数据作为互联网时代的基础生产资料,在各大公司企业拥有举足轻重的地位。数据的价值在互联网公司的体现,大致而言可以分成三类:
- 发掘数据中的信息来指导决策,如产品运营、用户增长相关的BI报表
- 依托数据优化用户体验和变现效率,如信息分发场景下的个性化推荐、效果广告等
- 基于数据统计的业务监控,如监控大盘、安全风控等
在这些体现大数据价值的业务场景上,存在一个普遍的规律,即数据产生的价值,随着时间的推移而衰减。因此,随着公司业务的发展,传统的T+1式(隔日)的离线大数据模式越来越无法满足新兴业务的发展需求。开展实时化的大数据业务,是企业深入挖掘数据价值的一条必经之路。
爱奇艺大数据团队自2014年开始引入Kafka、Storm、Spark Streaming等实时化技术,2017年引入Apache Flink实时计算框架,逐步建设了一套打通数据采集、加工、分发、分析、应用等完整数据流程的实时大数据体系。这套实时大数据体系支持了峰值超过3000万QPS的实时数据处理,支持了如春晚直播、青春有你、尖叫之夜等大型活动的实时计算需求。本文将介绍爱奇艺实时大数据体系的主要架构、平台功能以及发展过程中的一些思考。
一、传统实时ETL模式的问题
在实时技术发展初期,大团队为各业务提供的是单纯的日志数据的实时解析服务。通过Flink ETL程序,将用户端上报日志、后台服务器日志、数据库binlog日志,解析成 key-value组装的json形态的结构化数据,发送到Kafka中供各业务使用。其中,ETL逻辑可以由外部配置平台注入,方便在解析逻辑修改时可以动态加载,减少Flink任务的重启频率。这个实时ETL的体系如下图所述:
