













任何一种技术都会经历从阳春白雪到下里巴人的过程,就像我们对计算机的理解从“戴着鞋套才能进的机房”变成了随处可见的智能手机。在前面20年中,大数据技术也经历了这样的过程,从曾经高高在上的 “火箭科技(rocket science)”,成为了人人普惠的技术。
回首来看,大数据发展初期涌现了非常多开源和自研系统,并在同一个领域展开了相当长的一段“红海”竞争期,例如Yarn VS Mesos、Hive VS Spark、Flink VS SparkStreaming VS Apex、Impala VS Presto VS Clickhouse等等。经历激烈竞争和淘汰后,胜出的产品逐渐规模化,并开始占领市场和开发者。
事实上,近几年,大数据领域已经没有再诞生新的明星开源引擎(Clickhouse@2016年开源,PyTorch@2018年开源),以Apache Mesos等项目停止维护为代表,大数据领域进入“后红海”时代:技术开始逐步收敛,进入技术普惠和业务大规模应用的阶段。
本文作者关涛是大数据系统领域的资深专家,在微软(互联网/Azure云事业群)和阿里巴巴(阿里云)经历了大数据发展20年过程中的后15年。本文试从系统架构的角度,就大数据架构热点,每条技术线的发展脉络,以及技术趋势和未解问题等方面做一概述。
值得一提的是,大数据领域仍然处于发展期,部分技术收敛,但新方向和新领域层出不穷。本文内容和个人经历相关,是个人的视角,难免有缺失或者偏颇,同时限于篇幅,也很难全面。仅作抛砖引玉,希望和同业共同探讨。
一、当下的大数据体系热点
BigData概念在上世纪90年代被提出,随Google的3篇经典论文(GFS,BigTable,MapReduce)奠基,已经发展了将近20年。这20年中,诞生了包括Google大数据体系,微软Cosmos体系,阿里云的飞天系统,开源Hadoop体系等优秀的系统。这些系统一步步推动业界进入“数字化“和之后的“AI化”的时代。
海量的数据以及其蕴含的价值,吸引了大量投入,极大的推动大数据领域技术。云(Cloud)的兴起又使得大数据技术对于中小企业唾手可得。可以说,大数据技术发展正当时。
从体系架构的角度看,“Shared-Everything”架构演进、湖仓技术的一体化融合、云原生带来的基础设计升级、以及更好的AI支持,是当下平台技术的四个热点。
1.1 系统架构角度,平台整体向Shared-Everything架构演进
泛数据领域的系统架构,从传统数据库的Scale-up向大数据的Scale-out发展。从分布式系统的角度,整体架构可以按照Shared-Nothing(也称MPP), Shared-Data, Shared-Everything 三种架构。
大数据平台的数仓体系最初由数据库发展而来,Shared-Nothing(也称MPP)架构在很长一段时间成为主流。随云原生能力增强,Snowflake为代表的Shared-Data逐渐发展起来。而基于DFS和MapReduce原理的大数据体系,设计之初就是Shared-Everything架构。
Shared-Everything架构代表是GoogleBigQuery和阿里云MaxCompute。从架构角度,Shared-Everything架构具备更好的灵活性和潜力,会是未来发展的方向。
