













【51CTO.com快译】数据集成,通常在企业的信息架构中扮演着重要的角色。具体而言,企业的分析流程在很大程度上会依赖于此类集成模式,以便从交易系统中,提取方便分析与加载的数据格式。
过去,在传统的架构范式中,由于系统之间缺乏互连,事务和分析经常出现延迟,我们只能依赖Batch以实现集成。在Batch模式中,大文件(即数据的dump文件)通常是由操作系统生成,并且通过验证、清理、标准化、以及转换等处理,进而输出文件以供系统分析。由于此类大文件的读取会占用大量的内存,因此数据架构师通常会依赖一些暂存类型的数据库,来持续存储已完成处理的数据输出。
近年来,随着以Hadoop为代表的分布式计算的广泛发展与应用,MapReduce通过在商用硬件上的水平扩展,以分布处理的方式,解决了高内存的使用需求。如今,随着计算技术的进一步发展,我们已可以在内存中运行MapReduce,并使之成为了处理大型数据文件的标准。
就在Batch方式进行演变的过程中,非批(non-batch)处理方式也得到了重大进展。多年来,面向用户的物联网设备已逐渐成为数据系统中的重要一环。大量数据源于物联网设备的采集,而事件驱动型架构也成为了基于微服务的云原生开发方法的流行选择。由于数据处理频率的成倍增加,数据流的处理能力成为了数据集成工作的主要非功能性需求。因此,曾经是大文件数据集成问题,已演变成为了流处理需求。这就需要我们提供一个具有足够缓冲区的数据管道,通过持久性来避免数据包的丢失。
在那些以云服务为主体的平台上,各种组件的水平扩展能力,相对于数据流和使用者而言,要比垂直扩展更加重要。因此,对流的水平可伸缩性以及流的使用者有明确的关注。这也是诸如Kafka之类的数据流解决方案、以及Kubernetes集群需要向使用者(consumer)提供的。目前,Lambda架构的Speed层、以及Kappa架构的构建也都在向此方法发展。
采用Spark、Kafka和k8s构建下一代数据管道的目的,本文将讨论相关架构模式,以及对应的示例代码,您可以跟着一步一步在自己的环境中搭建与实现。
Lambda架构
Lambda架构主要两个层次:Batch和Stream。Batch能够按照预定的批次转换数据,而Stream负责近乎实时地处理数据。Batch层通常被使用的场景是:在源系统中批量发送的数据,需要访问整个数据集,以进行所需的数据处理,不过因为数据集太大,无法执行流式处理。相反,那些带有小块数据包的高速数据需要在Speed层被处理。这些数据包要么相互独立,要么按照速度相近的方式形成了对应的上下文。显然,这两种类型的数据处理方式,都属于计算密集型,尽管Batch层的内存需求要高于Speed层。与之对应的架构方案需要具备可扩展性、容错性、性能优势、成本效益、灵活性、以及分布式。
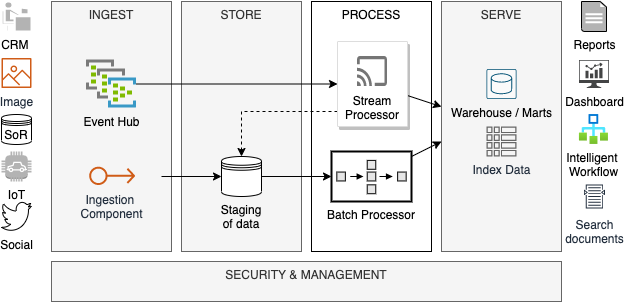
图 1:Lambda架构
由上图可知,由于Lambda需要两个单独的组件,来进行Batch和Speed层面的数据处理,因此其架构较为复杂。如果我们能够用某个单一的技术组件,来同时满足这两个目的,则会大幅降低复杂性。而这正是Apache Spark大显身手之处。
分布式计算的最新选择