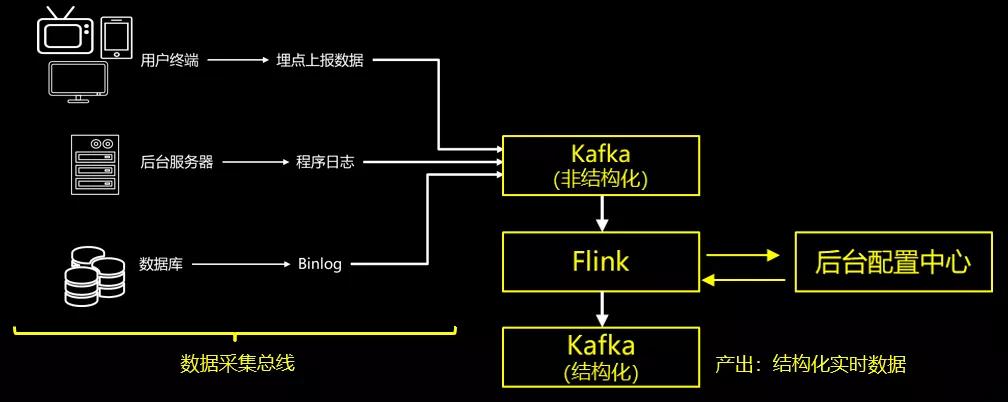
随着实时大数据业务的发展,它的弊端不断出现:
- 实时数据大量重复生产,各业务烟囱式开发,数据难以复用
- 数据治理水平低下,数据生产者不知道数据在被谁消费
- 稳定性差,不能抵御Flink和Kafka故障
为了解决这些问题,爱奇艺大数据团队开始建设实时大数据体系,推出管理Kafka的流数据服务平台、基于Flink的实时数据生产平台、基于Kafka的实时数仓等组件,打通实时数据流程。
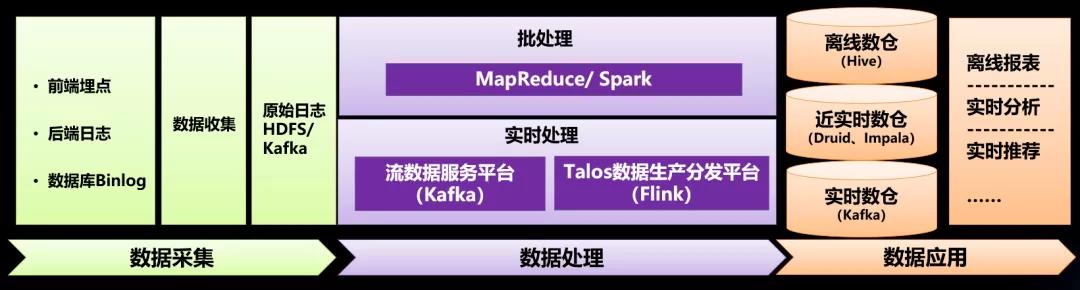
二、实时数仓与传统数仓的区别
在传统的BI体系中,基于离线大数据构建数据仓库的过程,大部分是T+1的隔日离线计算。即每天凌晨开始从原始日志数据构建数仓,将多层级的离线计算任务,通过工作流系统进行串联。数仓构建任务失败后可以有由工作流系统触发任务重跑。一般来说,离线数仓构建任务的失败重跑,只影响数据生产出来的时间,不影响数据的完整性、正确性。
在设计离线数仓模型和对应的计算任务时,一般会从以下几个角度去兼顾平衡:
- 数据膨胀的成本约束(Hive存储)
- 计算资源的成本约束(YARN队列)
- 开发的人力成本约束
- 用户体验,包含数据的时效性以及数仓表使用的便捷性
在实时数仓中,这几个约束条件发生了巨大的变化:
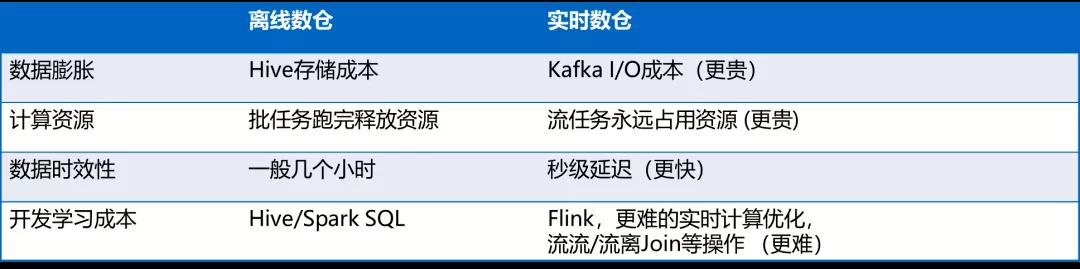
基于这些变化,构建实时数仓的时候,切记不能照搬离线数仓的分层模型和构建逻辑,需要结合实时大数据业务的需求,按照实时业务的特点进行构建。实时数仓的构建,核心有以下几个特点:
