,如谷歌的神经网络库团队开发了 Haiku,这是一个面向 Jax 的深度学习代码库,通过 Haiku,用户可以在 Jax 上进行面向对象开发;又比如 RLax,这是一个基于 Jax 的强化学习库,用户使用 RLax 就能进行 Q-learning 模型的搭建和训练;此外还包括基于 JAX 的深度学习库 JAXnet,该库一行代码就能定义计算图、可进行 GPU 加速。可以说,在过去几年中,JAX 掀起了深度学习研究的风暴,推动了科学研究迅速发展。
JAX 的安装
如何使用 JAX 呢?首先你需要在 Python 环境或 Google colab 中安装 JAX,使用 pip 进行安装:
- $ pip install --upgrade jax jaxlib
注意,上述安装方式只是支持在 CPU 上运行,如果你想在 GPU 执行程序,首先你需要有 CUDA、cuDNN ,然后运行以下命令(确保将 jaxlib 版本映射到 CUDA 版本):
- $ pip install --upgrade jax jaxlib==0.1.61+cuda110 -f https://storage.googleapis.com/jax-releases/jax_releases.html
现在将 JAX 与 Numpy 一起导入:
- import jax
- import jax.numpy as jnp
- import numpy as np
JAX 的一些特性
使用 grad() 函数自动微分:这对深度学习应用非常有用,这样就可以很容易地运行反向传播,下面为一个简单的二次函数并在点 1.0 上求导的示例:
- from jax import grad
- def f(x):
- return 3*x**2 + 2*x + 5
- def f_prime(x):
- return 6*x +2
- grad(f)(1.0)
- # DeviceArray(8., dtype=float32)
- f_prime(1.0)
- # 8.0
jit(Just in time) :为了利用 XLA 的强大功能,必须将代码编译到 XLA 内核中。这就是 jit 发挥作用的地方。要使用 XLA 和 jit,用户可以使用 jit() 函数或 @jit 注释。
- from jax import jit
- x = np.random.rand(1000,1000)
- y = jnp.array(x)
- def f(x):
- for _ in range(10):
- x = 0.5*x + 0.1* jnp.sin(x)
- return x
- g = jit(f)
- %timeit -n 5 -r 5 f(y).block_until_ready()
- # 5 loops, best of 5: 10.8 ms per loop
- %timeit -n 5 -r 5 g(y).block_until_ready()
- # 5 loops, best of 5: 341 µs per loop
pmap:自动将计算分配到所有当前设备,并处理它们之间的所有通信。JAX 通过 pmap 转换支持大规模的数据并行,从而将单个处理器无法处理的大数据进行处理。要检查可用设备,可以运行 jax.devices():
- from jax import pmap
- def f(x):
- return jnp.sin(x) + x**2
- f(np.arange(4))
- #DeviceArray([0. , 1.841471 , 4.9092975, 9.14112 ], dtype=float32)
- pmap(f)(np.arange(4))
- #ShardedDeviceArray([0. , 1.841471 , 4.9092975, 9.14112 ], dtype=float32)
vmap:是一种函数转换,JAX 通过 vmap 变换提供了自动矢量化算法,大大简化了这种类型的计算,这使得研究人员在处理新算法时无需再去处理批量化的问题。示例如下:
- from jax import vmap
- def f(x):
- return jnp.square(x)
- f(jnp.arange(10))
- #DeviceArray([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81], dtype=int32)
- vmap(f)(jnp.arange(10))
- #DeviceArray([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81], dtype=int32)
TensorFlow vs PyTorch vs Jax
