本文转载自微信公众号「数仓宝贝库」,作者叶桦 等。转载本文请联系数仓宝贝库公众号。
数据库性能优化最主要的就是SQL优化,SQL优化的关键离不开三点:表的连接方式、访问路径和执行顺序,本文重点介绍几种常见的连接方式。
多表关联查询,查询优化器的执行步骤具体如下。
1)访问路径:查询语句中涉及多个对象,可以基于成本确定每一个对象数据的检索方式,是选择全表扫描还是索引访问等。
2)连接方式:结果集之间的关联方式,主要包括嵌套循环、哈希连接、排序合并连接等。优化器对结果集之间连接方式的判断尤为重要,因为判断结果将会直接影响SQL的执行效率。
3)关联顺序:当关联对象超过2个时,首先选取两个对象关联得到的结果集,再与第三个结果集相关联。
下面我们重点介绍几种常见的连接方式。
01嵌套循环连接
图1所示的是嵌套循环连接示意图。
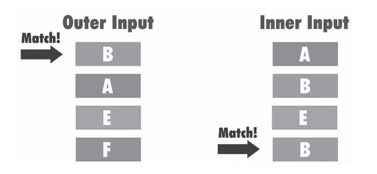
图1 嵌套循环连接示意图
嵌套循环查询流程具体如下。
1)两表关联,优化器首先会确定驱动表,也称外部表(outer table),另一张则是被驱动的表,也称为内部表(inner table)。一般情况下,优化器会把数据量小的定义为驱动表,执行计划中,驱动表在上,被驱动表在下。
2)驱动表确认之后,会从其中提取一行有效数据,在被驱动表(内部表)中查找和匹配有效数据并提取。
3)将数据返回给客户端。
从以上步骤中我们可以看出,驱动表返回的行数直接影响了被驱动表的访问次数,比如,驱动表根据筛选条件最终返回了10行有效数据,每返回一条就会传值给被驱动表进行匹配,驱动表一共需要循环访问10次。示例代码如下:
- SQL> SELECT /*+ USE_NL(e d) */ e.first_name, e.last_name, e.salary, d.department_name
- FROM hr.employees e, hr.departments d
- WHERE d.department_name IN ('Marketing', 'Sales')
- AND e.department_id = d.department_id;
- SQL> select * from table(dbms_xplan.DISPLAY_CURSOR(null, null, 'ALLSTATS LAST'));
- SQL_ID 3nsqhdh150bx5, child number 0
- -------------------------------------
- SELECT /*+ USE_NL(e d) */ e.first_name, e.last_name, e.salary,
- d.department_name FROM hr.employees e, hr.departments d WHERE
- d.department_name IN ('Marketing', 'Sales') AND e.department_id =
- d.department_id
- Plan hash value: 2968905875
- -------------------------------------------------------------------------------------
- | Id | Operation |Name |Starts|E-Rows|A-Rows | A-Time | Buffers |
- -------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | 36 |00:00:00.01 | 23 |
- | 1 | NESTED LOOPS | | 1 | 19 | 36 |00:00:00.01 | 23 |
- |* 2 | TABLE ACCESS FULL|DEPARTMENTS| 1 | 2 | 2 |00:00:00.01 | 8 |
- |* 3 | TABLE ACCESS FULL|EMPLOYEES | 2 | 10 | 36 |00:00:00.01 | 15 |
- -------------------------------------------------------------------------------------
从上述示例代码中我们可以看出,DEPARTMENTS为驱动表,Starts为1,说明只访问1次,返回2行有效数据(A-Rows为实际返回的行数),EMPLOYEES为被驱动表,Starts为2,说明访问2次。
学过C++编程的同学应该记得,C++中的嵌套循环与下面的循环有些类似:
- #include <stdio.h>
- int main ()
- {
- int i, j;
- for(i=1; i<100; i++) {
- for(j=1; j <= 100; j++)
- if(!(i%j)) break;
- if(j > (i/j)) printf("%d \n", i);
- }
- return 0;
- }
j的循环次数取决于i的取值范围,我们可以将i看作驱动表,j看作被驱动表。
- 嵌套循环连接性能主要受限于以下几点。
- 驱动表的返回行数。
- 被驱动表的访问方式:如果被驱动表的连接列基数小且选择性差,会导致全表扫描的访问方式,其效率变得非常低,所以我们建议连接列存在索引,且基数大选择性高。
- 驱动表筛选后将返回少量数据。
- 被驱动表关联字段需要有索引(连接列基数较大或选择性较高)。
- 两表关联后将返回少量数据。
- 适合于OLTP系统。
Tips