- 重视数仓的水平拆分。在离线数仓中,数据的载体是Hive表,借助Hive的分区字段和谓词下推机制,我们可以在各个层级构建一些稍大的表,而将关键的维度字段设置成分区,使用户在查大表的时候达到查小表的效果。在实时数仓中,数据的载体是Kafka队列,如果向用户提供一个大流,需要用户在消费数据实时过滤出其中的一小部分数据进行使用,那么对Kafka的带宽资源和Flink的计算资源都是极大的浪费。因此,我们需要尽量将常用的维度进行水平拆分构建,例如“移动端用户行为”“PC端用户行为”可以拆分到两个流供用户使用。
- 重视维度退化。在离线数仓中,一个维度放在事实表里还是放在维度表里是一件可权衡的事情。一些不太常用的维度可以保留在维度表里,让用户查询使用时再进行Join。而在实时数仓里,用户在使用数据时如果需要进行“实时流Join维度表”的操作,涉及实时计算中比较复杂的流与外部表Join的操作,对应的Flink代码开发和优化难度都较高。因此,在建设实时数仓时应该尽量帮助数据下游方减少这些代价,提前将会用到的维度退化到数仓的事实流中,将实时流变成一个宽流,避免下游业务方在使用数据时,自行去处理流Join外部表的这类复杂场景。
- 重视层级缩短。在实时数仓的构建过程中,数据在多层级Kafka中传递,数据处理的链路越长,数据的延迟越大、稳定性越差。因此,在实时数仓中,要尽可能引导用户使用短链路生产的实时数据。我们建议,实时数仓下游使用的数据,在数仓构建中经过的Kafka层级最好控制在4层以内,例如在ODS层、DWD层之后,最多再加工一次就可以交付用户使用。在很多实时报表的场景上,我们可以选择将DWD层的实时数据灌入OLAP体系(如Druid、Clickhouse),将用户的数据清洗过滤聚合需求转移到OLAP层,减少实时数据在数仓层的加工处理。
