本文转自雷锋网,如需转载请至雷锋网官网申请授权。
如何高效训练大规模数据,一直是机器学习系统面临的重要挑战。
当下互联网时代,数十亿用户每天生产着百亿级规模的数据。作为AI炼丹的底层燃料,这些海量数据至关重要。然而,由于训练数据和模型规模的增大,机器之间的通信成本越高,机器学习系统经常会出现高延迟、低负载的现象。
2004年,谷歌首次提出并行算法 Mapreduce,通过将大规模数据分发给网络上的每个节点,实现了1TB以上的运算量。之后,AI科学家李沐又提出异步可扩展的Parameter Server算法,基本上解决了大规模数据的分布式训练问题。
然而,近年来以 BERT 为代表预训练模型,其体积规模不断突破极限。动辄上百万、甚至上亿级参数量的超大模型,让传统分布式机器学习系统越来越难以高效运转。基于此,业内普遍认为,去中心化(Decentralized )的分布式训练方法将成为下一个“最优解”。
陆昱成向AI科技评论表示,随着机器学习的应用越来越多样化,中心化分布式系统的局限性也会越来越明显,比如“中心节点负载过大”,“容错性差”,“数据安全”等问题。如果设计好节点之间的协议,去中心化算法将有助于大幅提升系统的鲁棒性。
陆昱成是康奈尔大学计算机系在读博士,主要研究大规模机器学习系统,侧重于随机和并行算法。近日,他发表的一篇名为《Optimal Complexity in Decentralized Training》的研究论文获得了ICML 2021杰出论文荣誉提名奖。
在这篇论文中,他主要研究了去中心化算法的理论极限,通过对D-PSGD(罗切斯特大学Ji Liu团队提出)和SGP(Facebook AI Lab提出)等经典算法的系统性分析,推导出了随机非凸环境下迭代复杂度的最优下界,并进一步提出DeTAG算法证明了该理论下界是可实现的。ICML组委会一致认为,这项研究成果推动了分布式机器学习系统在理论层面的发展。
1
去中心化:机器学习系统的最优解
“虽不及热门领域诸如NLP等备受媒体追捧,但在‘炼大模型’这股浪潮的驱动下,去中心化已经成为机器学习系统领域的热门研究方向”。陆昱成表示。
去中心化并不是一个全新的概念,它在金融、移动互联网、云计算等领域早已有了广泛的应用。只是最近五年来才逐渐部署到人工智能领域。例如,应用于金融服务的区块链技术,采用的是去中心化的理念;用于优化计算机网络负载和容量的点对点拓扑结构,依靠的也是去中心化的思想。
在机器学习系统中,中心化是指由一个节点管理所有计算机机器之间的数据交互与同步。而去中心化,则强调所有节点都是平等的,它不围绕任何一个节点做中心化的设计。实验证明,不同节点之间的信息交互也可以达到与集中式交互类似的效果,甚至训练出无损的全局模型。
谷歌于2017年推出的FedAvg算法,是一种典型的去中心化联邦学习架构。它以中心节点为server(服务器),各分支节点为本地的client(设备)。其运算模式是在各分支节点分别利用本地数据训练模型,再将训练好的模型汇合到中心节点,获得一个更好的全局模型。
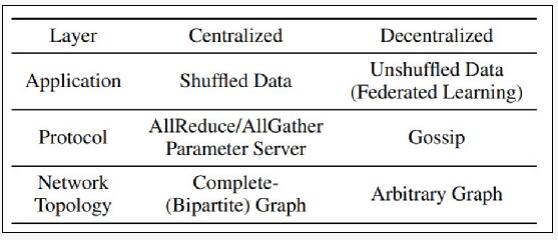
在本地训练移动端数据,而无需用户向外发送信息,是数据层去中心化的一个典型应用。分布式机器学习系统是可以看做一个栈式结构,包括数据、应用、协议、网络拓扑等不同的层。
这些层通过不同的去中心化设计,可以适应不同的应用场景。D-PSGD是扩展随机梯度下降(SGD)最基本算法之一,也是应用于协议层的一种典型去中心化算法,可实现线性并行加速。
虽然学术界已有一些成熟的去中心化算法,但落地工业级别的去中心化系统仍处于初步阶段。传统的机器学习框架诸如Facebook的Pytorch,谷歌的TensorFlow,亚马逊的MXNet仍采用的是Parameter Server或AllReduce等中心化解决方案;但一些初创公司如Openmined等则已将去中心化作为其机器学习系统的一部分。
陆昱成认为,在接下来的几年内,不同层的去中心化设计会成为扩展机器学习/深度学习在不同场景下应用的关键因素。其原因在于三点:
1. 在数据中心和集群式的模型训练中,去中心化的设计提供了良好的容错性和鲁棒性,并减少了不同机器间的带宽需求;
2. 去中心化可以为更多场景下的AI落地提供可能,比如近年来不断发展的终端设备学习就是应用层去中心化的典型设计;
3、去中心化在分布式系统领域有大量关于协议层和安全性的研究,为其在机器学习领域的发展奠定了理论基础。
