【51CTO.com快译】Empathy公司平台工程技术负责人Ramiro Alvarez Fernandez对于如何在Kubernetes上使用Spark以摆脱对云计算提供商的依赖,以及在Kubernetes上运行Apache Spark进行了介绍,并分享了这一过程的挑战、架构和解决方案等详细信息。
面临的挑战
对于Empathy公司来说,生产中运行的所有代码都必须与云计算无关。Empathy公司通过使用Spark解决方案克服了之前对云计算提供商提供的解决方案的依赖:例如,EMR(AWS场景)、Dataproc(GCP场景)和HDInsight(Azure场景)。
这些云计算提供商的不同解决方案提供了一种在云上部署Spark的简单方法。但是,当企业在扩大规模时会面临一些限制,从而需要解决以下这些问题:
- 如何编排作业?
- 如何分配Spark作业?
- 如何安排夜间工作?
- 工作代码配置在哪里?
- 如何传播更改?
- 可以重复使用作业定义吗?模板是什么?
- 能否通过代码引用作业?
- 可以从本地主机测试吗?
这些是在实施Spark作业时面临的常见问题。使用Kubernetes解决这些问题可以节省工作人员的时间和精力,并提供更好的体验。
在Kubernetes上运行Apache Spark可以提供以下好处:
- 可扩展性:新解决方案应可扩展以满足任何需求。
- 可靠性:新解决方案应该监控计算节点,并在出现故障时自动终止和替换实例。
- 可迁移性:新解决方案应该可以部署在任何云计算解决方案中,避免对特定云计算提供商的依赖。总体而言,这种方法可以节省考虑与不同云计算服务提供商协调、分发和调度Spark作业的时间。
- 成本效益:企业不需要采用云计算提供商的服务,因此可以节省这些成本。
- 监控:新解决方案应该包括特别监测。
- Kubernetes生态系统:与其他工作负载一样使用通用生态系统,并提供持续部署、RBAC、专用节点池、自动缩放等。
其好处与Empathy公司针对Kubernetes上运行的Apache Flink的解决方案相同。
在Kubernetes运行上的Apache Spark
Apache Spark是用于大数据处理的统一分析引擎,特别适用于分布式处理。Spark用于机器学习,是目前最大的技术趋势之一。
Apache Spark架构
Spark Submit可用于将Spark应用程序直接提交到Kubernetes集群。其流程如下:
(1)Spark Submit从客户端发送到主节点中的Kubernetes API服务器。
(2)Kubernetes将调度一个新的Spark Driver pod。
(3)Spark Driver pod将与Kubernetes通信以请求Spark executor pod。
(4)新的executor pod将由Kubernetes调度。
(5)一旦新的executor pod开始运行,Kubernetes会通知Spark Driver pod新的Spark executor pod已经准备就绪。
(6)Spark Driver pod将在新的Spark executor pod上调度任务。
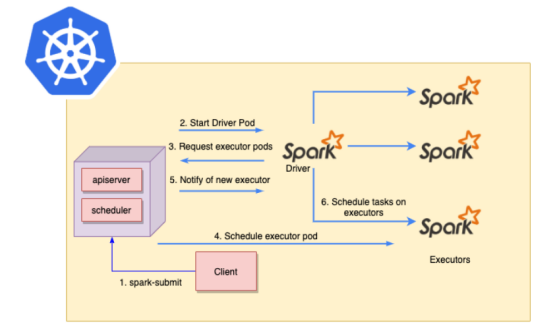
Spark提交流程图
可以使用SparkSubmit(普通方式)或使用Spark Operator来安排Spark应用程序。
Spark Submit
Spark Submit是用于提交Spark应用程序并在Spark集群上启动应用程序的脚本。其具有的一些出色的功能包括:
- Kubernetes版本:不依赖于Kubernetes版本。
- Native Spark:它包含在Spark映像中。
- 非声明性设置:需要计划如何编排作业。
- 定义所需的K8s资源:挂载配置映射、卷、设置反关联、节点选择器等。
- 不需要CRD:不需要Kubernetes自定义资源。
Spark Operator
Spark Operator项目由谷歌公司开发,现在是一个开源项目。它使用Kubernetes自定义资源来指定、运行和显示Spark应用程序的状态。其具有的一些出色的功能包括:
- 声明性:应用程序规范和通过自定义资源管理应用程序。