三、流数据服务平台
实时数仓的载体是Kafka服务,然而,Kafka作为一个分布式消息队列,它原生的组织和管理方式仍然是一个资源型服务,向用户交付的是Kafka集群。这种管理组织方式对于开展实时大数据业务而言,有一些显著的缺点,例如难以注册和管理数据的输入和输出,无法构建数据血缘链路和高可用体系等等。
为了更好地支持实时数仓等业务的开展,爱奇艺大数据团队建设了流数据服务平台,以一种面向数据的角度,重新组织和管理Kafka服务。
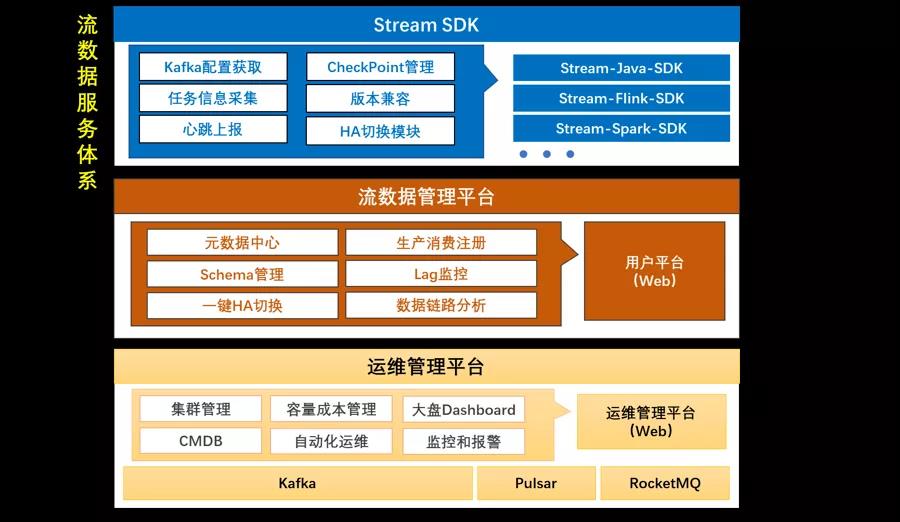
流数据服务平台,自下而上分为三层:
- 运维管理层:负责Kafka、Pulsar、RocketMQ等消息队列集群的资源和运维管理,包括资产登记、容量管理、集群监控、自动化运维、工单审批体系等。
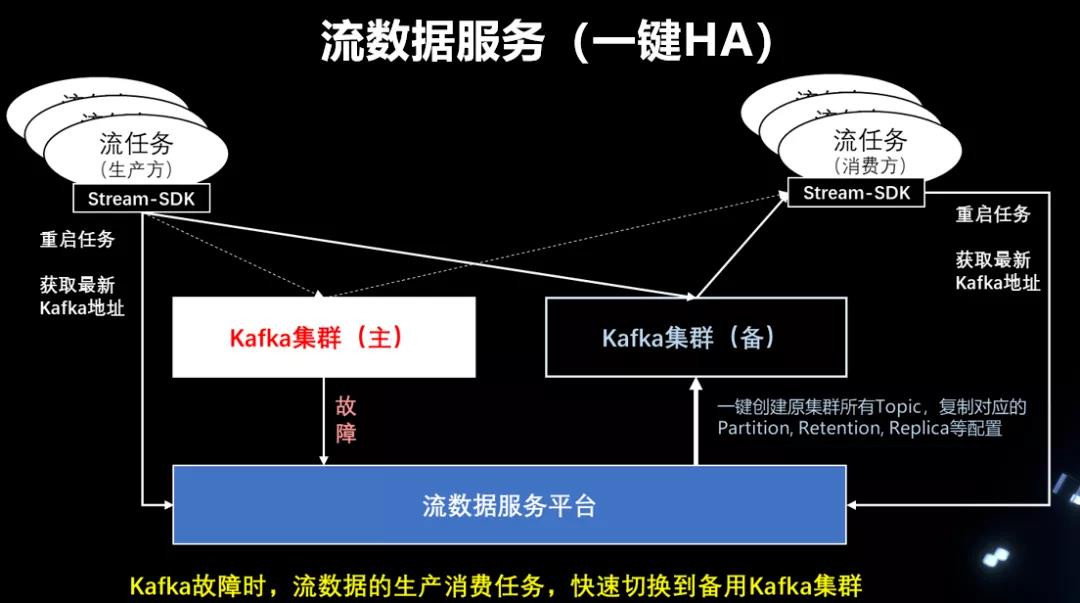
- 流数据管理层:负责登记和管理所有流数据的元信息,面向用户提供数据地图(检索寻找数据)、数据质量监控(生产延迟、消费积压等等)、数据血缘追踪、一键HA切换集群等功能。
- 客户端SDK层:封装原生Kafka Client,向用户提供Flink、Spark、Java等场景下的Kafka SDK,将读写操作全部封装在SDK中,对用户屏蔽Kafka集群版本和地址信息,由SDK通过心跳向配置中心获取数据地址。同时SDK还具备生产消费任务的自动登记注册、Kafka切换时触发任务重启等功能。
依托流数据服务平台,我们大幅提升了Kafka的运维管理和服务提供能力:
- 基于SDK的访问控制模式,极大提高了实时大数据的治理水平。用户看到和访问的都是流数据,无需再关心Kafka集群和地址等信息。