凭借着包括SparkSQL和SparkStreaming在内的一系列库,Apache Spark作为一种有效的方案,可通过内存计算,来实现分布式Lambda架构。其中,SparkSQL能够支持各种Batch操作,例如:通过分布式架构加载、验证、转换、聚合、以及映射数据,进而减少对于单台机器的内存需求。同样,基于SparkStreaming的作业任务,可以近乎实时地处理来自Kafka等来源的数据流,并将分析结果提供给诸如:数据仓库或数据湖等更为持久的组件。

图 2:Batch和Speed层的上下文
Kubernetes是一种云平台集群管理器,其最新版本的Spark,可以运行在由 Kubernetes管理的集群上。可以说,基于Kubernetes的Spark是在云端实现Lambda架构的绝佳组合。
虽然我们可以单独地使用Kubernetes进行分布式计算,但是在这种情况下我们仍需要依赖定制的解决方案。例如,在Batch层中,Spring Batch框架可以与Kubernetes集群结合使用,进而将工作任务分发到多个集群节点处。类似地,Kubernetes也可以将流数据分发到多个针对Speed层,而并行运行的Pod。Pod可以通过在其中生成容器,以实现轻松地水平扩展,进而能够根据数据的体量和速率去调整集群。
Spark,针对Lambda架构的一站式解决方案
针对Batch和Speed层的非功能性需求,Apache Spark具有如下特性:
- 可扩展性:Spark集群可以按需进行扩、缩容。由于它由一个主节点和一组工作节点组成,因此这些工作节点会随着工作负载的增加,而提高水平扩展的能力。
- 容错性:Spark框架能够处理由于工作节点的崩溃,而导致的集群故障。由于每个数据帧都会被逻辑分区,而每个分区的数据处理都会发生在某个节点上。那么,在处理数据时,如果某个节点发生了故障,那么集群管理器会按照有向无环图(Directed Acyclic Graph,DAG)的逻辑,分配另一个节点来执行数据帧的相同分区,进而确保绝对的零数据丢失。
- 效率高:由于Spark支持内存计算,因此在执行期间,数据可以根据Hadoop的需要,被存储在RAM中,而非磁盘上。其效率显然要高得多。
- 灵活的负载分配:由于Spark支持分布式计算,能够横跨多个节点共享任务的组件,并作为一个集成单元生成输出。Spark可以运行在 Kubernetes 管理的集群上,这使得它在云环境中更加合适。
- 成本:Spark是开源的,本身不包含任何成本。当然,如果选择托管服务,则需要付出一定的代价。
现在让我们深入了解Spark以了解它如何帮助Batch和蒸汽处理。Spark由两个主要组件组成:Spark核心 API 和Spark库。核心 API 层提供对四种语言的支持:R、Python、Scala 和 Java。在核心 API 层之上,我们有以下Spark库,每个库都针对不同的目的。
- SparkSQL:处理(半)结构化数据,执行基本转换功能并在数据集上执行 SQL 查询SparkStreaming:能够处理流数据;支持近实时数据处理
- SparkMLib:用于机器学习;根据需要用于数据处理
- SparkGraphX:用于图形处理;这里讨论的范围很少使用
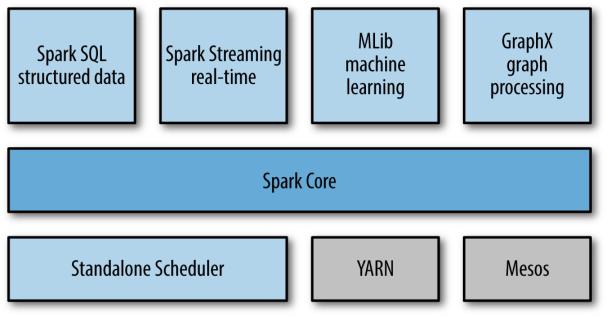
图 3:Spark堆栈(来源:LearningSpark,O'Reilly Media, Inc.)