从现有研究成果来看,陆昱成认为,类似于D-PSGD的众多分布式算法在收敛速度方面仍存在理论差距,尤其是在随机非凸环境下,其迭代复杂度的极限仍是一个未知数。而关于这一问题的探讨,让他获得了ICML 2021杰出论文提名奖,并为机器学习系统的理论发展做出了贡献。
2
理论下界:迭代复杂度的极限

论文地址:https://arxiv.org/abs/2006.08085
在这篇论文中,陆昱成团队提供了去中心化分布式系统的一个最优的理论下界,并通过DeTAG和 DeFacto两个算法证明了该下界是可实现的。
通信复杂度和网络延迟是衡量机器学习模型在训练过程是否高效的重要指标,二者展示了去中心化系统在运算过程中,每个节点的迭代次数和收敛速度,而下界则代表了这种迭代复杂度的理论极限,即在处理任意一个任务时,去中心化系统所需要最低迭代次数。
在陆昱成看来,任何一个最优算法的设计都需要理论下界的指导。“如果没有下界的指导,我们其实并不知道现有算法的提升空间在哪里。只有明确一个极限,不断趋近于极限,才能设计出接近最优的算法”。也因如此,这篇研究论文更注重机器学习系统优化的理论创新。
DeTAG算法是包含应用层、协议层、网络拓扑层的栈式结构。陆昱成介绍称,他们在算法设计过程中使用了一些去中心化的常见技巧,比如梯度追踪,阶段式通信和加速化的Gossip协议。
基于这些技巧,他们最大贡献就是发现了一个最优的理论下界,并且提出了一个可以分析去中心化算法复杂度的理论框架。
实验证明,DeTAG算法只需一个对数间隔即可达到理论下限。在论文中,陆昱成团队将DeTAG与D-PSGD、D2、DSGT以及DeTAG等其他分布式算法在图像分类任务上进行了比较,结果表明,DeTAG比基线算法具有更快的收敛速度,尤其是在异质数据和稀疏网络中。
1、在异质数据上的收敛性
在许多应用场景中,节点间数据往往并不服从同一分布。在实验中,当不同节点间数据完全同质时,除了D-PSGD的收敛速度略慢外,其他算法几乎相差不大;当不同节点数据的同质程度为50%-25%时,DeTAG算法的收敛速度最快,而D-PSGD即使微调的超参数也无法收敛;当数据的同质程度为零时,DSGT获得了比D2更稳定的性能。
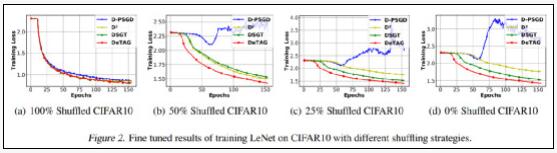
图注:0%、25%、50%、100%代表不同的同质程度
2、在不同稀疏性通信网络上的收敛性
与基线相比,在不同的控制参数(κ=1、0.1、0.05、0.01)下,DeTAG具有更快的收敛速度;此外,当网络变得稀疏,即参数K减小时,DeTAG具有更稳健的收敛性。
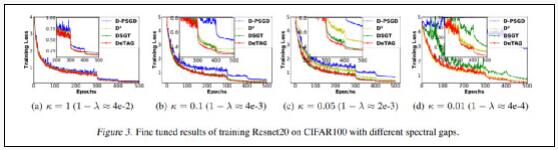
陆昱成表示,DeTAG算法通过优化不同节点之心的通信过程,在一定程度上实现了负载均衡,提高了系统的容错率。同时也验证了去中心化算法在优化分布式机器学习系统方面的潜力——机器学习的范围不再局限于云端,或者大规模集群,而是可以从更广的范围上拟合更多的终端数据。
3
ICML获奖者
陆昱成是康奈尔大学计算机科学系三年级博士生,师从 Chris De Sa.教授。主要研究如何优化分布式机器学习系统,集中于系统性能,通信压缩、去中心化、采样算法等方向。
在博士期间获得顶级学术会议奖项的学生并不多见,尤其是ICML、CVPR、ACL等主流会议。作为机器学习领域的最热门的顶会,ICML 2021共收到有效投稿5513篇,接受1184篇,接受率仅为21.48%。
这次大会颁发了一篇杰出论文奖,四篇杰出论文荣誉提名奖,其中陆昱成(第一作者)是唯一一位获奖的华人博士生。另外一位获奖的华人学者是Facebook AI 科学家田渊栋。
陆昱成本科就读于上海交通大学,后来前往康奈尔大学攻读博士。读博后,他的研究方向开始聚焦于去中心化算法,并接触一些更有挑战性和影响力的课题。在微软和AWS AI Lab 实习期间,他从采样和通信压缩的角度探讨了如何优化分布式训练算法。
通常来讲,博士阶段的研究更适合从小众而具体的选题开始做起,以便培养科研信心,循序渐进为之后的研究积累经验。在谈到为何一开始便选择热门的去中心化算法时,陆昱成表示,从个人角度来讲,第一篇论文从简单易出成果的研究入手,建立自信心是非常必要的,但同时我们也应该有意识地为自己的研究逐级增加难度,扩大问题的主线。
另外,不同于计算机视觉、自然语言处理等研究更偏向工业界,优化算法领域的工作通常更注重基础理论。工业界和学术界要的研究需求是不一样的。除了理论层面外,也可以从非算法角度可以挖掘一些选题。