- 在Kafka集群发生故障灾难时,运维人员可以简单的在后台切换数据流对应的Kafka集群,生产消费两侧的流任务同时重启,即可将故障的Kafka从链路中摘除,替换成备用的Kafka集群。
- 流数据服务平台能根据 SDK 上报的信息,分析并绘制数据血缘,用于数据链路排障、数据热度分析、数仓模型优化。
- 依托流数据的元数据中心,提供数据地图的产品,供用户方便的查询检索数据及其Schema相关信息,提高流数据的复用性。
四、实时数据生产分发平台
Kafka服务的高度治理化是实时数仓工作的基础,下一步要建设的是构建实时数仓的工具平台,通过平台降低用户开发管理实时数据处理任务的成本。
爱奇艺大数据团队建设了实时数据生产分发平台Talos。Talos平台兼具实时数据处理和数据集成分发功能,支持用户通过自定义数据处理逻辑,将实时数据加工处理后分发到下游数据流或其他异构存储中。
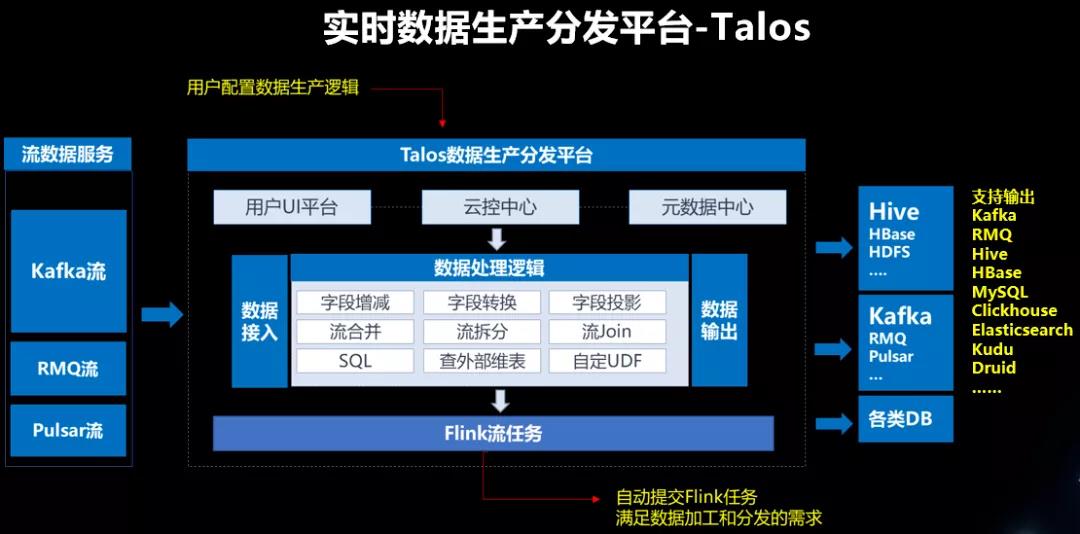
Talos平台上,用户可以通过简单拖拽生成DAG图的方式构建自己的数据处理逻辑,也可以通过SQL算子来表达处理逻辑。对于实时计算的新手用户,使用DAG图可以直观看到数据的处理逻辑和含义。在调试任务时,Talos平台支持查看数据在DAG图中每一步的变化值,非常有利于排查复杂数据处理逻辑中的问题,解决了传统Flink SQL任务调试不便的痛点。
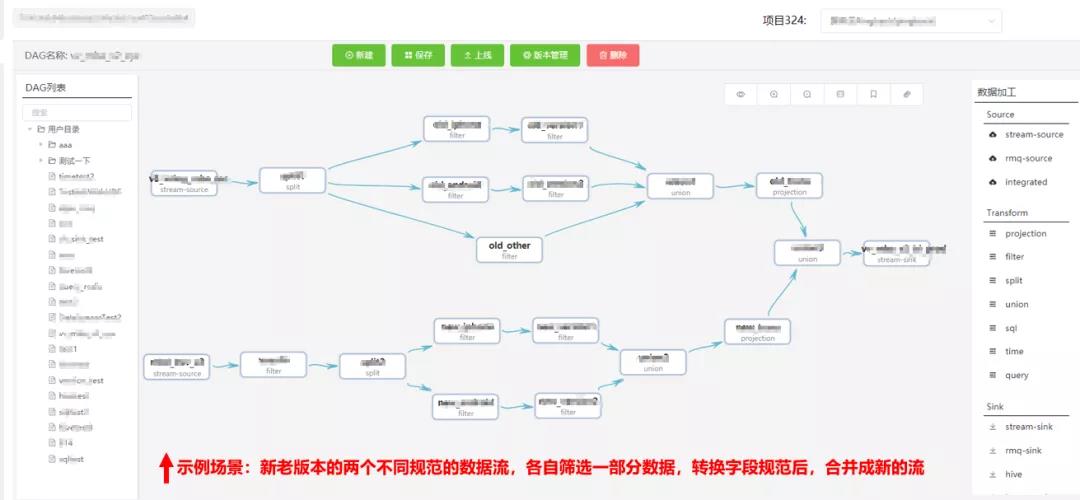