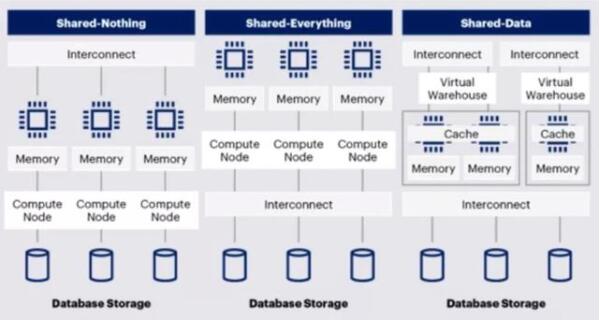
(图:三种大数据体系架构)
1.2 数据管理角度,数据湖与数据仓库融合,形成湖仓一体
数据仓库的高性能与管理能力,与数据湖的灵活性,仓和湖的两套体系在相互借鉴与融合。在2020年各个厂商分别提出湖仓一体架构,成为当下架构演进最热的趋势。但湖仓一体架构有多种形态,不同形态尚在演进和争论中。

(图:数据湖与数据仓库借鉴融合)
1.3 云架构角度,云原生与托管化成为主流
随着大数据平台技术进入深水区,用户也开始分流,越来越多的中小用户不再自研或自建数据平台,开始拥抱全托管型(通常也是云原生)的数据产品。Snowflake作为这一领域的典型产品,得到普遍认可。面向未来,后续仅会有少量超大规模头部公司采用自建(开源+改进)的模式。
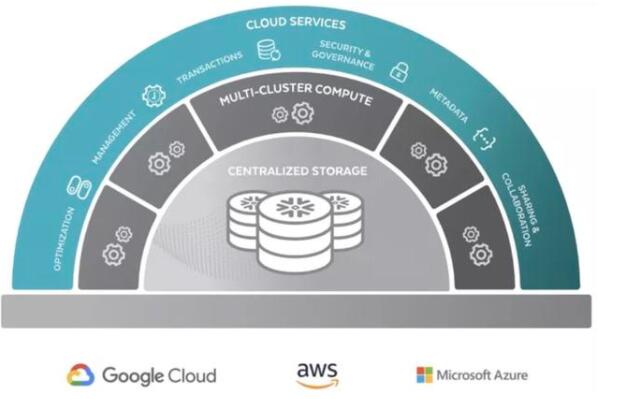
(图:snowflake的云原生架构)
1.4 计算模式角度,AI逐渐成为主流,形成BI+AI双模式
BI作为统计分析类计算,主要是面向过去的总结;AI类计算则具备越来越好的预测未来的能力。在过去五年中,算法类的负载从不到数据中心总容量的5%,提升到30%。AI已经成为大数据领域的一等公民。
二、大数据体系的领域架构
在前文(#1.1)介绍的Shared-Nothing、Shared-Data、Shared-Everything 三种架构中,笔者经历过的两套体系(微软Cosmos/Scope体系,和阿里云MaxCompute)均为Shared-Everything架构,因此笔者主要从Shared-Everything架构角度,将大数据领域分成6个叠加的子领域、3个横向领域,共9个领域,具体如下图。

(图:基于 Shared-Everything 大数据体系下的领域架构)
经过多年的发展,每个领域都有一定的进展和沉淀,下面各个章节将概述每个子领域的演进历史、背后驱动力、以及发展方向。
2.1 分布式存储向多层智能化演进
分布式存储,本文特指通用大数据海量分布式存储,是个典型的带状态(Stateful)分布式系统,高吞吐、低成本、容灾、高可用是核心优化方向。(注:下述分代仅为了阐述方便,不代表严格的架构演进。)
第一代,分布式存储的典型代表是谷歌的GFS和Apache Hadoop的HDFS,均为支持多备份的Append-only文件系统。因HDFS早期NameNode在扩展性和容灾方面的短板不能充分满足用户对数据高可用的要求,很多大型公司都有自研的存储系统,如微软的Cosmos(后来演进成Azure Blob Storage),以及阿里巴巴的Pangu系统。HDFS作为开源存储的奠基,其接口成为事实标准,同时HDFS又具备支持其他系统作为背后存储系统的插件化能力。
第二代,基于上述底盘,随海量对象存储需求激增(例如海量的照片),通用的Append-only文件系统之上,封装一层支持海量小对象的元数据服务层,形成对象存储(Object-based Storage),典型的代表包括AWS S3,阿里云OSS。值得一提的是,S3与OSS均可作为标准插件,成为HDFS的事实存储后端。