如果优化器选择了错误的连接方式,那么我们可以使用提示(hint)强制执行使用嵌套循环的连接方式:“/*+ USE_NL(TABLE1,TABLE2) LEADING(TABLE1) */”,其中TABLE1和TABLE2为关联表的别名,LEADING(TABLE1)用于将TABLE1指定为驱动表。
02哈希连接
图2所示的是哈希连接示意图。
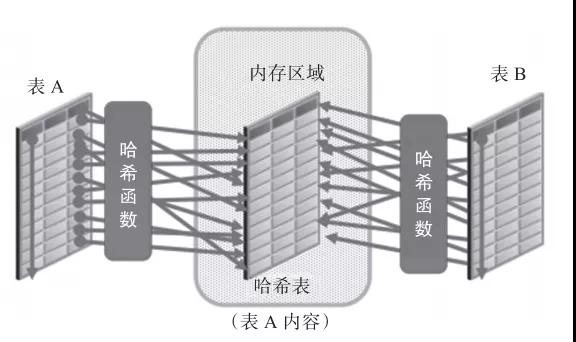
图2 哈希连接示意图
嵌套循环连接适用于两表关联后将返回少量数据的情况,那么返回大量数据时该采用哪种连接方式呢?答案是采用哈希连接。
哈希连接的查询流程具体如下。
1)两表等值关联。
2)优化器将数据量小的表作为驱动表,在PGA的SQL 工作区域(work areas)中,将驱动表的连接列构建成一张哈希表。
3)读取大表,对连接列进行哈希运算(检查哈希表,以查找连接的行)。
4)将数据返回给客户端。
从以上步骤中我们可以看出,通过哈希值进行匹配的方式,更适用于两表等值关联。示例代码如下:
- SQL> SELECT /*+ USE_HASH(o l) */o.customer_id, l.unit_price * l.quantity
- 2 FROM oe.orders o, oe.order_items l
- 3 WHERE l.order_id = o.order_id;
- SQL> select * from table(dbms_xplan.DISPLAY_CURSOR(null, null, 'ALLSTATS LAST'));
- SQL_ID cu980xxpu0mmq, child number 0
- -------------------------------------
- SELECT /*+ USE_HASH(o l) */o.customer_id, l.unit_price * l.quantity
- FROM oe.orders o, oe.order_items l WHERE l.order_id = o.order_id
- Plan hash value: 864676608
- -------------------------------------------------------------------------------------------------------------
- | Id | Operation |Name |Starts|E-Rows|A-Rows|A-Time |Buffers|Reads|OMem |1Mem |Used-Mem|
- -------------------------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | 665 |00:00:00.04 | 57 | 5 | | | |
- |* 1 | HASH JOIN | | 1 | 665 | 665 |00:00:00.04 | 57 | 5 |1888K|1888K|1531K (0)|
- | 2 | TABLE ACCESS FULL|ORDERS | 1 | 105 | 105 |00:00:00.04 | 6 | 5 | | | |
- | 3 | TABLE ACCESS FULL|ORDER_ITEMS| 1 | 665 | 665 |00:00:00.01 | 51 | 0 | | | |
- -------------------------------------------------------------------------------------------------------------
从上述示例代码中我们可以看出,ORDERS为驱动表,Starts为1,说明访问1次,返回105行有效数据(A-Rows为实际返回的行数),ORDER_ITEMS为被驱动表,Starts也为1,说明仅访问1次。其中,OMem、1Mem为执行所需的PGA评估值,Used-Mem为实际执行时PGA中SQL工作区域消耗的内存(即发生磁盘交换的次数),当驱动表较大,PGA的SQL 工作区域无法完全容纳时,就会溢出到临时表空间产生磁盘交互,进而影响性能。
哈希连接性能主要受限于以下两点。
- 等值连接。
- PGA SQL工作区域较小,且驱动表为大表时,容易出现性能问题。
当同时满足以下条件时,哈希连接方式将会非常有用。
- 两表等值关联后返回大量数据。
- 不同于嵌套循环连接,哈希连接被驱动表的连接字段时不需要有索引。
Tips
同样,我们也可以使用提示强制执行使用哈希连接的方式:“/*+ USE_HASH (TABLE1,TABLE2) LEADING(TABLE1) */”。
03排序合并连接
图3所示的是排序合并连接示意图。

图3 排序合并连接示意图
哈希连接适用于两表等值关联后返回大量数据的情况,那么非等值关联返回大量数据的情况又该采用哪种连接方式呢?答案是排序合并连接。
同时满足以下条件时,排序合并连接的性能要比哈希连接得好。
- 两表非等值关联(>、>=、<、<=、<>)。
- 数据源自身有序。
- 不必额外执行排序操作。
排序合并连接方式中没有驱动表的概念,连接查询流程具体如下。
1)两表根据关联列各自排序。
2)在内存中进行合并处理。
从以上实现步骤中我们可以看出,由于匹配的对象是连接列各自排序后的值,因此排序合并连接方式更适用于两表非等值关联的情形,示例代码如下:
- SQL> SELECT o.customer_id, l.unit_price * l.quantity
- FROM oe.orders o, oe.order_items l
- WHERE l.order_id > o.order_id;
- 32233 rows selected..