Batch层的Spark
在Lambda架构转换的Batch层,对(半)结构化数据的计算、聚合操作由SparkSQL 库处理。让我们进一步讨论SparkSQL 架构。
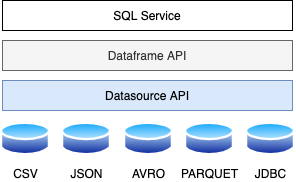
图 4:SparkSQL 架构
从上图中可以明显看出,SparkSQL 具有三个主要架构层,如下所述:
- 数据源 API:处理不同的数据格式,如 CSV、JSON、AVRO 和 PARQUET。它还有助于连接不同的数据源,如 HDFS、HIVE、MYSQL、CASSANDRA 等。 用于加载不同格式数据的通用 API:
Dataframe.read.load(“ParquetFile | JsonFile | TextFile | CSVFile | AVROFile”)
- 数据帧API:Spark2.0 以后,Spark数据帧被大量使用。它有助于保存大型关系数据并公开多个转换函数以对数据集进行切片和切块。通过 Dataframe API 公开的此类转换函数的示例是:
withColumn, select, withColumnRenamed, groupBy, filter, sort, orderBy etc.
- SQL 服务:SparkSQL 服务是帮助我们创建数据框和保存关系数据以进行进一步转换的主要元素。这是我们使用SparkSQL 时Batch层转换的入口点。在转换过程中,可以使用python、R、Scala或Java中的不同API,也可以直接执行SQL来转换数据。
下面是一些Batch的代码示例:
假设有两个表:一个是 PRODUCT,另一个是 TRANSACTION。PRODUCT 表包含商店特定产品的所有信息,Transaction 表包含针对每个产品的所有交易。我们可以通过转换和聚合得到以下信息。
- 产品明智的总销售量
- 分部明智的总收入
通过在Spark数据帧上编写纯 SQL 或使用聚合函数可以获得相同的结果。
Python
from pyspark.sql importSparkSession
from pyspark.sql.functions import *
Spark=SparkSession.builder.master("local").appName("Superstore").getOrCreate()
df1 =Spark.read.csv("Product.csv")
df2 =Spark.read.csv("Transaction.csv")
df3 = df1.filter(df1.Segment != 'Electric')
df4 = df2.withColumn("OrderDate",df2.OrderDate[7:10])
result_df1 = df3.join(df4, on= ['ProductCode'], how='inner')
result_df2 = result_df1.groupBy('ProductName').sum('Quantity')
result_df2.show()
# Display segment wise revenue generated
result_df3 = result_df1.groupBy('Segment').sum('Price')
result_df3.show()
Python
from pyspark.sql importSparkSession
from pyspark.sql.functions import *
Spark=SparkSession.builder.master("local").appName("Superstore").getOrCreate()
df1 =Spark.read.csv("Product.csv")
df2 =Spark.read.csv("Transaction.csv")
df3 = df1.filter(df1.Segment != 'Electric')
df4 = df2.withColumn("OrderDate",df2.OrderDate[7:10])
result_df1 = df3.join(df4, on= ['ProductCode'], how='inner')
result_df1.createOrReplaceTempView("SuperStore")
# Display product wise quantity sold
result_df2 =Spark.sql("select ProductName , Sum(Quantity) from Superstore group by ProductName")
result_df2.show()
# Display segment wise revenue earned
result_df3 =Spark.sql("select Segment , Sum(Price) from Superstore group by Segment")
result_df2.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
在这两种情况下,第一个数据是从两个不同的来源加载的,并且产品数据针对所有非电气产品进行过滤。交易数据根据订单日期的某种格式进行更改。然后,将两个数据帧连接起来,并生成该超市中细分收入和产品销售数量的结果。
当然,这是加载、验证、转换和聚合的简单示例。使用SparkSQL 可以进行更复杂的操作。要了解有关SparkSQL 服务的更多信息,请参阅此处的文档。
Sparkfor Speed 层
SparkStreaming 是一个库,用于核心Spark框架之上。它确保实时数据流处理的可扩展性、高吞吐量和容错性。

图 5:SparkStreaming 架构(来源:https : //spark.apache.org)