第三代,以数据湖为代表。随云计算技术的发展,以及(2015年之后)网络技术的进步,存储计算一体的架构逐渐被云原生存储(存储托管化)+ 存储计算分离的新架构取代。这也是数据湖体系的起点。同时因存储计算分离带来的带宽性能问题并未完全解决,在这个细分领域诞生了Alluxio等缓存服务。
第四代,也是当下的趋势,随存储云托管化,底层实现对用户透明,因此存储系统有机会向更复杂的设计方向发展,从而开始向多层一体化存储系统演进。由单一的基于SATA磁盘的系统,向Mem/SSD+SATA (3X备份)+SATA (1.375X为代表的EC备份)+冰存储(典型代表AWS Glacier)等多层系统演进。
如何智能/透明的将数据存储分层,找到成本与性能的Trade-off,是多层存储系统的关键挑战。这领域起步不久,开源领域没有显著好的产品,最好的水平由几个大厂的自研数仓存储系统引领。
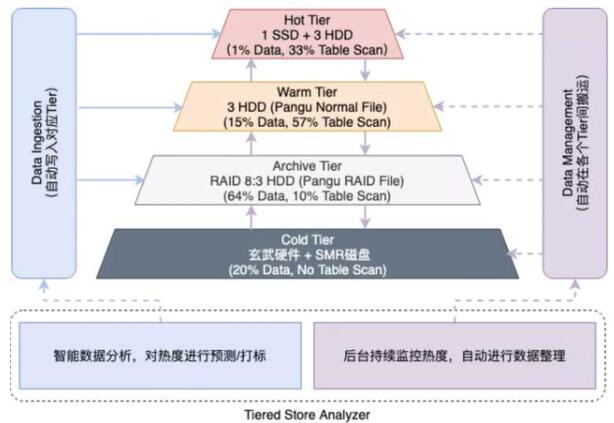
(图:阿里巴巴 MaxCompute 的多层一体化存储体系)
在上述系统之上,有一层文件存储格式层(File Format layer),与存储系统本身正交。
存储格式第一代,包含文件格式、压缩和编码技术、以及Index支持等。目前主流两类的存储格式是Apache Parquet和Apache ORC,分别来自Spark和Hive生态。两者均为适应大数据的列式存储格式,ORC在压缩编码上有特长,Parquet在半结构支持上更优。此外另有一种内存格式Apache Arrow,设计体系也属于format,但主要为内存交换优化。
存储格式第二代 - 以 Apache Hudi/Delta Lake 为代表的近实时化存储格式。存储格式早期,是大文件列存储模式,面向吞吐率优化(而非latency)。随着实时化的趋势,上述主流的两个存储模式均向支持实时化演进,Databricks推出了Delta Lake,支持Apache Spark进行近实时的数据ACID操作;Uber推出了Apache Hudi,支持近实时的数据Upsert能力。
尽管二者在细节处理上稍有不同(例如Merge on Read or Write),但整体方式都是通过支持增量文件的方式,将数据更新的周期降低到更短(避免传统Parquet/ORC上的针对更新的无差别FullMerge操作),进而实现近实时化存储。因为近实时方向,通常涉及更频繁的文件Merge以及细粒度元数据支持,接口也更复杂,Delta/Hudi均不是单纯的format、而是一套服务。
存储格式再向实时更新支持方向演进,会与实时索引结合,不再单单作为文件存储格式,而是与内存结构融合形成整体方案。主流的是实时更新实现是基于LogStructuredMergeTree(几乎所有的实时数仓)或者Lucene Index(Elastic Search的格式)的方式。
从存储系统的接口/内部功能看,越简单的接口和功能对应更开放的能力(例如GFS/HDFS),更复杂更高效的功能通常意味着更封闭,并逐步退化成存算一体的系统(例如AWS当家数仓产品RedShift),两个方向的技术在融合。
展望未来,我们看到可能的发展方向/趋势主要有:
1)平台层面,存储计算分离会在两三年内成为标准,平台向托管化和云原生的方向发展。平台内部,精细化的分层成为平衡性能和成本的关键手段(这方面,当前数据湖产品还做得远远不够),AI在分层算法上发挥更大的作用。