- SQL> select * from table(dbms_xplan.DISPLAY_CURSOR(null, null, 'ALLSTATS LAST'));
- SQL_ID ajyppymnhwfyf, child number 1
- -------------------------------------
- SELECT o.customer_id, l.unit_price * l.quantity FROM oe.orders o,
- oe.order_items l WHERE l.order_id > o.order_id
- Plan hash value: 2696431709
- -----------------------------------------------------------------------------------------------------------
- | Id | Operation |Name |Starts| E-Rows | A-Rows | A-Time |Buffers|OMem |1Mem | Used-Mem |
- -----------------------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | 32233 |00:00:00.10 | 21 | | | |
- | 1 | MERGE JOIN | | 1 | 3 4580 | 32233 |00:00:00.10 | 21 | | | |
- | 2 | SORT JOIN | | 1 | 105 | 105 |00:00:00.01 | 4 |11264|11264|10240 (0)|
- | 3 | TABLE ACCESS FULL |ORDERS | 1 | 105 | 105 |00:00:00.01 | 4 | | | |
- |* 4 | SORT JOIN | | 105 | 665 | 32233 |00:00:00.05 | 17 |59392|59392|53248 (0)|
- | 5 | TABLE ACCESS FULL |ORDER_ITEMS| 1 | 665 | 665 |00:00:00.01 | 17 | | | |
- ------------------------------------------------------------------------------------------------------------
从上述示例所示的执行计划中我们可以看出,ID=3的ORDERS表Starts为1,说明访问1次,返回105行有效数据(A-Rows为实际返回行数),ORDER_ITEMS表的Starts为1,说明也只访问1次,但ID=4的SORT JOIN表Starts为105,说明在内存中进行了105次匹配。其中,OMem、1Mem为执行排序操作所需的PGA评估值,Used-Mem为实际执行时PGA中SQL工作区域消耗的内存(即发生磁盘交换的次数)。
从以上步骤中我们可以看出,由于比较对象是两张表的连接列order_id,所以需要各自的连接列先完成排序(ID=2和ID=4),之后再进行匹配。如果此时连接列上存在索引,那么索引返回的数据就是有序的,此时不需要再进行额外的排序操作。
Tips
同样,我们也可以使用提示强制执行选择排序合并连接的方式:“/*+ USE_MERGE(TABLE1,TABLE2) */”。
04笛卡尔连接
当一个或多个表连接没有任何连接条件时,数据库将使用笛卡儿连接。优化器将一个数据源的每一行与另一个数据源的每一行连接在一起,以创建两组数据集的笛卡儿积。示例代码如下:
- SQL> SELECT o.customer_id, l.unit_price * l.quantity
- FROM oe.orders o, oe.order_items l;
- 69825 rows selected.
- SQL> select * from table(dbms_xplan.DISPLAY_CURSOR(null, null, 'ALLSTATS LAST'));
- SQL_ID d3xygy88uqzny, child number 0
- -------------------------------------
- SELECT o.customer_id, l.unit_price * l.quantity FROM oe.orders o,
- oe.order_items l
- Plan hash value: 2616129901
- -----------------------------------------------------------------------------------------------
- | Id | Operation | Name |Starts | E-Rows | Buffers | OMem | 1Mem | Used-Mem |
- -----------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | 125 | | | |
- | 1 | MERGE JOIN CARTESIAN| | 1 | 69825 | 125 | | | |
- | 2 | TABLE ACCESS FULL |ORDERS | 1 | 105 | 108 | | | |
- | 3 | BUFFER SORT | | 105 | 665 | 17 | 27648 | 27648 |24576 (0)|
- | 4 | TABLE ACCESS FULL |ORDER_ITEMS| 1 | 665 | 17 | | | |
- -----------------------------------------------------------------------------------------------
从以上执行计划中我们可以看出,先对表order_items进行排序,然后进行两表的笛卡儿乘积操作,由于没有过滤条件,当数据量很大的时候,返回的行数将会非常多,因此若无特殊情况,不建议使用没有任何连接条件的查询。
本文摘编于《DBA攻坚指南:左手Oracle,右手MySQL》,经出版方授权发布。