












今年 6 月,有一次大范围的全球知名网站宕机,国内的网民感知可能没那么强烈,但是在国外,很多知名网站都受到了波及。
图片来自 Pexels
本次大规模宕机时长长达一小时,受到影响的网站有谷歌、Twitter、亚马逊、eBay、Target、Reddit、PayPal、Square、Spotify、Twitch,还有《卫报》、《金融时报》、《独立报》、《纽约时报》、CNN、BBC、TechRadar等各大媒体网站。

01
当晚,网友们在访问这些网站的时候,网站都无法正常显示,会提示"Error 503 Service Unavailable"。甚至英国政府网站 gov.uk 同样中招!
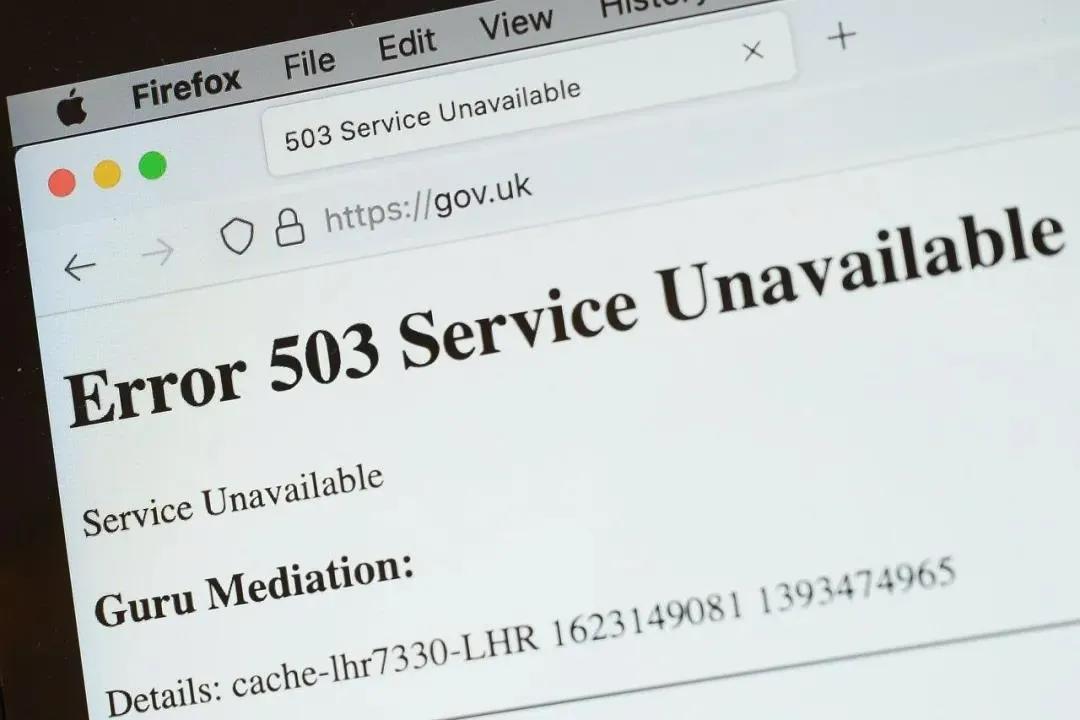
正在网民们猜测是什么原因导致众多大型网站集体宕机的时候,一家"名不见经传"的公司宣称本次大规模宕机可能和他们有关:“我们目前正在调查对我们的内容交付网络服务(Content Delivery Network)带来潜在影响的冲击。”
这家公司是一家名为 Fastly 的公司,他们的主营业务就是提供互联网内容传递服务。
他们主要的产品是边缘计算平台,其实就是提供内容分发网络(CDN)、网络安全服务、负载均衡及视频流等服务的。
因为很多公司要服务全球用户,全球用户想要访问他们的网站,都需要通过网络从他们的服务器上加载资源。
Fastly 就干了这么一件事儿,就是他提供了可以把服务器资源更近、更快的交付给终端用户的服务。
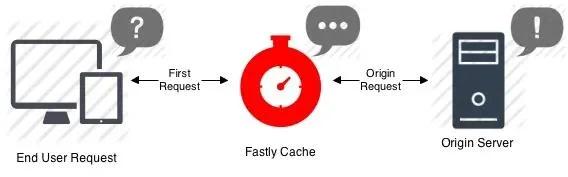
相当于把服务器上的资源预先加载到他们的 CDN 节点中,用户访问网站的时候,只需要从他们这里就可以获取到服务器资源了,不需要和远程服务器直接交互,大大缩短了时间。
02
美国太平洋时间 8 日凌晨 2:58 分,Fastly 表示全球大量网站断网和他们有关之后,人们开始具体故障原因。