2)Format层面,会继续演进,但大的突破和换代很可能取决于新硬件的演进(编码和压缩在通用处理器上的优化空间有限)。
3)数据湖和数仓进一步融合,使得存储不仅仅是文件系统。存储层做的多厚,与计算的边界是什么,仍然是个关键问题。
2.2 分布式调度,基于云原生,向统一框架和算法多元化发展
计算资源管理是分布式计算的核心能力,本质是解决不同种类的负载与资源最优匹配的问题。在“后红海时代”,Google的Borg系统,开源Apache Yarn 依旧是这个领域的关键产品,K8S在大数据计算调度方向上仍在起步追赶。
常见的集群调度架构有:
中心化调度架构:早期的Hadoop1.0的MapReduce、后续发展的Borg、和Kubernetes都是中心化设计的调度框架,由单一的调度器负责将任务指派给集群内的机器。特别的,中心调度器中,大多数系统采用两级调度框架通过将资源调度和作业调度分开的方式,允许根据特定的应用来定做不同的作业调度逻辑,并同时保留了不同作业之间共享集群资源的特性。Yarn、Mesos都是这种架构。
共享状态调度架构:半分布式的模式。应用层的每个调度器都拥有一份集群状态的副本,并且调度器会独立地对集群状态副本进行更新。如Google的Omega、Microsoft的Apollo,都是这种架构。
全分布式调度架构:从Sparrow论文开始提出的全分布式架构则更加去中心化。调度器之间没有任何的协调,并且使用很多各自独立的调度器来处理不同的负载。
混合式调度架构:这种架构结合了中心化调度和共享状态的设计。一般有两条调度路径,分别为为部分负载设计的分布式调度,和来处理剩下的负载的中心式作业调度。
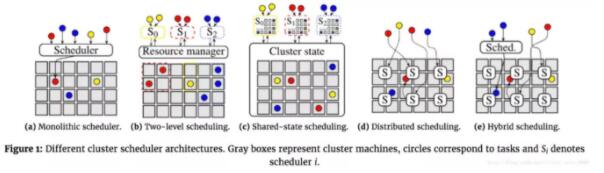
(图 :The evolution of cluster scheduler architectures by Malte Schwarzkopf)
无论大数据系统的调度系统是基于哪种架构,在海量数据处理流程中,都需要具备以下几个维度的调度能力:
数据调度:多机房跨区域的系统服务带来全域数据排布问题,需要最优化使用存储空间与网络带宽。
资源调度:IT基础设施整体云化的趋势,对资源的调度和隔离都带来更大的技术挑战;同时物理集群规模的进一步扩大,去中心化的调度架构成为趋势。
计算调度:经典的MapReduce计算框架逐渐演化到支持动态调整、数据Shuffle的全局优化、充分利用内存网络等硬件资源的精细化调度时代。
单机调度:资源高压力下的SLA保障一直以来是学术界和工业界发力的方向。Borg等开源探索都假设在资源冲突时无条件向在线业务倾斜;但是离线业务也有强SLA需求,不能随意牺牲。
展望未来,我们看到可能的发展方向/趋势主要有:
1.K8S统一调度框架:Google Borg很早就证明了统一的资源管理有利于最优匹配和削峰填谷,尽管K8S在“非在线服务”调度上仍然有挑战,K8S准确的定位和灵活的插件式设计应该可以成为最终的赢家。大数据调度器(比如KubeBatch)是目前投资的一个热点。
2.调度算法多元化和智能化:随各种资源的解耦(例如,存储计算分离),调度算法可以在单一维度做更深度的优化,AI优化是关键方向(实际上,很多年前Google Borg就已经采用蒙特卡洛Simulation做新任务资源需求的预测了)。
