前言
我们先思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
统计uv的常用方法以及优缺点
其实要是单纯的统计pv是比较好办的,直接用redis的incr就行,但是uv的话,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
set
比较容易想到的是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。没错,这是一个非常简单的方案。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。
hash
hash和set在处理uv的问题上其实类似,把用户id作为hash的key的确可以去重,但是如果访问量大了之后也会消耗很大的内存空间
bitmap
bitmap同样是一种可以统计基数的方法,可以理解为用bit数组存储元素,例如01101001,表示的是[1,2,4,8],bitmap中1的个数就是基数。bitmap也可以轻松合并多个集合,只需要将多个数组进行异或操作就可以了。bitmap相比于Set,Hash也大大节省了内存,我们来粗略计算一下,统计1亿个数据的基数,需要的内存是:100000000/8/1024/1024 ≈ 12M。
虽然bitmap在节省空间方面已经有了不错的表现,但是如果需要统计1000个对象,就需要大约12G的内存,显然这个结果仍然不能令我们满意。在这种情况下,HyperLogLog将会出来拯救我们。
HyperLogLog
这就是本节要引入的一个解决方案,Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。
HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用,但是令人感到意外的是,使用过它的人非常少。
使用方法
Redis 的位数组是自动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
命令
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加计数,一个是获取计数。
具体实现
pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用户 ID 塞进去就是。pfcount 和 scard 用法是一样的,直接获取计数值。关键是它非常省空间,载统计海量uv的时候,只占用了12k的空间
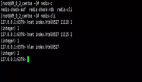
- 127.0.0.1:6379> pfadd codehole user1
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 1
- 127.0.0.1:6379> pfadd codehole user2
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 2
- 127.0.0.1:6379> pfadd codehole user3
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 3
- 127.0.0.1:6379> pfadd codehole user4
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 4
- 127.0.0.1:6379> pfadd codehole user5
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 5
- 127.0.0.1:6379> pfadd codehole user6
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 6
- 127.0.0.1:6379> pfadd codehole user7 user8 user9 user10
- (integer) 1
- 127.0.0.1:6379> pfcount codehole
- (integer) 10
简单试了一下,发现还蛮精确的,一个没多也一个没少。接下来我们使用脚本,往里面灌更多的数据,看看它是否还可以继续精确下去,如果不能精确,差距有多大。
我们将数据增加到 10w 个,看看总量差距有多大。
- public class JedisTest {
- public static void main(String[] args) {
- Jedis jedis = new Jedis();
- for (int i = 0; i < 100000; i++) {
- jedis.pfadd("codehole", "user" + i);
- }
- long total = jedis.pfcount("codehole");
- System.out.printf("%d %d\n", 100000, total);
- jedis.close();
- }
- }
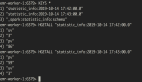
跑了约半分钟,我们看输出:
- > python pftest.py
- 100000 99723
差了 277 个,按百分比是 0.277%,对于上面的 UV 统计需求来说,误差率也不算高。然后我们把上面的脚本再跑一边,也就相当于将数据重复加入一边,查看输出,可以发现,pfcount 的结果没有任何改变,还是 99723,说明它确实具备去重功能。