大数据时代,数据给人类生产、生活等各方面带来巨大便利的同时,也诱发了很多问题。数据滥用层面,最典型的表现是价格操纵问题,商家利用算法的不透明性及局限性开展“千人千价”“动态定价”“大数据杀熟”等,以不正当方式赚取巨额利润。数据安全层面,个人信息收集乱象丛生,商家利用用户画像技术深度挖掘个人信息,诸多移动互联网应用利用隐私条款的默认勾选、霸王条款获取用户信息,甚至未经授权夺取用户信息。另外,不法分子利用信息系统漏洞和黑客技术盗取个人信息,造成个人信息泄露严重。泄露数据被放在黑市中销售,导致“撞库”攻击频发,进一步加剧了个人信息泄露现象,数据黑产已发展成一条成熟的产业链。这些数据滥用和数据安全问题将成为影响数据价值释放的“绊脚石”。
1. 认同、偏见与从众
大数据时代,网络上的内容呈现出爆炸式的增长趋势,如何从纷繁复杂的网络内容中挑选出自己需要的信息,成为诸多互联网用户的烦恼。起初,搜索引擎的出现缓解了这种问题。但是,搜索引擎往往需要用户知道自己想要获取哪方面的内容,才能通过搜索寻找目标。例如,电影爱好者需要知道自己喜欢哪种类型的电影才能进一步搜索,但问题在于很多时候我们对自己的喜好也不甚了解。此时,数据挖掘算法应运而生。相关算法通过用户的历史数据推送符合用户偏好的内容,并已广泛应用在微博、豆瓣、今日头条等社交和资讯类应用中。数据挖掘算法就像是“通人性”的机器,接收人类已有的数据进行学习,推理和产出内容也是按照人类的思考方式开展,因此输出内容也带有人类的价值观与偏好。
既然数据挖掘算法“通人性”,那么算法很可能也存在人性中认识局限的成份。所以,我们很有必要先从社会心理学的角度,看看人类社会中存在的认同、偏见和从众等认识局限现象。
认同是指个体对比自己地位或成就高的人的肯定,以消除个体在现实生活中因无法获得成功或满足时产生的挫折和焦虑。认同可借由心理上分享他人的成功,为个人带来不易得到的满足感或增强个人的自信。例如,“狐假虎威”“东施效颦”都是认同的例子。认同有时也可能是认同一个组织。例如,一个自幼失学的人加入某学术研究团体,成为该团体的荣誉会员,并且不断向人炫耀他在该团体中的重要性。
偏见是对某一个人或团体所持有的一种不公平、不合理的消极否定的态度,是人们脱离客观事实而建立起来的对人和事物的消极认识。大多数情况下,偏见是根据某些社会群体的成员身份而对其成员形成的一种态度,并且往往是不正确的否定或怀有敌意的态度。例如,人容易根据性别、肤色、宗教信仰等对其他人或团体产生偏见和歧视。
从众是指个人的观念与行为由于群体的引导和压力,不知不觉或不由自主地与多数人保持一致的社会心理现象。通常情况下,多数人的意见往往是对的,服从多数一般不会错,但这会导致个人缺乏分析,不做独立思考,不管是非曲直地一概服从多数,产生一种消极的盲目从众心理。法国社会心理学家古斯塔夫·勒庞的著作《乌合之众:大众心理研究》就是一本研究大众心理学的作品。勒庞在书中阐述了群体以及群体心理的特征,指出当个人是一个孤立的个体时,他有着自己鲜明的个性化特征;但当这个人融入了群体后,他的所有个性都会被这个群体淹没,他的思想立刻就会被群体的思想取代。
2. 只让你看到认同的内容
目前,算法有一个很明显的特点,也是一个局限性,就是只让人们看到认同的内容。以常用的个性化推荐算法为例,个性化推荐算法发挥作用需要两方面的基础,一方面是算法训练数据,另一方面是算法模型设计。从算法训练数据来看,往往需要采集诸多用户的个人偏好数据。例如,对电影、手机、新闻的喜好。从算法模型设计来看,该算法的原理在于根据用户的个人偏好数据寻找兴趣类似的用户,进而做出推荐。以推荐电影为例,通过对比个人偏好数据,可能会发现张三和李四喜欢看同样的几部电影,而且都不喜欢看同样的另外几部电影。由此可以判断,两个用户在电影方面的喜好极为类似。于是,将张三喜欢但李四还未看过的电影推荐给李四,也就实现了个性化推荐。这种推荐算法是基于对用户的协同过滤,如图1所示。它运用了日常生活中“物以类聚,人以群分”的特性,不需要判断目标用户的喜好,重点在于发现目标用户认同的用户群体,然后在喜好类似的群体内部互相开展推荐活动。该算法在学术界和企业界得到了广泛的认可,基于此而加以改进的各类算法层出不穷。