很多人的第一想法是可能是受到了黑客攻击。甚至很多想象力丰富的朋友已经在脑海里上演了一出黑客攻防大戏了。
大约 1 小时之后,在美国太平洋时间 8 日凌晨 4:10 分,Fastly 表示他们已经找到了问题并且完成修复。
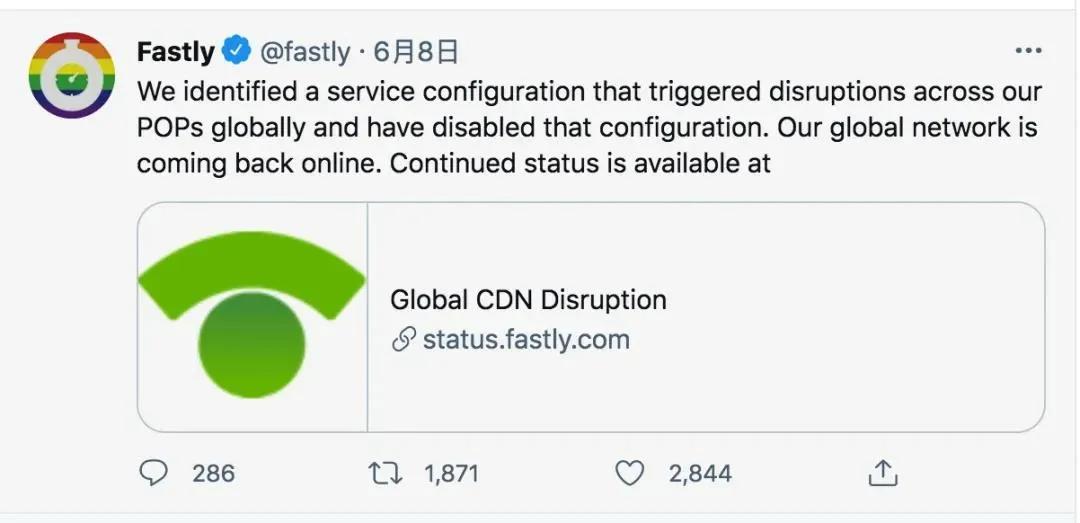
“我们发现一个服务配置的更改引发了全球服务的短暂中断,目前已将这一配置关闭,我们全球服务网络已恢复正常。”
服务器配置更改???这无论怎么看都是个低级错误。这个解释,显然让很多程序员们没办法接受,这么重要的系统,配置推送难道没有做灰度吗?
后来,据说这个配置错误最初是在 5 月份的一次发布时引入的,直到 6 月份才导致 Bug 触发。
在看到相关报道之后,我就在想,又要有程序员背锅了,这么大的影响,一定是个 P0 级故障了,这种故障,至少要有副总裁级别的人被 fire 掉吧?
但是,事情接下来的发展出乎了我的意料。
03
本以为这件事会以 Fastly 道歉赔偿、高管引咎辞职、程序员被开除收场。
但是,有一个有意思的现象发生了。当人们知道这次重大故障的主要责任方是 Fastly 时,这家公司的股价却在盘中大涨超过 10%。

因为,很多人发现,原来这个之前从来没听说过的公司,竟然和这么多大企业都有合作关系,竟然能有这么大的影响力。
而且,更让大家确认这家公司有前途的是,当天的故障,全球最大的云服务商 Amazon 也同样宕机了。所以….
这个事情一发生,让大家瞬间认识了一家叫做 Fastly 的公司。
04
这个事件,有几个事情是需要大家注意的:
- 边缘计算云服务现在的应用已经非常广泛了。
- 云服务商一旦出问题,那就一定是大问题。如何保证云服务的稳定性,是个长期的课题。
- 这么大的故障,可以在 1 小时左右发现、定位并解决,这家公司的效率已经算是很高了。
- 线上变更要谨慎!!!哪怕是一行配置!
最后,本文内容,不构成任何投资建议!!!
出处:转载自公众号码出未来





