在深度学习领域有几家巨头公司,他们所提出的框架被广大研究者使用。比如谷歌的 TensorFlow、Facebook 的 PyTorch、微软的 CNTK、亚马逊 AWS 的 MXnet 等。
每种框架都有其优缺点,选择的时候需要根据自身需求进行选择。

我们以 Python 中的 3 个主要深度学习框架——TensorFlow、PyTorch 和 Jax 为例进行比较。这些框架虽然不同,但有两个共同点:
- 它们是开源的。这意味着如果库中存在错误,使用者可以在 GitHub 中发布问题(并修复),此外你也可以在库中添加自己的功能;
- 由于全局解释器锁,Python 在内部运行缓慢。所以这些框架使用 C/C++ 作为后端来处理所有的计算和并行过程。
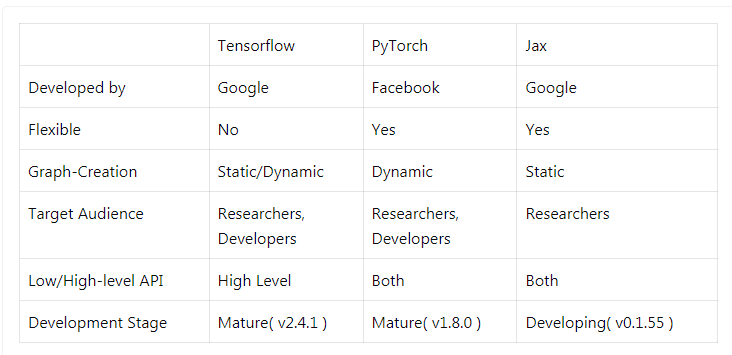
那么它们的不同体现在哪些方面呢?如下表所示,为 TensorFlow、PyTorch、JAX 三个框架的比较。
TensorFlow
TensorFlow 由谷歌开发,最初版本可追溯到 2015 年开源的 TensorFlow0.1,之后发展稳定,拥有强大的用户群体,成为最受欢迎的深度学习框架。但是用户在使用时,也暴露了 TensorFlow 缺点,例如 API 稳定性不足、静态计算图编程复杂等缺陷。因此在 TensorFlow2.0 版本,谷歌将 Keras 纳入进来,成为 tf.keras。
目前 TensorFlow 主要特点包括以下:
- 这是一个非常友好的框架,高级 API-Keras 的可用性使得模型层定义、损失函数和模型创建变得非常容易;
- TensorFlow2.0 带有 Eager Execution(动态图机制),这使得该库更加用户友好,并且是对以前版本的重大升级;
- Keras 这种高级接口有一定的缺点,由于 TensorFlow 抽象了许多底层机制(只是为了方便最终用户),这让研究人员在处理模型方面的自由度更小;
- Tensorflow 提供了 TensorBoard,它实际上是 Tensorflow 可视化工具包。它允许研究者可视化损失函数、模型图、模型分析等。
PyTorch
PyTorch(Python-Torch) 是来自 Facebook 的机器学习库。用 TensorFlow 还是 PyTorch?在一年前,这个问题毫无争议,研究者大部分会选择 TensorFlow。但现在的情况大不一样了,使用 PyTorch 的研究者越来越多。PyTorch 的一些最重要的特性包括:

- 与 TensorFlow 不同,PyTorch 使用动态类型图,这意味着执行图是在运行中创建的。它允许我们随时修改和检查图的内部结构;
- 除了用户友好的高级 API 之外,PyTorch 还包括精心构建的低级 API,允许对机器学习模型进行越来越多的控制。我们可以在训练期间对模型的前向和后向传递进行检查和修改输出。这被证明对于梯度裁剪和神经风格迁移非常有效;
- PyTorch 允许用户扩展代码,可以轻松添加新的损失函数和用户定义的层。PyTorch 的 Autograd 模块实现了深度学习算法中的反向传播求导数,在 Tensor 类上的所有操作, Autograd 都能自动提供微分,简化了手动计算导数的复杂过程;
- PyTorch 对数据并行和 GPU 的使用具有广泛的支持;
- PyTorch 比 TensorFlow 更 Python 化。PyTorch 非常适合 Python 生态系统,它允许使用 Python 类调试器工具来调试 PyTorch 代码。
JAX
JAX 是来自 Google 的一个相对较新的机器学习库。它更像是一个 autograd 库,可以区分原生的 python 和 NumPy 代码。JAX 的一些特性主要包括:
- 正如官方网站所描述的那样,JAX 能够执行 Python+NumPy 程序的可组合转换:向量化、JIT 到 GPU/TPU 等等;
- 与 PyTorch 相比,JAX 最重要的方面是如何计算梯度。在 Torch 中,图是在前向传递期间创建的,梯度在后向传递期间计算, 另一方面,在 JAX 中,计算表示为函数。在函数上使用 grad() 返回一个梯度函数,该函数直接计算给定输入的函数梯度;
- JAX 是一个 autograd 工具,不建议单独使用。有各种基于 JAX 的机器学习库,其中值得注意的是 ObJax、Flax 和 Elegy。由于它们都使用相同的核心并且接口只是 JAX 库的 wrapper,因此可以将它们放在同一个 bracket 下;
- Flax 最初是在 PyTorch 生态系统下开发的,更注重使用的灵活性。另一方面,Elegy 受 Keras 启发。ObJAX 主要是为以研究为导向的目的而设计的,它更注重简单性和可理解性。