- 计划重启:可配置的重启策略。
- Kubernetes资源自动定义:支持挂载configmaps和volumes,设置pod关联性等。
- 依赖项注入:直接注入依赖项。
- 指标:支持收集应用程序级指标和驱动程序/执行程序指标并将其导出到Prometheus。
- 开源社区:每个人都可以做出贡献。
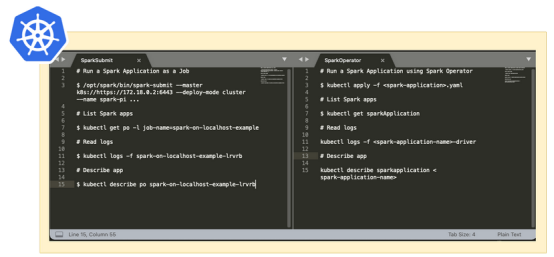
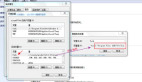
Spark Submit vs Spark Operator的主要命令
上图显示了Spark Submit与Spark Operator的主要命令。
Empathy公司的解决方案更喜欢采用Spark Operator,因为它允许比Spark Submit更快的迭代,在Spark Submit中,必须为每个用例创建自定义Kubernetes清单。
解决方案的详细信息
为了解决挑战部分提出的问题,ArgoCD和Argo Workflows可以提供帮助,同时还有CNCF项目的支持。例如,可以从Kubernete调度最喜欢的Spark应用程序工作负载,以创建Argo Workflows并定义顺序作业。
流程图如下:
- 在git上定义更改。
- ArgoCD将git更改同步到Kubernetes集群(例如,创建一个Argo工作流模板)。
- Argo Workflows模板允许为多个Spark作业自定义输入和重用配置,并基于Argo Workflows创建夜间作业。
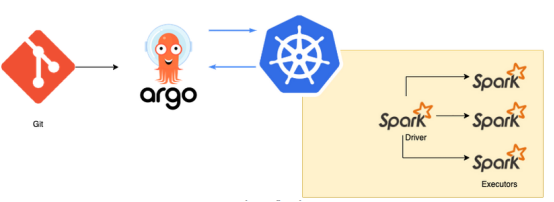
解决方案流程图
ArgoCD
ArgoCD是Kubernetes的GitOps持续交付工具。其主要好处是:
- GitOps:使用git存储库作为定义所需应用程序状态的真实来源。
- 声明式设置:git上的一切。
- 可追溯性和自动化:应用程序部署可以跟踪分支、标签等的更新。应用程序部署将根据特定的目标环境实现自动化。
- WebUI:用于检查部署的工作负载的外观良好的用户界面。
- Kubernetes体现了Kustomize、Helm、ksonnet、jsonnet等。可以进行选择。
更详细的信息可以在其官方文档中找到。
Argo Workflows
Argo Workflows是Kubernetes的工作流解决方案。主要好处是:
- 作业编排:这允许按顺序编排作业或创建自定义DAG。
- 调度工作流:Cron native.。
- Spark应用程序:在任何Kubernetes集群上轻松编排Spark应用程序。
- 工作流模板:针对不同用例重复使用模板。输入可以参数化。
- WebUI:用于检查工作流程进度的出色视觉用户界面。
更详细的信息可以在其官方文档中找到。
监测
一旦Prometheus掌握了这些指标,就需要一些Grafana仪表板进行监测。Apache Spark的自定义Grafana仪表板基于以下社区仪表板:
- ArgoCD仪表板
- Argo Workflow仪表板
- Apache Spark操作员仪表板
- Apache Spark应用程序仪表板
结语
Empathy公司选择Spark Operator、ArgoCD和Argo Workflows在Kubernetes上创建Spark应用程序工作流解决方案,并使用GitOps传播更改。本文所展示的设置已经在生产环境中使用了大约一个月的时间,并且反馈很好。每个用户都对工作流程感到满意,而拥有一个适用于任何云提供商的单一工作流程,可以摆脱了单个云计算提供商的锁定。
如果亲自进行测试,需要按照这些实际操作示例并享受从本地主机部署一些Spark应用程序的乐趣,以及本指南中描述的所有设置:Hands-on Empathy Repo。
虽然还有很长的路要走,但会有更多的收获。希望这一创新能帮助企业变得更加与云无关。
原文标题:Running Apache Spark on Kubernetes,作者:Ramiro Alvarez Fernandez
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】