3.面向异构硬件的调度支持:众核架构的ARM成为通用计算领域的热点,GPU/TPU等AI加速芯片也成为主流,调度系统需要更好支持多种异构硬件,并抽象简单的接口,这方面K8S插件式设计有明显的优势。
2.3 元数据服务统一化
元数据服务支撑了大数据平台及其之上的各个计算引擎及框架的运行,元数据服务是在线服务,具有高频、高吞吐的特性,需要具备提供高可用性、高稳定性的服务能力,需要具备持续兼容、热升级、多集群(副本)管理等能力。主要包括以下三方面的功能:
DDL/DML的业务逻辑,保障ACID特性,保障数据完整性和一致性
授权与鉴权能力,保证数据访问的安全性
Meta(元数据) 的高可用存储和查询能力,保障作业的稳定性
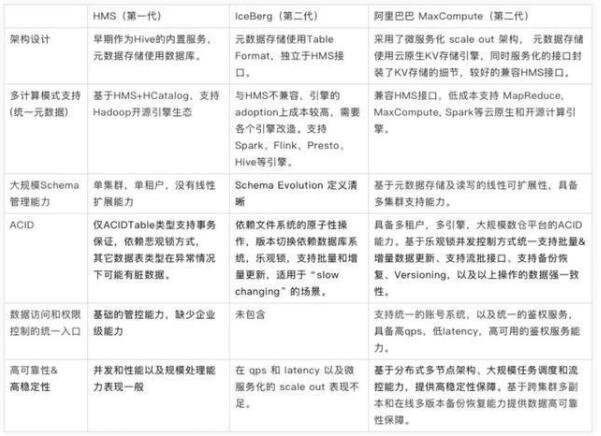
第一代数据平台的元数据系统,是Hive的Hive MetaStore(HMS)。在早期版本中HMS元数据服务是Hive的内置服务,元数据更新(DDL)以及DML作业数据读写的一致性和Hive的引擎强耦合,元数据的存储通常托管在MySQL等关系数据库引擎。
随着客户对数据加工处理的一致性(ACID),开放性(多引擎,多数据源),实时性,以及大规模扩展能力的要求越来越高,传统的HMS逐步局限于单集群,单租户,Hive为主的单个企业内部使用,为保障数据的安全可靠,运维成本居高不下。这些缺点在大规模生产环境逐步暴露出来。
第二代元数据系统的代表,有开源体系的Apache IceBerg,和云原生体系的阿里巴巴大数据平台MaxCompute的元数据系统。
IceBerg是开源大数据平台最近两年出现的独立于引擎和存储的“元数据系统”,其要解决的核心问题是大数据处理的ACID,以及表和分区的元数据的规模化之后性能瓶颈。在实现方法上IceBerg的ACID依托了文件系统POSIX的语义,分区的元数据采用了文件方式存储,同时,IceBerg的Table Format独立于Hive MetaStore的元数据接口,因此在引擎的adoption上成本很高,需要各个引擎改造。
基于未来的热点和趋势的分析,开放的,托管的统一元数据服务越来越重要,多家云厂商,都开始提供了DataCatalog服务,支持多引擎对湖和仓数据存储层的访问。
对比第一代与第二代元数据系统:
展望未来,我们看到可能的发展方向/趋势主要有:
1.趋势一:湖仓一体进一步发展下,元数据的统一化,以及对湖上元数据和数据的访问能力建设。如基于一套账号体系的统一的元数据接口,支持湖和仓的元数据的访问能力。以及多种表格式的ACID的能力的融合,这个在湖上数据写入场景越来越丰富时,支持Delta,Hudi,IceBerg表格式会是平台型产品的一个挑战。
2.趋势二:元数据的权限体系转向企业租户身份及权限体系,不再局限于单个引擎的限制。
3.趋势三:元数据模型开始突破关系范式的结构化模型,提供更丰富的元数据模型,支持标签,分类以及自定义类型和元数据格式的表达能力,支持AI计算引擎等等。
本文详细阐述了后红海时代,当下大数据体系的演进热点是什么,以及大数据体系下部分子领域架构的技术解读。

