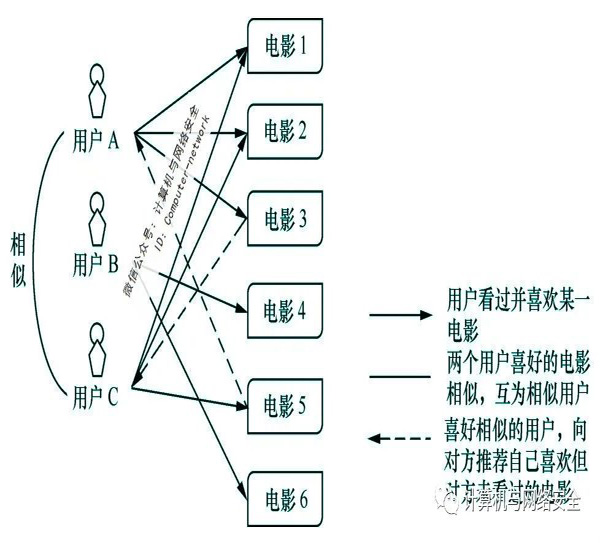
图1 协同过滤算法原理示意图
但是,如果这类个性化推荐持续开展,算法就可能陷入一个怪圈——只让您看到认同的内容。例如,一款为用户推送资讯的App,每天会为用户推送符合其喜好或被其认同的资讯。用户高度关注体育新闻,则最终App推送的新闻会越来越聚焦于体育资讯,无形中会减少用户对社会民生、国家大事等内容的关注。这也就是为什么人们有时候打开社交和资讯类App发现推送的基本都是某一类内容的原因。
从这个意义上讲,尽管个性化推荐算法设计的本意在于帮助用户发掘信息,但同时也会限制用户的眼界和思维,使用户固步自封在自我认同的圈子里。这与人类固有的认同、偏见和从众心理状态及社会属性有关。由于人类的认知有先天的局限性,根据人类思维创造的算法也不可避免地存在局限性。这个问题正逐步被计算机学者和工程师认识,他们为算法的评判增加了多样性指标、新颖性指标和覆盖率指标,即算法的推荐结果不能仅仅集中于某一类内容。不过,目前学术界更看重准确性指标,而企业界在利益驱使下缺乏优化多样性指标、新颖性指标和覆盖率指标的动力。各项指标的简介如表1所示。

表2 个性化推荐算法评价指标简介
有人可能会问,即便如此,这又能对个人和社会产生多大的影响呢?这个影响可不小!因为个性化推荐算法并不仅仅在资讯类App中运用,有些以内容创作为主的行业也正在运用这种算法。网飞(Nexflix)公司创立于1997年,最初主要经营DVD租赁业务。1998年3月,公司上线了全球第一家线上DVD租赁商店,拥有925部电影,几乎是当时所有的DVD电影存量。1999年,公司推出了按月订阅的模式,迅速在行业里建立起口碑。随后,由于DVD机的价格日益便宜,成为普通百姓都能消费得起的产品,其用户量也得到巨幅增长。2005年,公司开始提供在线视频流媒体服务,后来又推出了Netflix Prize算法大赛,出资100万美元奖励开发者为他们的优化电影推荐算法。2012年底,网飞公司已在全球拥有2940万订阅用户。当年,网飞公司开始尝试自制内容,并于2013年推出《纸牌屋》。超高的内容质量和一次放出整季内容的发行方式让它瞬间风靡全球。如今,网飞公司的市值已超越迪士尼,在全球互联网企业中排名前十位。
回顾网飞公司20多年来的快速发展史,个性化推荐起到了举足轻重的作用。以《纸牌屋》为例,网飞公司曾经专门记录过观众在观剧时的相关操作,包括在哪个场景暂停、在什么剧情快进及反复看了哪几分钟等,由此判断剧迷们喜欢的演员、喜闻乐见的情节和对剧情走势的期待,并根据这一系列“情报”指导《纸牌屋》后续剧情的拍摄、演员的选取和台词的撰写。可以说,《纸牌屋》获得的巨大成功正是基于个性化算法推荐和大数据的应用。网飞公司的推荐算法到底有多厉害?根据网飞公司产品创新副总裁卡洛斯·尤瑞贝·戈麦斯(Carlos Uribe-Gomez)和首席产品官尼尔·亨特(Neil Hunt)的一份报告,算法能够为网飞公司每年节省10亿美元。不过,我们也应该看到一个结果,那就是这种完全投观众所好的算法让人们只看到自己喜好或认同的东西,因而会进一步加剧人们认知中的局限性。
3. 公平性缺失愈发严重