在爱奇艺的实时数仓体系中,实时数据的接入、处理、分发任务都通过Talos平台构建和维护,数仓建设者只需要关心数仓模型的定义和设计,无需撰写Flink代码,也不用关心Flink实时计算任务的提交管理和运维监控等工作,极大的简化了数仓的开发和维护成本。
五、实时分析平台
在实时大数据的下游业务场景中,实时报表和实时分析是最普遍的一种需求场景。传统的Kafka->Flink SQL/Spark SQL->MySQL的实时报表模式只适用于一些指标固定的实时报表,欠缺灵活性。
爱奇艺大数据团队基于Druid+Spark/Flink建设了一套实时分析平台(Realtime Analytics Platform,简称RAP), 打通了实时数仓到实时分析的链路,大幅简化了实时报表的生产和使用成本。
在RAP平台中,我们将实时数仓中生成的Kafka流,通过Druid的Kafka Index Service (简称KIS) 直接导入Druid。用户通过平台提供的Web向导配置,自动建立OLAP模型、查询统计条件,即可生产对应的实时报表。同时,平台也提供了如Ad-hoc分析、实时指标报警、实时数据发布、Grafana图表输出等功能,方便用户快速接入使用。
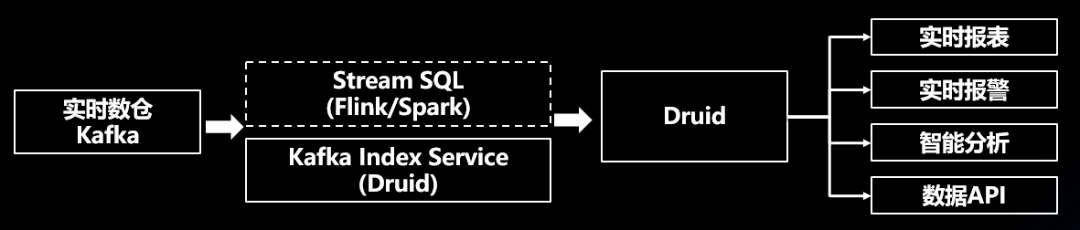
六、爱奇艺实时大数据的主要应用
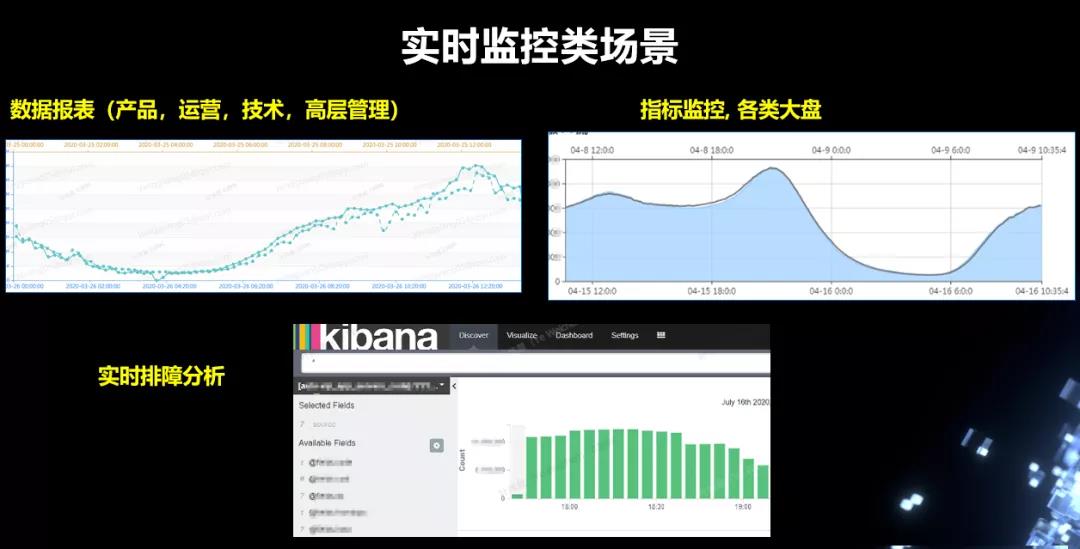
依托以上这些平台建设,实时大数据技术在爱奇艺各个业务线都实现了落地。主要有三种典型的应用场景,即实时监控、实时数据分析、在线学习训练等。
在实时监控场景中,用户可以依托实时大盘进行指标观察,或者将关键指标配置成实时监控报警,也可以将实时日志流灌入Elasticsearch等系统中进行实时日志查询等。