如上图所示,Spark将输入数据流转换为批量输入数据。这种离散Batch有两种实现方式:a) Dstreams 或离散化流和 b) 结构化流。前者非常受欢迎,直到后者作为更高级的版本出现。但是,Dstream 还没有完全过时,为了完整起见,将其保留在本文中。
· Discretized Streams:这提供了对火花流库的抽象。它是 RDD 的集合,代表一个连续的数据流。它将数据离散成小批量并运行小作业来处理这些小批量。任务根据数据的位置分配给工作节点。因此,通过 Dstream 的这个概念,Spark可以并行读取数据,执行小批量处理流并确保流处理的有效节点分配。
· 结构化流:这是使用Spark引擎的最先进和现代的流处理方法。它与SparkDataframe API(在上面的Batch部分中讨论)很好地集成在一起,用于对流数据的各种操作。结构化流可以增量和连续地处理数据。基于特定窗口和水印的近实时聚合也是可能的。
Spark结构化流可以处理不同的流处理用例,如下面的示例所示:
简单的结构化流媒体
简单的结构化流只会转换和加载来自流的数据,并且不包括特定时间范围内的任何聚合。例如,系统从 Apache Kafka 获取数据,并通过Spark流和SparkSQL 近乎实时地对其进行转换(请参阅下面的代码片段)。
Python
from pyspark.sql importSparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.functions as sf
spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers,"localhost:9092")
.option("subscribe", "test_topic").load()
df1 = df.selectExpr("CAST(value AS STRING)")
df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
df2.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
SparkSession 对象的ReadStream函数用于连接特定的 Kafka 主题。正如上面选项中的代码片段一样,我们需要提供 Kafka 集群代理的 IP 和 Kafka 主题名称。此代码的输出是一个表,有两列:Dept 和 Age。
结构化流媒体聚合
可以通过 Structured Streaming 对流数据进行聚合,它能够在新事件到达的基础上计算滚动聚合结果。这是对整个数据流的运行聚合。请参考下面的代码片段,它在整个数据流上推导出部门明智的平均年龄。
Python
from pyspark.sql importSparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.functions as sf
spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic").load()
df1 = df.selectExpr("CAST(value AS STRING)")
df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
df3 = df2.groupBy("Dept").avg("Age")
df3.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
窗口聚合
有时我们需要在某个时间窗口内进行聚合,而不是运行聚合。SparkStructured Streaming 也提供了这样的功能。假设我们要计算过去 5 分钟内的事件数。这个带聚合的窗口函数将帮助我们。
Python
from pyspark.sql importSparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.functions as sf
import datetime
import time
spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic").load()
df1 = df.selectExpr("CAST(value AS STRING)")
df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
df3 = df2.withColumn("Age", df2.Age.cast('int'))
df4 = df3.withColumn("eventTime",sf.current_timestamp())
df_final = df4.groupBy(sf.window("eventTime", "5 minute")).count()
df_final.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
重叠窗口上的聚合
在上面的例子中,每个窗口都是一个完成聚合的组。还提供了通过提及窗口长度和滑动间隔来定义重叠窗口的规定。它在窗口聚合中的后期数据处理中非常有用。下面的代码基于 5 分钟窗口计算事件数,滑动间隔为 10 分钟。
Python
from pyspark.sql importSparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.functions as sf
import datetime
import time
spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic").load()
df1 = df.selectExpr("CAST(value AS STRING)")
df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
df3 = df2.withColumn("Age", df2.Age.cast('int'))