随着数据挖掘算法的广泛应用,还出现了另一个突出的问题,即算法输出可能具有不公正性,甚至歧视性。2018年,IG夺冠的喜讯让互联网沸腾。IG战队老板随即在微博抽奖,随机抽取113位用户,给每人发放1万元现金作为奖励。可是抽奖结果令人惊奇,获奖名单包含112名女性获奖者和1名男性获奖者,女性获奖者数量是男性的112倍。然而,官方数据显示,在本次抽奖中,所有参与用户的男女比率是1: 1.2,性别比并不存在悬殊差异。于是,不少网友开始质疑微博的抽奖算法,甚至有用户主动测试抽奖算法,设置获奖人数大于参与人数,发现依然有大量用户无法获奖。这些无法获奖的用户很有可能已经被抽奖算法判断为“机器人”,在未来的任何抽奖活动中都可能没有中奖机会,因而引起网友们纷纷测算自己是否为“垃圾用户”。“微博算法事件”一时闹得满城风雨。
其实,这并非人们第一次质疑算法背后的公正性。近几年,众多科技公司的算法都被检测出带有歧视性:在谷歌搜索中,男性会比女性有更多的机会看到高薪招聘消息;微软公司的人工智能聊天机器人Tay出乎意料地被“教”成了一个集性别歧视、种族歧视等于一身的“不良少女”……这些事件都曾引发人们的广泛关注。即使算法设计者的本意是希望为用户推荐有用信息、对图片进行机器识别、使聊天机器人能够源源不断地学习人类对话的方式,但往往是在算法决策的“黑匣子”面前,人们无法了解算法的决策过程,只能了解最终结果。
为什么大数据算法会出现歧视呢?计算机领域有个缩写词语——GIGO (Garbage in,Garbage Out),大意是“输入的如果是垃圾数据,那么输出的也将会是垃圾数据”。在大数据领域也有类似的说法,《自然》杂志曾用BIBO(Bias In,Bias Out,即“偏见进,偏见出”)表示数据的质量与算法结果准确程度的强关联性。在选择使用什么样的数据时,人们往往容易存在歧视心态,这会直接影响输出的结果。例如,在导航系统最快的路线选择中,系统设计者只考虑到关于道路的信息,而不包含公共交通时刻表或自行车路线,从而使没有车辆的人处于不利状况。另外,可能在收集数据时就缺乏技术严密性和全面性,存在误报、漏报等现象,也会影响结果的精准性。因此,基于数据和算法推断出来的结果会使有些人获得意想不到的优势,而另一些人则处于不公平的劣势——这是一种人们难以接受的不公平。
除了造成不公平性,算法歧视还会不断剥削消费者的个人财富。《经济学家》杂志显示,2014年在排名前100的最受欢迎的网站中,超过1300家企业在追踪消费者。利用算法技术,企业利润获得大幅增加。但是,羊毛出在羊身上,这些利润实际均来自消费者。尤其是随着算法在自动驾驶、犯罪风险评估、疾病预测等领域中越来越广泛和深入的应用,算法歧视甚至会对个体生命构成潜在的威胁。
在国外,算法歧视也备受关注。2014年,美国白宫发布的大数据研究报告就提到算法歧视问题,认为算法歧视可能是无意的,也可能是对弱势群体的蓄意剥削。2016年,美国白宫专门发布《大数据报告:算法系统、机会和公民权利》,重点考察了在信贷、就业、教育和刑事司法领域存在的算法歧视问题,提醒人们要在立法、技术和伦理方面予以补救。对于算法歧视问题,企业界和学术界正在尝试技术和制度层面的解决方案。技术层面,例如,微软程序员亚当·卡莱(Adam Kalai)与波士顿大学的科学家合作研究一种名为“词向量”的技术,目的是分解算法中存在的性别歧视。除了技术层面,制度和规则也至关重要。在人类社会中,人们可以通过诉讼、审查等程序来修正许多不公平的行为和事件。对于算法而言,类似的规则同样必不可少。事后对算法进行审查不是一件容易的事,最好的办法是提前构建相关制度和规则,这应该成为未来社会各界共同努力的方向。