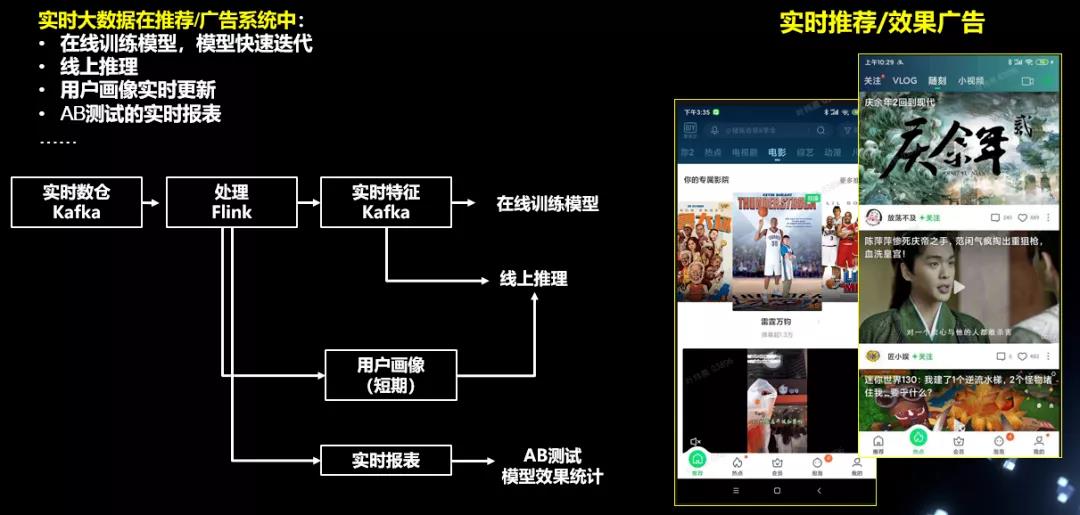
在实时数据分析场景中,比较典型的是实时运营。通过实时大数据体系,为运营部门提供更实时的运营效果数据,从而可以及时调整内容运营策略,进行流量资源再分配,助力用户增长。

除了BI报表和分析类场景外,实时数据在效果广告、信息流推荐等场景上也有大量落地,帮助推荐、广告等团队实现近线/在线机器学习、模型快速迭代、AB测试结果的实时观察统计等。
七、未来展望
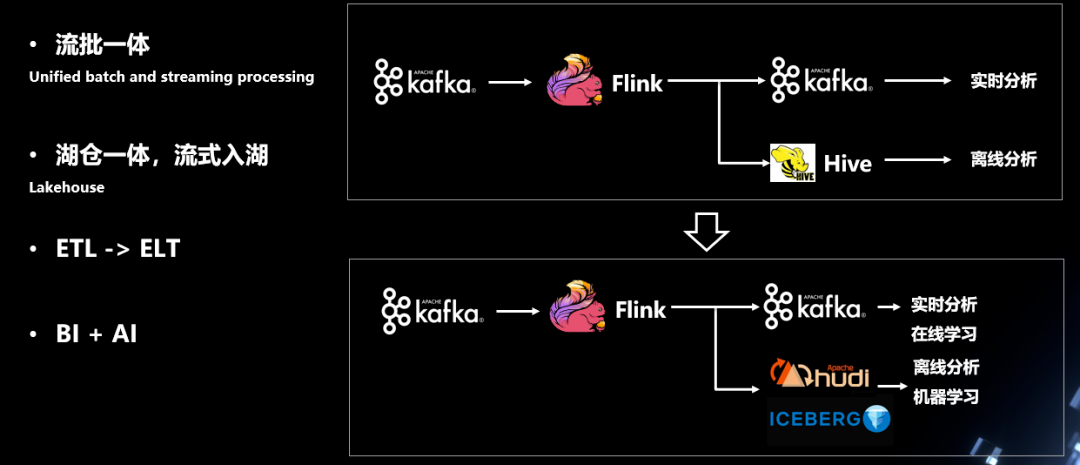
随着公司业务的发展,实时大数据的需求场景逐渐多样化,爱奇艺实时大数据体系会朝着以下几个方向继续迭代:
- 流批一体:在存储和计算两个方向上探索流批一体的应用场景,逐渐替代传统MapReduce/Spark离线任务的数仓构建,围绕Flink引擎构建流批一体的数仓体系。
- 湖仓一体:打通实时流灌入数据湖(Iceberg)的数据通路,依托实时更新的数据湖体系,支持更多更丰富的OLAP业务场景
- ETL->ELT:引导实时数仓的架构变迁,将实时数据构建环节中的部分计算转移到实时数仓下游的OLAP体系和数据湖中,依托OLAP引擎的强大性能来满足用户的过滤/聚合等需求,将实时数仓的链路做短,提升实时数据的质量和稳定性、降低延迟。
- BI+AI:打通实时数据生产->实时特征生产->在线模型训练->线上推理的链路,方便用户一站式的实现从数据准备到AI算法模型训练的相关工作。
毫无疑问,实时化一定是大数据未来最重要的方向之一。爱奇艺大数据团队会沿着上述这些方向继续探索和发展,通过技术创新去支持和孵化更多落地的业务场景,继续推动爱奇艺的数据和产品向着实时化的方向发展。