著名调查机构Aberdeen Group曾经做过一次调查,结果令人乍舌。
整个互联网,网络爬虫产生的流量占比高达37.2%!
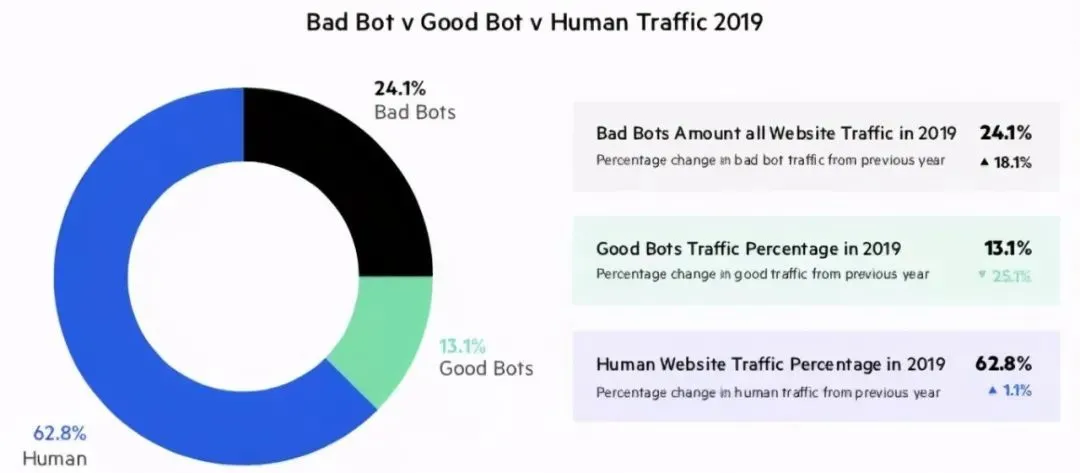
换句话说,每100个互联网用户中,只有63个是实实在在的人类,剩下的流量都是机器人刷出来的。
有一种说法更可怕,未来互联网50%以上的流量将是机器人制造出来的。
在现实世界,人类还在为人工智能威胁而烦恼,但在虚拟世界,机器人所制造的流量,已经可以和人类平分秋色,甚至超过人类。
每时每刻,爬虫们都在模仿人类的上网行为,去各种网站上溜达,点点按钮,查查数据,或者把看到的信息背回来,他们永远不知道疲倦,循环往复。
你一定见过验证码吗,它可能长这样:
也可能这样:
或者是这样子:
无论它长什么样子,验证码只有一个目的,识别真实的人类用户。
打开百度搜索,搜点什么资料,解决点什么问题。无意中,你也成为众多爬虫使用者中的一员。
爬虫,已经遍布在互联网的每一个角落,影响着每一个人。
但是,你了解爬虫的前世今生吗?
善良的一面
1994年,在卡内基梅隆大学参加“信息媒体数字图书馆”项目研究的小马,为了解决这一项目的一些困难,用3页的代码量,开发了一个名为Lycos的搜索引擎。
Lycos是Lycosidae(一种善于捕捉猎物的狼蛛)的缩写。
这个简陋的搜索引擎,让小马看到其背后巨大的商机,于是不久后,Lycos公司正式成立。
短短两年时间,Lycos便成功上市,成为有史以来上市最快的公司。根据Nielsen/NetRatings调查统计机构数据,2002年10月份,Lycos的访问量高达3700万,成为全世界访问量排名第5的网站。
然而,搜索引擎这块大蛋糕,终究逃不过群狼竞食的命运。
1995年,也就是在Lycos诞生一年后,斯坦福大学的两个计算机专业的学生小拉和小谢,开始研究一个叫BackRub的计算机程序。
这个程序是利用反向链接分析来跟踪和记录Internet上的数据的搜索引擎。
他们立志开发一款强大的搜索引擎,供全世界各地的人们使用,更加方便地从互联网上获取信息。
1998年,小拉和小谢拿出自己的全部家当,再加上母校和舍友的一点资金支持,成立一家名为Google的公司。

因为没有充足的资金保障,他们不得不购买二手的计算机零件,在一个车库中办公。
艰难的创业环境,使小拉和小谢一度想卖掉Google,他们邀请了雅虎、Excite以及其他几家硅谷公司,希望他们把Google买了,只可惜当初这些公司只愿意出100万美元的价格,与他们俩的心理预期严重不符,这件事只得作罢。
几乎同一时间,在地球的另一头,有一个年轻的小伙子小马,开发了一款名为QQ的聊天软件,也想把它卖出去,也没有成功。
历史总是惊人的相似。
谁也没想到,这两家名不见经传的小公司,会成为互联网超级巨头。
世界的另一头,在美国呆了8年的小李,看到国内互联网环境已经成熟,他立即起身回国创业,创办一家名为百度的公司。
至此,谷歌、雅虎、百度三分天下的局面逐渐形成。
上古时代,那时的互联网,还是一片贤者云集的净土,为了尊重网站的权利,各大搜索引擎通过邮件形式讨论定下了一个君子协议——robots.txt。
只要在你的网站根目录上放上一个robots文件,告诉搜索引擎哪些内容不能抓取,网络爬虫就会遵守约定,不抓取这些内容。
邪恶的一面
随着互联网的发展, 信息量快速发展,整个网络世界,充满着许多很有价值的信息,商品信息、机票信息、个人隐私数据满天飞。
一些不法分子从中看到了巨大的利益。
在利益的诱惑下,这些人开始违反爬虫协议,编写爬虫程序,恶意爬取目标网站的内容。
历史上第一件关于爬虫的官司出现在2000年,eBay将一家聚合价格信息的网站告上法庭。
eBay认为自己已经使用robot协议,明确告诉哪些信息不能抓取,哪些信息可以抓取,但这家公司违反了协议,非法抓取商品价格等信息。
但被告认为,eBay上的用户数据、以及用户上传的商品信息,应属于用户集体所有,并不属于eBay,robot协议无效。
最终,法院判决eBay胜诉。
这个案件开启了爬虫协议作为主要参考证据的先河。
如今,爬虫技术发展迅速,已经出现通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。抓取目标的方式也很多,例如基于目标网页特征、基于目标数据模式、基于领域概念等。
爬虫技术,无论善意还是恶意,都将常伴在互联网的身边,影响网民的分分秒秒。