df4 = df3.withColumn("eventTime",sf.current_timestamp())
df_final = df4.groupBy("Dept",sf.window("eventTime","10 minutes", "5 minute")).count()
df_final.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
带水印和重叠窗口的聚合
数据迟到会在近实时系统的聚合中产生问题。我们可以使用重叠窗口来解决这个错误。但问题是:系统等待迟到的数据需要多长时间?这可以通过水印解决。通过这种方法,我们在重叠窗口之上定义了一个特定的时间段。之后,系统丢弃该事件。
Python
from pyspark.sql importSparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.functions as sf
import datetime
import time
spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic").load()
df1 = df.selectExpr("CAST(value AS STRING)")
df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
df3 = df2.withColumn("Age", df2.Age.cast('int'))
df4 = df3.withColumn("eventTime",sf.current_timestamp())
df_final = df4.withWatermark("eventTime","10 Minutes").groupBy("Dept",sf.window("eventTime","10 minutes", "5 minute")).count()
df_final.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
上面的代码表示对于延迟事件,10 分钟后,旧窗口结果将不会更新。
Kafka + k8s - Speed层的另一种解决方案
托管在 Kubernetes 集群上的 Pod 形成了 Kafka 流的消费者组,是另一种近乎实时数据处理的方法。通过使用这种组合,我们可以轻松获得分布式计算的优势。
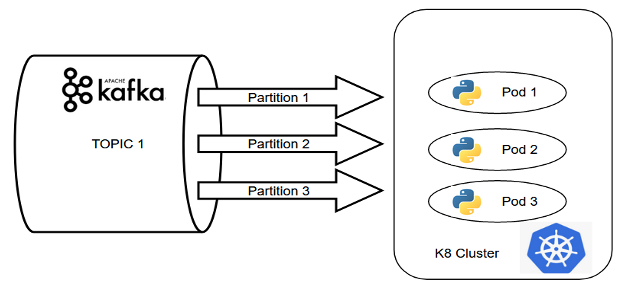
图 6:通过 Kafka + Kubernetes 实现的Speed层示例
在上面例子中的事件驱动系统中,数据正在从 Kafka 主题加载到基于 Python 的处理单元中。如果 Kafka 集群中的分区数量与 Pod 的复制因子匹配,则 Pod 一起组成一个消费者组,消息被无缝消费。
这是构建分布式数据处理系统的经典示例,仅使用Kafka+k8s组合即可确保并行处理。
使用 Python 创建 Kafka 消费者的两个非常流行的库是:
- Python_Kafka 库
- Confluent_Kafka 库
Python_Kafka
Python
from kafka import KafkaConsumer
consumer = KafkaConsumer(TopicName,
bootstrap_servers= <broker-list>,
group_id=<GroupName>,
enable_auto_commit=True,
auto_offset_reset='earliest')
consumer.poll()
Confluent_Kafka
Python
from confluent_kafka import Consumer
consumer = Consumer({'bootstrap.servers': <broker-list>,
'group.id': <GroupName>,
'enable.auto.commit': True,
'auto.offset.reset': 'earliest'
})
consumer.subscribe([TopicName])
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
K8.yml 文件的示例结构如下:
YAML
metadata:
name: <app name>
namespace: <deployment namespace>
labels:
app: <app name>
spec:
replicas: <replication-factor>
spec:
containers:
- name: <container name>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
如果按照上述方式开发基本组件,系统将获得分布式计算的帮助,而无需进行内存计算。一切都取决于系统的体积和所需速度。对于低/中等数据量,可以通过实现这种基于 python-k8 的架构来确保良好的速度。
这两种方法都可以托管在具有各种服务的云中。例如,我们在 AWS 中有 EMR 和 Glue,可以在 GCP 中通过 Dataproc 创建Spark集群,或者我们可以在 Azure 中使用 Databricks。另一方面,kafka-python-k8的方式可以很容易地在云端实现,这保证了更好的可管理性。例如在 AWS 中,我们可以将 MSK 或 Kinesis 和 EKS 的组合用于这种方法。在下一个版本中,我们将讨论所有云供应商中Batch和Speed层的实现,并根据不同的需求提供比较研究。
原文标题:Next-Gen Data Pipes WithSpark, Kafka and k8s,作者:Subhendu Dey & Abhishek Sinha
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】













